隐马尔可夫模型HMM
隐马尔可夫模型HMM的探究
1.1 定义
1.2 观测序列生成过程
1.3 HMM的三个问题
2 概率计算算法
2.1 直接计算算法
2.2 前向算法forward algorithm
2.3 后向算法
2.4 一些概率与期望值的计算
3 学习算法
3.1 监督学习
3.2 非监督学习——Baum-Welch算法
3.3 Baum-Welch模型参数估计公式
4 预测算法
4.1 近似算法
4.2 维特比算法Viterbi algorithm
隐马尔可夫模型(hidden Markov model,HMM)是可用于标注问题的统计学习模型,描述由隐藏马尔科夫链随机生成的观测序列的过程,属于生成模型。在语音识别,自然语言处理,生物信息,模式识别有广泛的应用。
1 HMM基本概念
1.1 定义
马尔可夫链的定义:随机过程中出现的字符,每个字符出现的概率不是独立的而是依赖于此前的状态,称为——。与之相对应的是独立链,即每个字符出现的概率是独立的。
参考链接:马尔可夫和马尔可夫链
HMM是关于时序的概率模型,描述由一个隐藏的马尔科夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测随机序列的过程。隐藏的马尔可夫链随机生成的状态的序列称为状态序列(state sequence)。每个状态生成一个观测,由此产生的观测的随机序列称为观测序列(observation sequence)。序列的每个位置可以看做是一个时刻。
很多术语:
设Q是所有可能状态的集合,V是所有可能观测的集合。Q={q1,q2,…,qN},V={v1,v2,…,vM}, N是可能的状态数,M是可能的观测数。
I是长度为T的状态序列,O是对应的观测序列,I=(i1,i2,…,iT),O=(ν1,ν2,…,νT)
A是状态转移概率矩阵,A=[aij]NXN,αij=P(it+1=qj|it=qi),i=1,2,..,N;j=1,2,..N,表明时刻t处于状态qi的条件下t+1转移状态的概率qj。
更好的理解状态转移概率:知乎PHD-Tasi的回答 
B是观测概率矩阵,B=[bj(k)]NXM,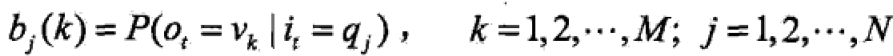 表明时刻t处于状态qj条件下生成的观测νk的概率。
表明时刻t处于状态qj条件下生成的观测νk的概率。
π是初始状态向量,π=(πi),其中,πi=P(i1=qi),i=1,2…,N表示时刻t=1时处于状态qi的概率。
HMM由初始状态概率向量π,状态转移概率矩阵A和观测概率矩阵B决定,π和A决定状态序列,B决定观测序列,因此HMM用λ的三元符号表示为:λ=(A,B,π),称为HMM的三要素。
从定义出发,发现HMM作了两个基本假设:
- 齐次马尔可夫假设:隐藏的马尔可夫链在任意时刻t的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻t无关。
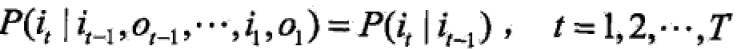
- 观测独立性假设:假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关。
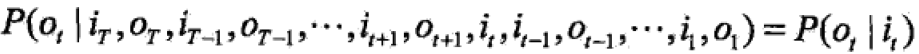
HMM可用于标注,这时状态对应着标记,标注问题是给定观测的序列与其对应的标记序列。假设标注问题的数据由HMM生成,这样可用HMM的学习与预测算法进行标注。
1.2 观测序列生成过程
算法: 
1.3 HMM的三个问题
- 概率计算的问题:给定模型λ=(A,B,π)和观测序列O=(o1,o2,…,ot),计算在模型λ下观测序列O出现的概率P(O|λ)。
- 学习问题:已知观测序列O=(o1,o2,…,oT),估计模型λ=(A,B,π)参数,使得在该模型下观测序列的概率P(O|λ)最大,即用极大似然估计方法估计参数。
- 预测问题:也称解码(decoding),已知模型λ=(A,B,π)和观测序列O,求对给定观测序列条件概率P(I|O)最大的状态序列I。即给定观测序列求最有可能的对应的状态序列。
2 概率计算算法
计算观测序列的概率的算法。
2.1 直接计算算法
给定模型λ=(A,B,π)和观测序列O=(o1,o2,…oT),计算观测序列O出现的概率P(O|λ)。最直接的方法是按照概率公式直接计算。通过列举所有可能的长度为T的状态序列I=(i1,i2,…,iT),求各个状态序列I与观测序列O的联合概率P(O,I|λ),然后对所有可能的状态序列求和(边缘概率)得到P(O|λ)。
状态序列I的概率是: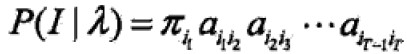
对固定状态序列I,观测序列O的概率是:
O,I同时出现的联合概率为: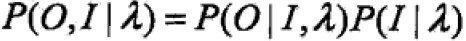

然后对所有可能的状态I求和得到要求的概率: 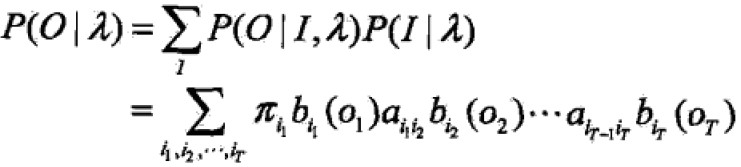
但是计算量极大,是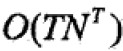 阶的。
阶的。
2.2 前向算法forward algorithm
前向概率:给定HMM模型λ,定义到时刻t部分观测序列为o1,o2,…,oT且状态为qi的概率为—— 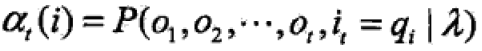
可以递推的求前向概率及观测概率P(O|λ)。
算法: 

步骤1中,初始化前向概率,是初始时刻的状态i1=qi和观测o1的联合概率;
步骤2中,是前向概率的递推公式,计算到时刻t+1部分观测序列为o1,o2,…,ot+1且时刻t+1处于状态qi的前向概率;
步骤3中,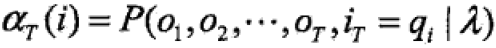 ,所有求和,这里和上面直接求解的加和一个意思。
,所有求和,这里和上面直接求解的加和一个意思。
2.3 后向算法
后向概率:给定HMM的λ,定义时刻t状态为qi的条件下,从t+1到T的部分观测序列为ot+1,… ,oT,称为—— 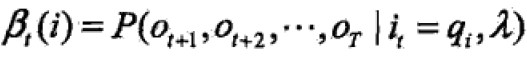
同样用递推的方法来求。
算法: 
因为前向算法和后向算法思路是一致的,所以统一写成: 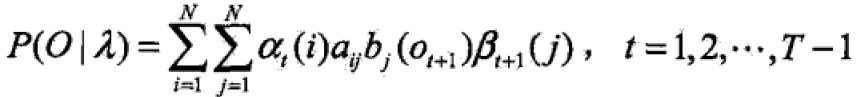
2.4 一些概率与期望值的计算
利用前向,后向概率可以得到单个状态和两个状态概率的计算公式。
- 给定模型λ和观测O,在时刻t处于状态qi的概率:

由前向概率可得: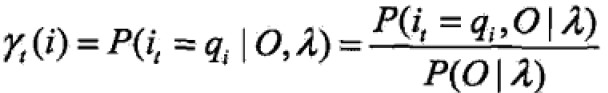
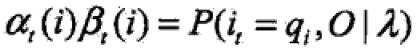
于是,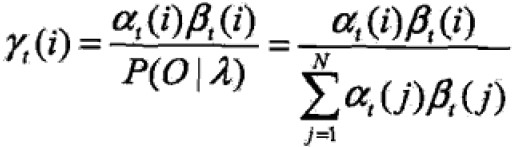
- 给定模型λ和观测O,在时刻t处于状态qi且在时刻t+1处于状态qj的概率为:
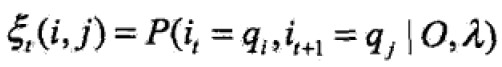
由前向后向概率可得:
而
因此,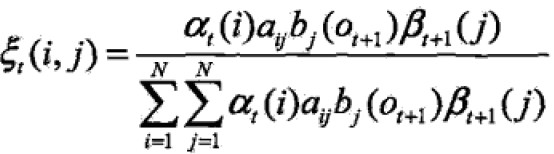
- 将1,2结合可对各个时刻t求和,得到一些有用的期望值
- 观测O下状态i出现的期望值:
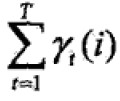 ;
; - 观测O下状态i转移的期望值:
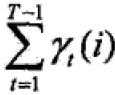 ;
; - 观测O下状态i转移到j的期望值:
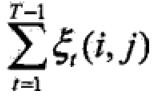
3 学习算法
根据训练数据是包括观测序列和对应状态序列还是只有观测序列分为监督学和非监督学习实现。
3.1 监督学习
假设已知训练数据包含S个长度相同的观测序列和对应的状态序列{(O1,I1),(O2,I2),……,(Os,Is)},那么就可以利用极大似然估计来估计HMM的参数。具体方法如下,
- 转移概率aij的估计
设样本中时刻t处于状态i,时刻t+1转移到状态j的频数为Aij,那么转移状态概率估计为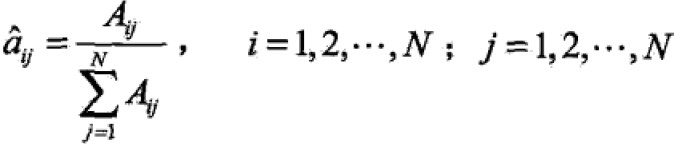
- 观测概率bj(k)的估计
设样本中状态为j并观测为k的频数为Bjk,那么状态为j观测为k的概率为估计为
- 初始状态概率πi的估计πi hat 为S个样本中初始状态为qi的频率
由于监督学习的算法需要训练数据,而人工标注的代价很大,所以有时候需要非监督学习的方法,如下节。
3.2 非监督学习——Baum-Welch算法
假设给定训练数据只包含S个,长度为T的观测序列{O1,O2,…,Os}而没对应的状态序列,目标是学习HMM的λ=(A,B,π)的参数。将观测序列看做测试数据O,状态序列数据看做不可观测的隐数据I,实际上HMM是一个含有隐变量的概率模型: 可以由EM算法实现。
可以由EM算法实现。
更新一个链接:EM算法的介绍
- 确定完全数据的对数似然函数
所有观测数据写成O=(o1,o2,…,oT),所有隐数据写成I=(i1,i2,…,iT),完全数据是(O,I)=(o1,o2,…,oT,i1,i2,…,iT),完全数据的对数似然函数是 。
。 - EM算法的E步:求Q函数
其中, 是HMM当前参数的估计值,λ是要极大化的HMM参数。
是HMM当前参数的估计值,λ是要极大化的HMM参数。 
那么Q函数可化为: 求和是因为对所有序列总长度为T的训练数据上进行的。
求和是因为对所有序列总长度为T的训练数据上进行的。 - EM算法的M步:极大化Q函数求模型参数A,B,π
观察Q函数最后的化简结果可发现,三个参数分别单独出现在三项中,故只需对三项分别极大化。
第一项: ,πi的约束条件是
,πi的约束条件是 ,利用拉格朗日乘数法,写出拉格朗日函数:
,利用拉格朗日乘数法,写出拉格朗日函数:  求偏导并令结果为0,得
求偏导并令结果为0,得  ==>
==>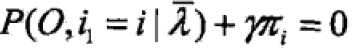
对i求和,得到γ,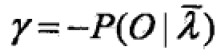
回代得到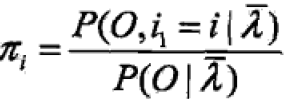 ;
;
第二项: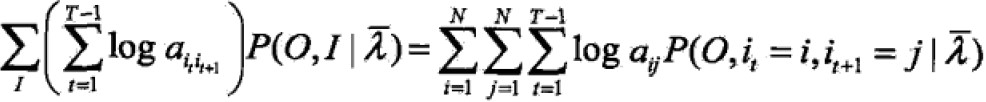 ,类似第一项约束条件
,类似第一项约束条件 ,利用拉格朗日乘数法求得:
,利用拉格朗日乘数法求得: 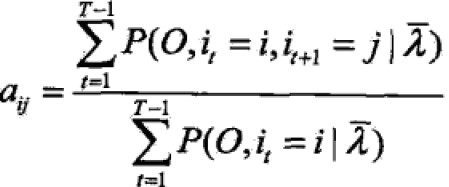
第三项: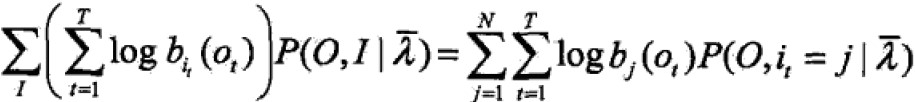 ,约束条件
,约束条件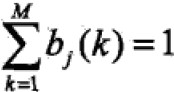 ,利用拉格朗日乘数法,得到:
,利用拉格朗日乘数法,得到: 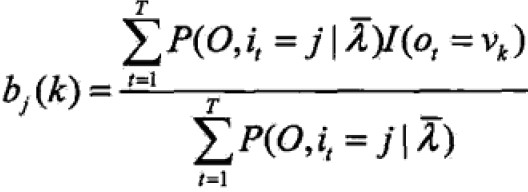
注意:只有在ot=νk时,bj(ot)对bj(k)的偏导才不为0,以I(ot=νk)表示。
3.3 Baum-Welch模型参数估计公式
三个公式: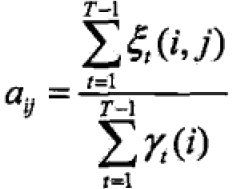 ;
;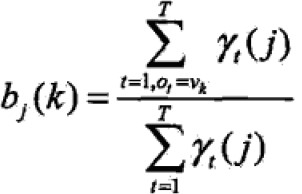 ;
; ;
;
BW算法: 

4 预测算法
这是HMM最后一个问题:已知模型λ=(A,B,π)和观测序列O,求对给定观测序列条件概率P(I|O)最大的状态序列I。即给定观测序列求最有可能的对应的状态序列。
4.1 近似算法
思想是:在每个时刻t选择在该时刻最有可能出现的状态it从而得到一个状态序列 ,将它作为预测结果。
,将它作为预测结果。
给定HMM的λ和观测序列O,在此时刻t处于状态qi的概率为: 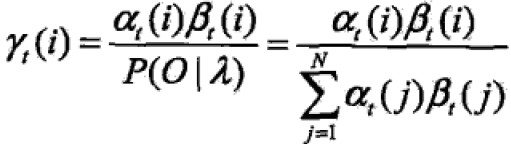
每一时刻最有可能的状态是 ,从而得到状态序列I。
,从而得到状态序列I。
近似算法的优点是计算简单,缺点是不能保证预测的状态序列整体上是最有可能的状态序列,因为预测的状态序列可能实际有不发生的部分。此方法得到的序列有可能存在转移概率为0的相邻状态。
4.2 维特比算法Viterbi algorithm
实际上是运用动态规划(dynamic programming)求解HMM问题。即动态规划求概率最大路径(最优路径)。这时一条路径对应一个状态序列。
什么是动态规划
根据动态规划原理,最优路径特性:时刻t通过的结点到最终结点时,对于所有其他可能的路径来说一定是最优的,如果不是,那么则出现另外一条最优的,与假设本路径最优矛盾,因此,我们只需,从时刻t=1开始,递推的计算在时刻t状态为i的各条部分路径的最大概率,直到得到t=T状态为i的各条路径的最大概率。时刻t=T的最大概率即为最优路径的概率P,最优路径的终结点iT同时得到。为了找到最优路径的各个结点,从iT开始,由后向前逐步求得结点得到最优路径I, ,这就是Viterbi算法。
,这就是Viterbi算法。
定义在时刻t状态为i的所有单个路径(i1,i2,…,iT)中概率最大值为: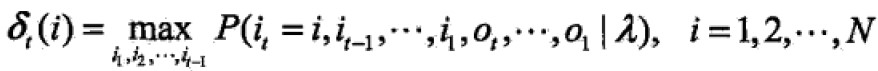
可得变量δ的递推公式: 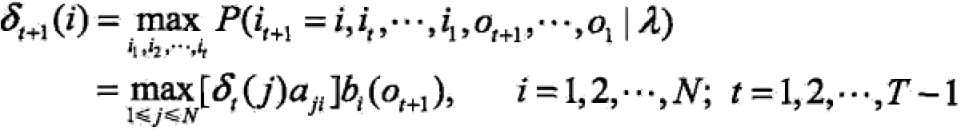
时刻t状态为i的所有单个路径概率最大的路径中第t-1个结点为: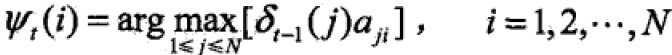
Viterbi 算法: 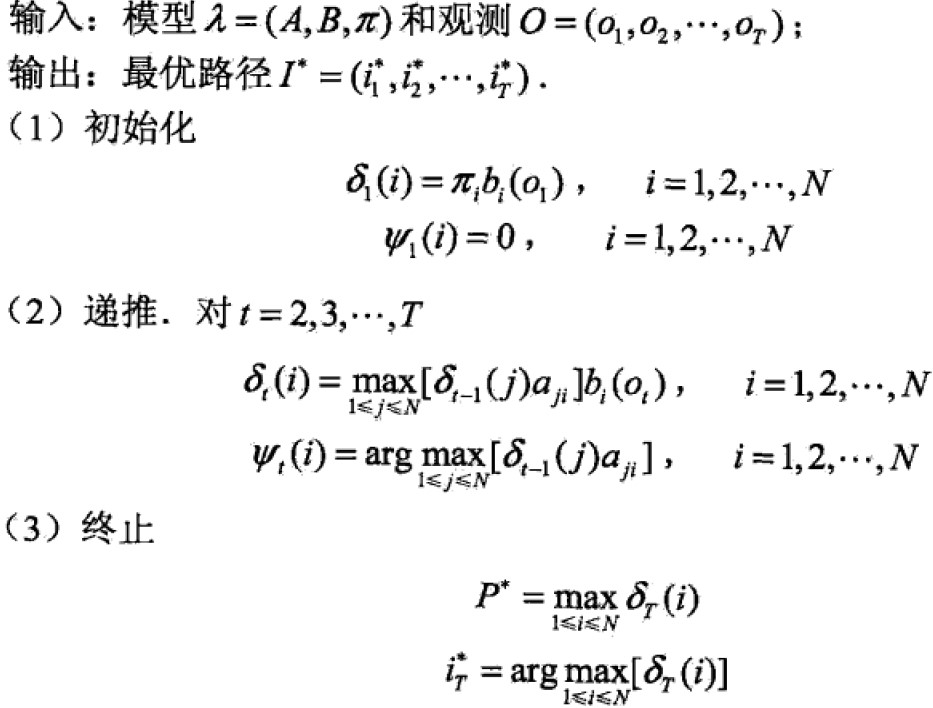

隐马尔可夫模型HMM的更多相关文章
- 基于隐马尔科夫模型(HMM)的地图匹配(Map-Matching)算法
文章目录 1. 1. 摘要 2. 2. Map-Matching(MM)问题 3. 3. 隐马尔科夫模型(HMM) 3.1. 3.1. HMM简述 3.2. 3.2. 基于HMM的Map-Matchi ...
- 隐马尔科夫模型HMM学习最佳范例
谷歌路过这个专门介绍HMM及其相关算法的主页:http://rrurl.cn/vAgKhh 里面图文并茂动感十足,写得通俗易懂,可以说是介绍HMM很好的范例了.一个名为52nlp的博主(google ...
- 猪猪的机器学习笔记(十七)隐马尔科夫模型HMM
隐马尔科夫模型HMM 作者:樱花猪 摘要: 本文为七月算法(julyedu.com)12月机器学习第十七次课在线笔记.隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来 ...
- 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 隐马尔科夫模型HMM(一)HMM模型
隐马尔科夫模型HMM(一)HMM模型基础 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比 ...
- 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态序列
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态 ...
- 用hmmlearn学习隐马尔科夫模型HMM
在之前的HMM系列中,我们对隐马尔科夫模型HMM的原理以及三个问题的求解方法做了总结.本文我们就从实践的角度用Python的hmmlearn库来学习HMM的使用.关于hmmlearn的更多资料在官方文 ...
- HMM:隐马尔可夫模型HMM
http://blog.csdn.net/pipisorry/article/details/50722178 隐马尔可夫模型 隐马尔可夫模型(Hidden Markov Model,HMM)是统计模 ...
- 机器学习之隐马尔科夫模型HMM(六)
摘要 隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔科夫过程.其难点是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来作进一步 ...
随机推荐
- linux系统之-vi编辑器
在linux系统使用中,掌握熟练的vi编辑器,可以提高linux工作效率.那么vi编辑器的使用方法有哪些呢? vi编辑器可在绝大部分linux发行版中使用. Vi编辑器的作用:创建或修改文件:维护li ...
- 如何在linux系统内用openssl 生成 过期的证书
需求:验证过期的证书在系统中不能使用. 问题:如何生成过期的证书呢? 解决方法:1.调整系统时间 2.生成证书 3.验证证书startdate 和 enddate 是否符合你的预期 1.调整系统时间 ...
- 富文本编辑器 summernote.js
1.引用js 可在 https://summernote.org/ 官网下载 ,并查看详细的API 引入:summernote.js 和 summernote-zh-CN.js 以及样式文件:su ...
- C语言实例解析精粹学习笔记——31
实例31: 判断字符串是否是回文 思路解析: 引入两个指针变量(head和tail),开始时,两指针分别指向字符串的首末字符,当两指针所指字符相等时,两指针分别向后和向前移动一个字符位置,并继续比较, ...
- P2153 [SDOI2009]晨跑(最小费用最大流)
题目描述 Elaxia最近迷恋上了空手道,他为自己设定了一套健身计划,比如俯卧撑.仰卧起坐等 等,不过到目前为止,他坚持下来的只有晨跑. 现在给出一张学校附近的地图,这张地图中包含N个十字路口和M条街 ...
- [Cracking the Coding Interview] 4.3 List of Depths
Given a binary tree, design an algorithm which creates a linked list of all the nodes at each depth. ...
- SPLIT(文字列の分割)
概要 SPLIT命令は特定の文字で値を分割する命令だ.タブ区切りや.カンマ区切り等のファイルからデータを取得し値を各項目に振り分けたい時に使用する事が多いだろう.また.XMLファイル等を使用してインタ ...
- kudu是什么
Apache Kudu Overview 建议配合[Apache Kudo]审阅本文(http://kudu.apache.org/overview.html) 数据模式 Kudo是一个列式存储的用于 ...
- AR技术介绍(Located in Android)
一,什么是AR 在说AR技术之前,先来说说VR. 虚拟现实(VR:Virtual Reality)是采用以计算机技术为核心的技术,生成逼真的视,听,触觉等一体化的虚拟环境,用户借助必要的设备以自然的方 ...
- 洛谷P1364 医院设置
LITTLESUN的第一道图论,撒花~~ 题目链接 这道题是Floyd的板子题 注意对于矩阵图的初始值赋值要全部赋值成最大值 十六进制的最大值表示方式是0x3f3f3f3f memset(G,0x3f ...