使用python批量爬取wallhaven.cc壁纸站壁纸
偶然发现https://wallhaven.cc/这个壁纸站的壁纸还不错,尤其是更新比较频繁,用python写个脚本爬取
点latest,按照更新先后排序,获得新地址,发现地址是分页展示的,每一页24张
本案例使用xpath爬虫爬取数据,先分析网页,使用浏览器查看元素工具,快速定位到图片元素所在位置,且存在规律性
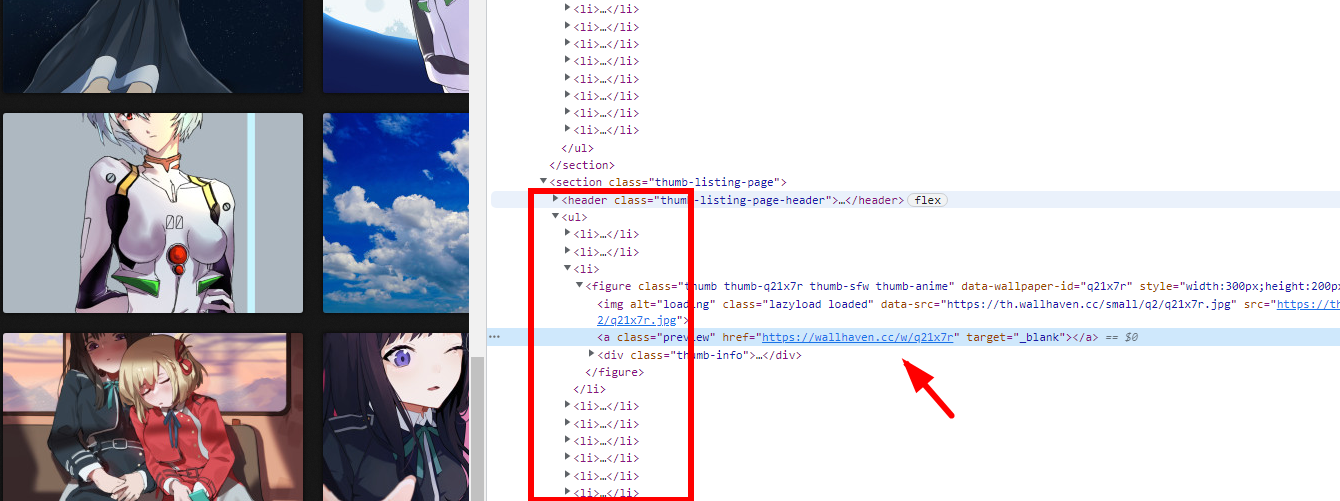
首先爬取一级页面获取图片页面地址(点了上图箭头的地址会打开图片详细页,并非图片真实地址),xpath提取数据的代码如下
html = requests.get(url=url1, headers=headers, timeout=5.0).text
data = etree.HTML(html)
li_list = data.xpath('.//div[@id="thumbs"]//@href')
执行后爬取出一连串的地址信息

对里面包含“latest”的地址进行剔除,这个地址非图片地址,然后再循环请求图片地址,获取真实图片地址
for li in li_list:
if 'latest' in li:
continue
else:
html_li = requests.get(url=li, headers=headers, timeout=5.0).text
data = etree.HTML(html_li)
li_add = data.xpath('//*[@id="wallpaper"]//@src')
li_add = li_add[0]
print(li_add)
执行后输出真实图片地址
把这些地址写到一个txt文本内,然后通过迅雷去下载,效率会高一些,当然也可以爬取后执行使用python下载,单线程下蛮久的。先上保存到txt内的全部代码
# -*- codeing = utf-8 -*- import requests
from lxml import etree
import time
import random
import time def getBZ(): url='https://wallhaven.cc/latest?page={}' # 翻页10页
for page in range(1, 10): headers = {
# 'referer': 'https://wallhaven.cc/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
print(time.strftime("%H:%M:%S")) print("第{}页".format(page)) url1 = url.format(page)
print(url1)
# 一级页面请求
html = requests.get(url=url1, headers=headers).text
data = etree.HTML(html)
li_list = data.xpath('.//div[@id="thumbs"]//@href')
for li in li_list:
if 'latest' in li or 'top'in li:
continue
else:
print(li)
html_li = requests.get(url=li, headers=headers)
print(html_li.status_code)
if html_li.status_code == 404 or html_li.status_code == 429:#判断,如果响应失败跳过这次数据抓取
continue
else:
data = etree.HTML(html_li.text)
li_add = data.xpath('//*[@id="wallpaper"]//@src')
li_add = li_add[0]
with open('1538.txt', 'a',encoding='utf-8') as w:
w.write(li_add+'\n')
w.close()
b = random.randint(1,2)#随机从1到2内取一个整数值
print("等待"+str(b)+"秒")
time.sleep(b)#把随机取出的整数值传到等待函数中
getBZ()
使用python批量爬取wallhaven.cc壁纸站壁纸的更多相关文章
- 从0实现python批量爬取p站插画
一.本文编写缘由 很久没有写过爬虫,已经忘得差不多了.以爬取p站图片为着手点,进行爬虫复习与实践. 欢迎学习Python的小伙伴可以加我扣群86七06七945,大家一起学习讨论 二.获取网页源码 爬取 ...
- python 批量爬取四级成绩单
使用本文爬取成绩大致有几个步骤:1.提取表格(或其他格式文件——含有姓名,身份证等信息)中的数据,为进行准考证爬取做准备.2.下载准考证文件并提取出准考证和姓名信息.3.根据得到信息进行数据分析和存储 ...
- python批量爬取动漫免费看!!
实现效果 运行环境 IDE VS2019 Python3.7 Chrome.ChromeDriver Chrome和ChromeDriver的版本需要相互对应 先上代码,代码非常简短,包含空行也才50 ...
- 用Python批量爬取优质ip代理
前言 有时候爬的次数太多时ip容易被禁,所以需要ip代理的帮助.今天爬的思路是:到云代理获取大量ip代理,逐个检测,将超时不可用的代理排除,留下优质的ip代理. 一.爬虫分析 首先看看今天要爬取的网址 ...
- python 批量爬取代理ip
import urllib.request import re import time import random def getResponse(url): req = urllib.request ...
- Python批量爬取谷歌原图,2021年最新可用版
文章目录 前言 一.环境配置 1.安装selenium 2.使用正确的谷歌浏览器驱动 二.使用步骤 1.加载chromedriver.exe 2.设置是否开启可视化界面 3.输入关键词.下载图片数.图 ...
- python批量爬取文档
最近项目需要将批量链接中的pdf文档爬下来处理,根据以下步骤完成了任务: 将批量下载链接copy到text中,每行1个链接: 再读txt文档构造url_list列表,利用readlines返回以行为单 ...
- python批量爬取猫咪图片
不多说直接上代码 首先需要安装需要的库,安装命令如下 pip install BeautifulSoup pip install requests pip install urllib pip ins ...
- 使用Python批量爬取美女图片
运行截图 实列代码: from bs4 import BeautifulSoup import requests,re,os headers = { 'User-Agent': 'Mozilla/5. ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
随机推荐
- LESLIE NOTE ——你的笔记只属于你自己
LESLIE NOTE 网站:http://www.leslienote.com 简介: [只有数据可控,才是最放心的] [只有多多备份,才是最安全的] LESLIE NOTE 是一款本地笔记软件, ...
- AVX512
最近接触到SIMD编码,就不可避免的查到了AVX指令集,两者有什么关系呢,了解一下? 问:AVX是什么? 答:是一套指令集 下面具体看: AVX 以下内容主要转载自:AVX指令集是什么?它的应用又有哪 ...
- DCT实现水印嵌入与提取(带攻击)
问题: 想要用DCT技术,在Matlib上实现水印的隐藏和提取(带GUI界面),且加上一些攻击(噪声.旋转.裁剪),以及用NC值评判! 流程 选择载体 [filename,pathname]=uige ...
- 从0到1构建开源 vue-uniapp-template:使用 UniApp + Vue3 + TypeScript 和 VSCoe、CLI 开发跨平台移动端脚手架
作者主页: 有来技术 开源项目: youlai-mall︱vue3-element-admin︱youlai-boot︱vue-uniapp-template 仓库主页: GitCode︱ Gitee ...
- Windows中利用任务计划执行进程守护
在Windows中除了开发专用的进程守护外,还可以利用任务计划做进程守护. 一.bat示例 tasklist | findstr "notepad" if %ERRORLEVEL% ...
- uni-app中使用uView组件库
01通过npm的方式安装uView组件库 uView依赖SCSS,您必须要安装此插件,否则无法正常运行. 如果您的项目是由HBuilder X创建的, 相信已经安装scss插件, 如果没有,请在HX菜 ...
- Linux docker 的安装及使用
Docker 有两个版本: 社区版(Community Edition,缩写为 CE) 企业版(Enterprise Edition,缩写为 EE) 检查环境 # 系统内核需要 3.10 以上 una ...
- linux安装wps
1. http://wps-community.org/downloads 下载 wps-office_10.1.0.5672~a21_i386.deb ...
- docker官网镜像无法下载问题解决
亲测可用,这个方法是由技术爬爬虾大佬提供,简单地说就是通过github上的docker_image_pusher项目,将国外docker镜像转存到阿里云私人仓库. 此方法需要你有一个github账号, ...
- FreeSql学习笔记——8.数据返回类型
前言 FreeSql数据返回格式比较丰富,包括单条.列表.导航属性数据.指定字段.Dto等:可以有效的减少代码量,减少字段复制等操作: 前面的查询已经用到了日常基本需要用到的数据格式,本篇是常 ...