朴素贝叶斯算法的python实现
朴素贝叶斯
算法优缺点
优点:在数据较少的情况下依然有效,可以处理多类别问题
缺点:对输入数据的准备方式敏感
适用数据类型:标称型数据
算法思想:
朴素贝叶斯
比如我们想判断一个邮件是不是垃圾邮件,那么我们知道的是这个邮件中的词的分布,那么我们还要知道:垃圾邮件中某些词的出现是多少,就可以利用贝叶斯定理得到。
朴素贝叶斯分类器中的一个假设是:每个特征同等重要
函数
loadDataSet()
创建数据集,这里的数据集是已经拆分好的单词组成的句子,表示的是某论坛的用户评论,标签1表示这个是骂人的
createVocabList(dataSet)
找出这些句子中总共有多少单词,以确定我们词向量的大小
setOfWords2Vec(vocabList, inputSet)
将句子根据其中的单词转成向量,这里用的是伯努利模型,即只考虑这个单词是否存在
bagOfWords2VecMN(vocabList, inputSet)
这个是将句子转成向量的另一种模型,多项式模型,考虑某个词的出现次数
trainNB0(trainMatrix,trainCatergory)
计算P(i)和P(w[i]|C[1])和P(w[i]|C[0]),这里有两个技巧,一个是开始的分子分母没有全部初始化为0是为了防止其中一个的概率为0导致整体为0,另一个是后面乘用对数防止因为精度问题结果为0
classifyNB(vec2Classify, p0Vec, p1Vec, pClass1)
根据贝叶斯公式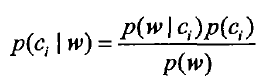 计算这个向量属于两个集合中哪个的概率高
计算这个向量属于两个集合中哪个的概率高
#coding=utf-8
from numpy import *
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not
return postingList,classVec #创建一个带有所有单词的列表
def createVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document)
return list(vocabSet) def setOfWords2Vec(vocabList, inputSet):
retVocabList = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
retVocabList[vocabList.index(word)] = 1
else:
print 'word ',word ,'not in dict'
return retVocabList #另一种模型
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec def trainNB0(trainMatrix,trainCatergory):
numTrainDoc = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCatergory)/float(numTrainDoc)
#防止多个概率的成绩当中的一个为0
p0Num = ones(numWords)
p1Num = ones(numWords)
p0Denom = 2.0
p1Denom = 2.0
for i in range(numTrainDoc):
if trainCatergory[i] == 1:
p1Num +=trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num +=trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom)#处于精度的考虑,否则很可能到限归零
p0Vect = log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0 def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)
testEntry = ['stupid', 'garbage']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb) def main():
testingNB() if __name__ == '__main__':
main()机器学习笔记索引
朴素贝叶斯算法的python实现的更多相关文章
- 朴素贝叶斯算法的python实现方法
朴素贝叶斯算法的python实现方法 本文实例讲述了朴素贝叶斯算法的python实现方法.分享给大家供大家参考.具体实现方法如下: 朴素贝叶斯算法优缺点 优点:在数据较少的情况下依然有效,可以处理多类 ...
- 朴素贝叶斯算法的python实现-乾颐堂
算法优缺点 优点:在数据较少的情况下依然有效,可以处理多类别问题 缺点:对输入数据的准备方式敏感 适用数据类型:标称型数据 算法思想: 朴素贝叶斯 比如我们想判断一个邮件是不是垃圾邮件,那么我们知道的 ...
- 朴素贝叶斯算法的python实现 -- 机器学习实战
import numpy as np import re #词表到向量的转换函数 def loadDataSet(): postingList = [['my', 'dog', 'has', 'fle ...
- 朴素贝叶斯算法--python实现
朴素贝叶斯算法要理解一下基础: [朴素:特征条件独立 贝叶斯:基于贝叶斯定理] 1朴素贝叶斯的概念[联合概率分布.先验概率.条件概率**.全概率公式][条件独立性假设.] 极大似然估计 ...
- 朴素贝叶斯算法原理及Spark MLlib实例(Scala/Java/Python)
朴素贝叶斯 算法介绍: 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法. 朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,在没有其它可用信息下,我 ...
- 机器学习:python中如何使用朴素贝叶斯算法
这里再重复一下标题为什么是"使用"而不是"实现": 首先,专业人士提供的算法比我们自己写的算法无论是效率还是正确率上都要高. 其次,对于数学不好的人来说,为了实 ...
- Python机器学习笔记:朴素贝叶斯算法
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法.对于大多数的分类算法,在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同.比如决策树,KNN,逻辑回归,支持向 ...
- Python机器学习算法 — 朴素贝叶斯算法(Naive Bayes)
朴素贝叶斯算法 -- 简介 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法.最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Baye ...
- 机器学习---用python实现朴素贝叶斯算法(Machine Learning Naive Bayes Algorithm Application)
在<机器学习---朴素贝叶斯分类器(Machine Learning Naive Bayes Classifier)>一文中,我们介绍了朴素贝叶斯分类器的原理.现在,让我们来实践一下. 在 ...
随机推荐
- Nginx基本使用
Nginx基本使用 下载源码包http://nginx.org/ http://nginx.org/en/download.html yum -y install pcre-devel openssl ...
- Alpha阶段第九次Scrum Meeting
情况简述 Alpha阶段第九次Scrum Meeting 敏捷开发起始时间 2016/11/2 00:00 敏捷开发终止时间 2016/11/3 00:00 会议基本内容摘要 汇报进度,安排工作 参与 ...
- 用File判断D盘下面是否还有txt文件
package cn.idcast; import java.io.File; public class File1 { public static void main(String[] args) ...
- php 做数学运算时结果为0的原因
php是一种弱类型的脚本语言,一般情况下字符串型的数字可以直接参与运算. 但是当字符串开头是实体空格的时候系统会默认字符串等于0. 此问题比较隐蔽,在此记录下
- javascript数据结构与算法--高级排序算法
javascript数据结构与算法--高级排序算法 高级排序算法是处理大型数据集的最高效排序算法,它是处理的数据集可以达到上百万个元素,而不仅仅是几百个或者几千个.现在我们来学习下2种高级排序算法-- ...
- T-SQL备忘-表连接更新
1.update a inner join b on a.id=b.id set a.name=b.name where ... 2.update table1 set a.name = b.na ...
- ASP.NET Core--基于授权的资源
翻译如下: 通常授权取决于正在访问的资源. 例如,文档可以具有作者属性. 将只允许文档作者对其进行更新,因此必须在进行授权评估之前从文档存储库加载资源. 这不能使用Authorize属性来完成,因为属 ...
- .NET导入导出Excel方法总结
最近,应项目的需求,需要实现Excel的导入导出功能,对于Web架构的Excel导入导出功能,比较传统的实现方式是: 1)导入Excel:将Excel文件上传到服务器的某一文件夹下,然后在服务端完成E ...
- poj 1239
二次dp,还算好想. 先第一遍dp找出最后一个数字最小是几. dpf[i]=max{j}+1(dpf[j],dpf[j]+1,…,j位组成的数字小于j+1,j+2,…,i位组成的数字. 在第二遍dp, ...
- rabbitmq 的心跳机制&应用
官方文档说: If a consumer dies (its channel is closed, connection is closed, or TCP connection is lost) w ...