本人的开发环境:
1.虚拟机centos 6.5
2.jdk 1.8
3.spark2.2.0
4.scala 2.11.8
5.maven 3.5.2
在开发和搭环境时必须注意版本兼容的问题,不然会出现很多莫名其妙的问题
1.启动spark master
2.启动worker
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
步骤1,2是必须在启动任务之前的。注意worker必须和flume的agent在同一节点,我这里是一台服务器调试,所以直接在同一台机器调试,相当于在一个端口A流出数据(telnet实现),获取数据并流入到同一IP的另一个端口B(flume实现),监听端口B数据并流式处理(Spark Streaming),写入数据库(mysql)。
3.spark streaming代码开发,flume push方式
package com.spark
import java.sql.DriverManager
import com.spark.ForeachRDDApp.createConnection
import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FlumePushSparkStreaming {
def main(args: Array[String]): Unit = {
if( args.length != 2 ) {
System.out.print("Usage:flumepushworkCount <hostname> <port>")
System.exit(1)
}
val Array(hostname, port) = args
val sparkConf = new SparkConf()
val ssc = new StreamingContext(sparkConf, Seconds(5))
val flumeStream = FlumeUtils.createStream(ssc, hostname, port.toInt)
val result = flumeStream.map(x => new String(x.event.getBody.array()).trim)
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
result.print()
result.foreachRDD(rdd => { //注意1
rdd.foreachPartition(partitionOfRecords => {
val connection = createConnection()
partitionOfRecords.foreach(record => {
val sql = "insert into FlumeWordCount(word, wordcount) values('" + record._1 + "'," + record._2 + ")"
connection.createStatement().execute(sql)
})
connection.close()
})
})
ssc.start()
ssc.awaitTermination()
}
/**
* 获取MySQL的连接
*/
def createConnection() = {
Class.forName("com.mysql.jdbc.Driver")
DriverManager.getConnection("jdbc:mysql://master:3306/imooc_spark", "root", "root")
}
}
代码很容易理解,在这就不解析了。不过程序还是不够好,还有优化的地方。请看注意1,优化地方:1.使用线程池的方法来连接mysql。2.Spqrk的闭包原理,在集群中,RDD传给执行器的只是副本,一个RDD并不是全部的数据,然而这里写进mysql数据正确是因为在同一个节点调试,所有的RDD只在本机器操作,因此数据都可以写进mysql。如果在集群中,可能结果是不一样的。解决办法:使用collect( )。
4.flume配置
flume_sparkstreaming_mysql.sources = netcat-source
flume_sparkstreaming_mysql.sinks = avro-sink
flume_sparkstreaming_mysql.channels = memory-channel
flume_sparkstreaming_mysql.sources.netcat-source.type = netcat
flume_sparkstreaming_mysql.sources.netcat-source.bind = master
flume_sparkstreaming_mysql.sources.netcat-source.port = 44444
flume_sparkstreaming_mysql.sinks.avro-sink.type = avro
flume_sparkstreaming_mysql.sinks.avro-sink.hostname = master
flume_sparkstreaming_mysql.sinks.avro-sink.port = 41414
flume_sparkstreaming_mysql.channels.memory-channel.type = memory
flume_sparkstreaming_mysql.sources.netcat-source.channels = memory-channel
flume_sparkstreaming_mysql.sinks.avro-sink.channel = memory-channel
flume的配置也很简单,需要注意的是这里是在服务器跑的, 注意黑体的地方,要写服务器的IP地址,而不是本地调试的那个IP。
3.打jar包并提交任务
./spark-submit --class com.spark.FlumePushSparkStreaming --master local[2] --packages org.apache.spark:spark-streaming-flume_2.11:2.2.0 /home/hadoop/tmp/spark.jar master 41414
4.启动flume-push方式
./flume-ng agent --name simple-agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/flume_push_streaming.conf -Dflume.root.logger=INFO,consol
5.建表
create table FlumeWordCount(
word varchar(50) default null,
wordcount int(10) default null
);
6.监听 master : 44444
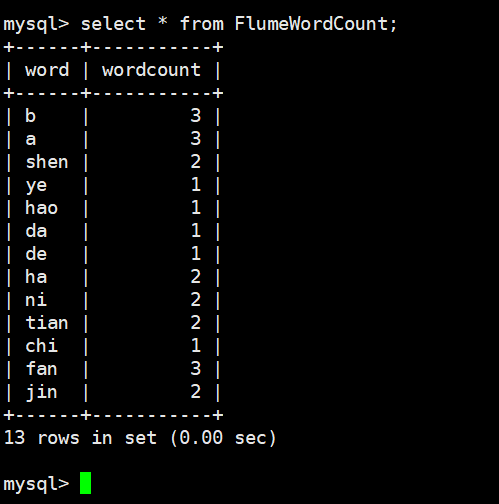
7.mysql 查看数据
mysql> select * from FlumeWordCount;
8.终端打印

- [原创]mybatis中整合ehcache缓存框架的使用
mybatis整合ehcache缓存框架的使用 mybaits的二级缓存是mapper范围级别,除了在SqlMapConfig.xml设置二级缓存的总开关,还要在具体的mapper.xml中开启二级缓 ...
- kindeditor4整合SyntaxHighlighter,让代码亮起来
这一篇我将介绍如何让kindeditor4.x整合SyntaxHighlighter代码高亮,因为SyntaxHighlighter的应用非常广泛,所以将kindeditor默认的prettify替换 ...
- spring源码分析之freemarker整合
FreeMarker是一款模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本(HTML网页.电子邮件.配置文件.源代码等)的通用工具. 它不是面向最终用户的,而是一个Java类库,是一款程 ...
- FullCalendar应用——整合农历节气和节日
FullCalendar用来做日程管理功能非常强大,但是唯一不足的地方是没有将中国农历历法加进去,今天我将结合实例和大家分享如何将中国农历中的节气和节日整合到FullCalendar中,从而增强其实用 ...
- SAP CRM 将组件整合至导航栏中
到现在,我们已经可以让组件独立地显示.我们只是运行它.让它显示在Web UI中.让我们把组件整合进导航栏,使我们可以在正常登录Web UI时访问它. 步骤一: 为你的UI组件主窗体创建一个内向插件. ...
- Atitit.你这些项目不都是模板吗?不是原创 集成和整合的方式大总结
Atitit.你这些项目不都是模板吗?不是原创 集成和整合的方式大总结 1.1. 乔布斯的名言:创新即整合(Creativity is just connecting things).1 1.2. ...
- github入门到上传本地项目【网上资源整合】
[在原文章的基础上,修改了描述的不够详细的地方,对内容进行了扩充,整合了网上的一些资料] [内容主要来自http://www.cnblogs.com/specter45/p/github.html#g ...
- 三大框架SSH整合
三大框架SSH整合 -------------------------------Spring整合Hibernate------------------------------- 一.为什么要整合Hi ...
- SSH框架整合(代码加文字解释)
一.创建数据库并设置编码. A) create database oa default character set utf8. 二.MyEclipse工程 A) 在Myeclipse里创建web工程, ...
随机推荐
- c# 通过dllimport 调用c 动态链接库
https://blog.csdn.net/zhunju0089/article/details/80906501 这篇文件很详细 讲述了如何创建c 动态链接库项目 有一些注意的地方 不做介绍 下面是 ...
- Sprint + mybatis 编写测试
今天使用Spring 和mybatis框架编写项目,写了个测试方法方便测试,之前因为一直报空指针,注入不了,所以简单记录一下,方便以后使用 root.xml <?xml version=&quo ...
- SQLServer中的事物与锁
了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂,不能保证数据的安全正确读写. 死锁: ...
- day18-事务与连接池 2.事务介绍与mysql下事务操作
这么玩 真的变了吗?把cmd窗口关闭了看看. 就是固定的套路才行:start transaction->执行SQL->rollback; 执行每一条SQL之前都要start transac ...
- python小程序:备份文件
设计程序,有以下步骤: 需要备份的文件和目录由一个列表指定. 备份应该保存在主备份目录中. 文件备份成一个zip文件. zip存档的名称是当前的日期和时间. 解决方案: 版本一: #!/usr/bin ...
- 使用百度翻译的API接口
http://api.fanyi.baidu.com/api/trans/product/desktop 这是申请的接口地址,会得到一个APPID和一个钥密 然后下载PHP的对应的代码 有一个PHP文 ...
- 浅析junit4及扩展实践
junit框架相关源代码分析,网上已经有很多了,本篇不做过多相关解说,主要还是要自己多读相关源代码.本篇主要对自动化测试过程相关的测试用例,测试数据,测试结果结合junit做相关扩展说明. 如果要解读 ...
- ROS naviagtion analysis: costmap_2d--CostmapLayer
博客转自:https://blog.csdn.net/u013158492/article/details/50493220 这个类是为ObstacleLayer StaticLayer voxelL ...
- Zephyr Introduction
wiki Importer Workflow wiki https://zephyrdocs.atlassian.net/wiki/display/ZTD/Zephyr+for+JIRA+Docume ...
- R 如何 隐藏坐标轴
x = c(7,5,8)dim(x)<-3names(x)<-c("apple","banana", "cherry")plot ...