kafka数据同步到mysql
本文分享自天翼云开发者社区《kafka数据同步到mysql》,作者:刘****猛
kafka安装
使用docker-compose进行安装,docker-compose文件如下:
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
networks:
proxy:
ipv4_address: 172.16.0.8
kafka:
image: wurstmeister/kafka:latest
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.183.142
KAFKA_CREATE_TOPICS: "test:1:1"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
networks:
proxy:
ipv4_address: 172.16.0.9
networks:
proxy:
ipam:
config:
- subnet: 172.16.0.0/24这样安装的kakfa是没有密码的,下面为kafka配置密码
先将kafka的配置文件映射到本机目录
docker cp 277:/opt/kafka/config /root/docker-build/kafka/config/
docker cp 277:/opt/kafka/bin /root/docker-build/kafka/bin/添加密码
然后将容器删除
docker-compose down修改config目录下的server.properties
############################# Server Basics #############################
broker.id=-1
listeners=SASL_PLAINTEXT://192.168.183.137:9092
advertised.listeners=SASL_PLAINTEXT://192.168.183.137:9092
security.inter.broker.protocol=SASL_PLAINTEXT
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN
authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer修改bin目录下的kafka-server-start.sh文件,修改如下
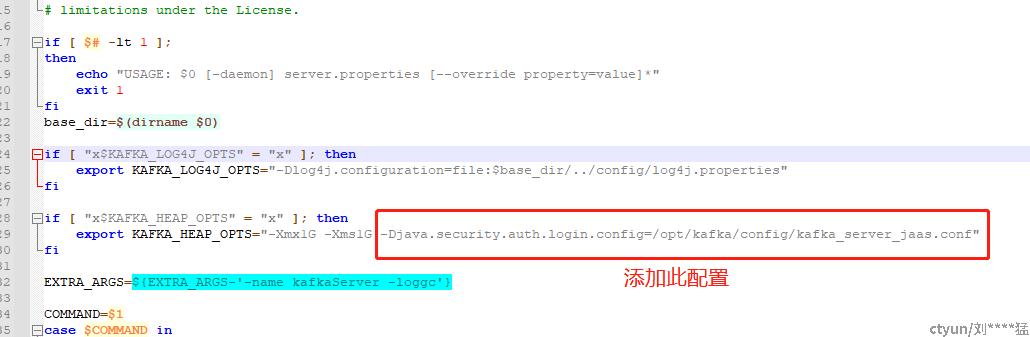
重新启动kafka,修改docker-compose.yml文件如下
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
networks:
proxy:
ipv4_address: 172.16.0.8
kafka:
image: wurstmeister/kafka:latest
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.183.142
KAFKA_CREATE_TOPICS: "test:1:1"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- ./config:/opt/kafka/config
- ./bin:/opt/kafka/bin
networks:
proxy:
ipv4_address: 172.16.0.9
networks:
proxy:
ipam:
config:
- subnet: 172.16.0.0/24启动容器
docker-compose up -d
这样把kafka启动起来
测试步骤
在sp中启动任务
sql脚本
create table goods_source (
goods_id int,
goods_price decimal(8,2),
goods_name varchar,
goods_details varchar
) WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = '101.43.164.4:9092',
'topic' = 'test_kafka',
'properties.group.id' = 'test-consumer-group-1',
'properties.security.protocol' = 'SASL_PLAINTEXT',
'properties.sasl.mechanism' = 'PLAIN',
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="******";',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
create table goods_target (
goods_id int,
goods_price decimal(8,2),
goods_name varchar,
goods_details varchar,
PRIMARY KEY (`goods_id`) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://101.43.164.4:3306/cdc-sink?useSSL=false&characterEncoding=utf-8',
'table-name' = 'my_goods_kafka',
'username' = 'root',
'password' = '******'
);
insert into
goods_target
select
*
from
goods_source;然后写代码,推送十条数据
这里是java写的推送,仅供参考
@Test
public void test1() throws ExecutionException, InterruptedException {
for (int i = 10; i <= 20; i++) {
CdcTestGoods cdcTestGoods = new CdcTestGoods();
cdcTestGoods.setGoods_id(5 + i);
cdcTestGoods.setGoods_name("iphone 14 pro max 128G " + i);
cdcTestGoods.setGoods_details("京东618大降价,买到就是赚 " + i);
cdcTestGoods.setGoods_price(5899f);
SendResult<String, String> result = kafkaTemplate.send("test_kafka", JacksonUtils.getString(cdcTestGoods)).get();
log.info("sendMessageSync => {},message: {}", result, JacksonUtils.getString(cdcTestGoods));
}
}查看mysql表,出现相关内容,kafaka只支持insert 不支持update
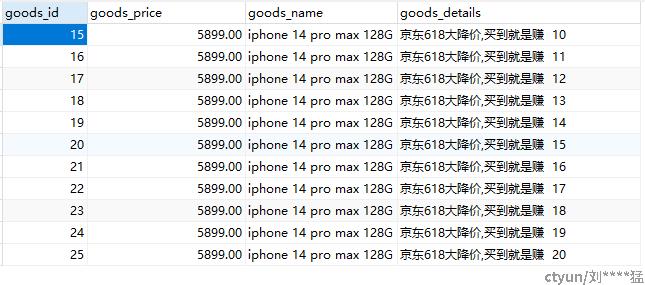
kafka数据同步到mysql的更多相关文章
- SparkStreaming直连方式读取kafka数据,使用MySQL保存偏移量
SparkStreaming直连方式读取kafka数据,使用MySQL保存偏移量 1. ScalikeJDBC 2.配置文件 3.导入依赖的jar包 4.源码测试 通过MySQL保存kafka的偏移量 ...
- Canal - 数据同步 - 阿里巴巴 MySQL binlog 增量订阅&消费组件
背景 早期,阿里巴巴 B2B 公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求 ,主要是基于trigger的方式获取增量变更.从 2010 年开始,公司开始逐步尝试数据库日志解析,获取增量变 ...
- 043 hive数据同步到mysql
一:意义 1.意义 如果可以实现这个功能,就可以使用spark代替sqoop,功能程序就实现这个功能. 二:hive操作 1.准备数据 启动hive 否则报错,因为在hive与spark集成的时候,配 ...
- ODBC数据管理器 SqlServer实时数据同步到MySql
---安装安装mysqlconnector http://www.mysql.com/products/connector/ /* 配置mysqlconnector ODBC数据管理器->系统D ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第一篇:Debezium实现Mysql到Elasticsearch高效实时同步
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484358&idx=1&sn=3a78347 ...
- Kafka数据如何同步至MaxCompute之实践讲解
摘要:本次分享主要介绍Kafka产品的原理和使用方式,以及同步数据到MaxCompute的参数介绍.独享集成资源组与自定义资源组的使用背景和配置方式.Kafka同步数据到MaxCompute的开发到生 ...
- canal数据同步
前面提到数据库缓存不一致的几种解决方案,但是在不同的场景下各有利弊,而今天我们使用的canal进行缓存与数据同步的方案是最好的,但是也有一个缺点,就是相对前面几种解决方案会引入阿里巴巴的canal组件 ...
- canal+mysql+kafka实时数据同步安装、配置
canal+mysql+kafka安装配置 概述 简介 canal译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费. 基于日志增量订阅和消费的业务包括 数 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第三篇:logstash_output_kafka:Mysql同步Kafka深入详解
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484411&idx=1&sn=1f5a371 ...
- 转载:MySQL和Redis 数据同步解决方案整理
from: http://blog.csdn.net/langzi7758521/article/details/52611910 最近在做一个Redis箱格信息数据同步到数据库Mysql的功能. 自 ...
随机推荐
- 利用 Kubernetes 降本增效?EasyMR 基于 Kubernetes 部署的探索实践
Kubernetes 是用于编排容器化应用程序的云原生系统.最初由 Google 创建,如今由 Cloud Native Computing Foundation(CNCF)维护更新. Kuberne ...
- vs 中有日文代码或者乱七八糟的语言导致的乱七八糟的错误 解决方案
简介 用外国人的库,在vs上编译经常会出现一大堆因为注释导致的问题,有的时候就算你把注释都删了,也会有很多问题,那么如何解决呢? vs 打开高级保存选项 https://jingyan.baidu.c ...
- iPaaS 与 API 管理:企业数字化转型的双引擎
一.企业集成的残酷现实 根据IDC 2024 年数字化转型报调研显示:大中型企业平均部署数十至数百个业务系统,涵盖 ERP.CRM.SaaS 应用及物联网平台等,但仅约 30% 的系统实现标准化集成. ...
- 谷云科技RestCloud全面接入DeepSeek 开启智能新时代
在数字化转型的浪潮中,谷云科技始终走在数据集成与智能应用领域的前沿.近期,随着 DeepSeek 的火爆出圈,谷云科技紧跟技术趋势,对旗下两大核心产品 -- 数据集成软件 ETLCloud 和 AI ...
- Phenomenon•Observation•Uncertainty/Certainty•Statistical law•Random phenomenon•Theory of Probability
Mathematics: the logic of certainty. Statistics: the logic of uncertainty. Certainty/Uncertainty: Ph ...
- SciTech-BigDataAIML-Tensorflow-Introduction to Gradients and Automatic Differentiation
In this guide, you will explore ways to compute gradients with TensorFlow, especially in eager execu ...
- SciTech-Mathematics-Probability+Statistics-7 Steps to Mastering Statistics for Data Science
7 Steps to Mastering Statistics for Data Science BY BALA PRIYA CPOSTED ON JULY 19, 2024 A strong fou ...
- spring-ai 学习系列(1)-调用本地ollama
spring-ai框架为java程序员快速融入AI大潮提供了便利,下面演示如何调用本地deepseek模型 一.安装ollama https://www.ollama.com/ 首页下载安装即可 选择 ...
- flink 1.11.2 学习笔记(3)-统计窗口window
接上节继续,通常在做数据分析时需要指定时间范围,比如:"每天凌晨1点统计前一天的订单量" 或者 "每个整点统计前24小时的总发货量".这个统计时间段,就称为统计 ...
- PACS实施基础知识