Hadoop完全分布式环境搭建(四)——基于Ubuntu16.04安装和配置Hadoop大数据环境
【系统环境】
【安装配置概要】
1、上传hadoop安装文件到主节点机器
2、给文件夹设置权限
3、解压
4、拷贝到目标文件夹
放在/opt文件夹下,目录结构:/opt/hadoop/hadoop-2.6.4
5、配置hadoop系统环境变量
6、配置相关文件:hadoop-env.sh、core-site.xml、hdfs-site.xml,mapred-site.xml、yarn-site.xml、slaves
7、使用scp 拷贝传输hadoop文件夹到其它两台从节点机器上
8、使用scp 拷贝环境变量配置文件到其它两台从节点机器上
9、格式化namenode
10、测试检查
【详细步骤】
1、启用SecureCRT,分别连接主节点和两台从节点机器,以hadoop账号登录主节点master,切换到hadoop账号根目录下
cd ~
rz
浏览并上传hadoop-2.6.4.tar.gz文件
2、1)、解压,解压到hadoop账号根目录下
tar -zxvf hadoop-2.6.4.tar.gz
2)、放到/opt文件夹下,文件夹结构:/opt/hadoop/hadoop-2.6.4,建立/opt/hadoop文件夹
cd /opt
mkdir hadoop
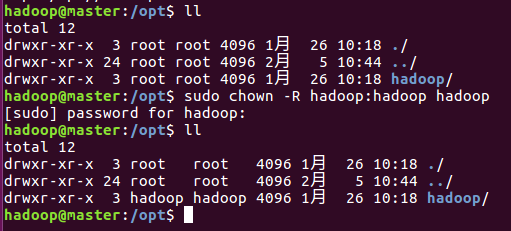
3)、先给/opt文件夹设置权限
sudo chown -R hadoop:hadoop opt
在两台从节点上也分别以hadoop账号登录,设置/opt文件夹的操作权限,不然,后面由主节点拷贝hadoop文件到从节点机器上会权限不够
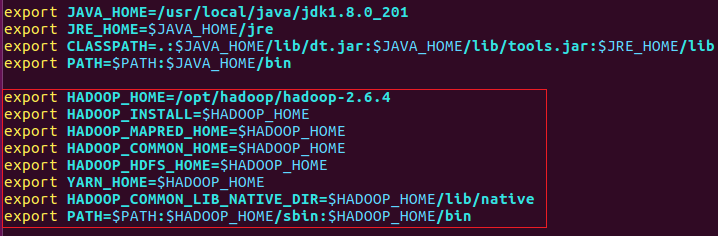
4、配置hadoop的环境变量
vi /etc/profile
增加:
export HADOOP_HOME=/opt/hadoop/hadoop-2.6.4
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
如下图:
5.配置hadoop相关配置文件
1)、配置hadoop-env.sh
把export JAVA_HOME=${JAVA_HOME}注释掉,改成实际d路径 如下

2)、编辑core-site.xml

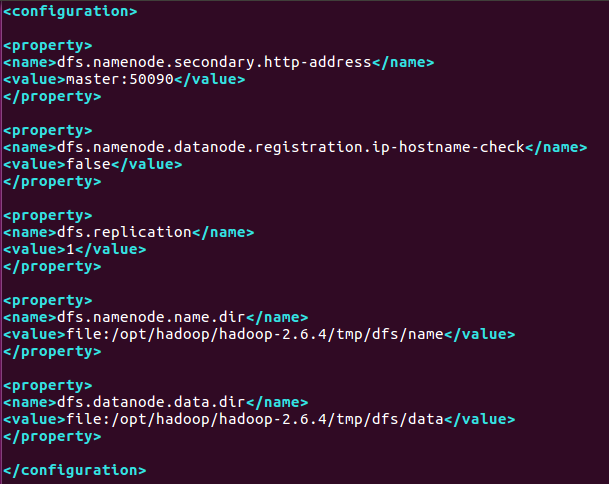
3)、编辑hdfs-site.xml
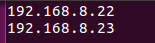
4)、编辑slaves
把从节点的IP地址写到这个文件里
6、使用scp拷贝已经配置好的hadoop文件到其它两台从节点机器上
scp -r hadoop hadoop@slave1:/opt/
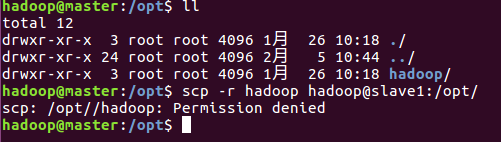
报没有权限,需先设置权限
Chown -R hadoop:hadoop hadoop
sudo chown -R 用户名@用户组 目录名
7、在主节点上配置hadoop的环境变量
vi /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_201
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop/hadoop-2.6.4
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin

8、使用scp拷贝环境变量配置文件到其它两台从节点机器上
scp /etc/profile hadoop:slave1:/etc
并登陆从节点机器,启用环境变量配置
source /etc/profile
使用java -version进行检查
9、格式化namenode
在宿主机上输入:hadoop namenode -format
10、测试检查
1)、输入jps
在主节点:

在从节点:

2)、在宿主机浏览器输入:http://master IP:50070
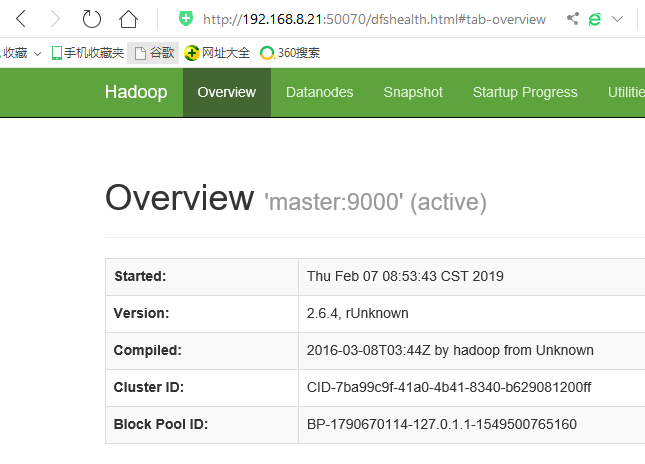
至此,Hadoop的完全分布式环境安装配置完毕。
Hadoop完全分布式环境搭建(四)——基于Ubuntu16.04安装和配置Hadoop大数据环境的更多相关文章
- Hadoop完全分布式环境搭建(三)——基于Ubuntu16.04安装和配置Java环境
[系统环境] 1.宿主机OS:Win10 64位 2.虚拟机软件:VMware WorkStation 12 3.虚拟机OS:Ubuntu16.04 4.三台虚拟机 5.JDK文件:jdk-8u201 ...
- 【Hadoop离线基础总结】CDH版本Hadoop 伪分布式环境搭建
CDH版本Hadoop 伪分布式环境搭建 服务规划 步骤 第一步:上传压缩包并解压 cd /export/softwares/ tar -zxvf hadoop-2.6.0-cdh5.14.0.tar ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- 【转】Hadoop HDFS分布式环境搭建
原文地址 http://blog.sina.com.cn/s/blog_7060fb5a0101cson.html Hadoop HDFS分布式环境搭建 最近选择给大家介绍Hadoop HDFS系统 ...
- hadoop ——完全分布式环境搭建
hadoop 完全分布式环境搭建 1.虚拟机角色分配: 192.168.44.184 hadoop02 NameNode/DataNode ResourceManager/NodeManager 19 ...
- Hadoop完全分布式环境搭建(二)——基于Ubuntu16.04设置免密登录
在Windows里,使用虚拟机软件Vmware WorkStation搭建三台机器,操作系统Ubuntu16.04,下面是IP和机器名称. [实验目标]:在这三台机器之间实现免密登录 1.从主节点可以 ...
- 《OD大数据实战》Hadoop伪分布式环境搭建
一.安装并配置Linux 8. 使用当前root用户创建文件夹,并给/opt/下的所有文件夹及文件赋予775权限,修改用户组为当前用户 mkdir -p /opt/modules mkdir -p / ...
- Hadoop完全分布式环境搭建
前言 本文搭建了一个由三节点(master.slave1.slave2)构成的Hadoop完全分布式集群(区别单节点伪分布式集群),并通过Hadoop分布式计算的一个示例测试集群的正确性. 本文集群三 ...
- hadoop全分布式环境搭建
本文主要介绍基本的hadoop的搭建过程.首先说下我的环境准备.我的笔记本使用的是Windows10专业版,装的虚拟机软件为VMware WorkStation Pro,虚拟机使用的系统为centos ...
随机推荐
- [转载] FFmpeg源代码简单分析:常见结构体的初始化和销毁(AVFormatContext,AVFrame等)
===================================================== FFmpeg的库函数源代码分析文章列表: [架构图] FFmpeg源代码结构图 - 解码 F ...
- Scrapy组件之item
Scrapy是一个流行的网络爬虫框架,从现在起将陆续记录Python3.6下Scrapy整个学习过程,方便后续补充和学习.Python网络爬虫之scrapy(一)已经介绍scrapy安装.项目创建和测 ...
- 微软原版WINDOWS10-LTSB-X64位操作系统的全新安装与优化
原版WINDOWS10_LTSB_X64位操作系统,安装U盘的制作 1.在一台能正常运行的电脑上,下载原版WINDOWS10_LTSB_X64位操作系统镜像(ISO)文件: 2.运行UltraISO. ...
- HDFS的工作原理扫扫盲
问题导读: 1.什么是分布式文件系统? 2.怎样分离元数据和数据? 3.HDFS的原理是什么? Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个 ...
- volley源码解析-Throwable类源码解析
前提知识点: 1.Serializable接口 作用:表示可序列化的语义.就是Java提供的通用数据保存和读取接口.任何类型实现了Serializeable接口,就可以被保存到文件中,或者作为数据流通 ...
- C#结构体数组间的转化
转自:http://developer.51cto.com/art/200908/143779.htm 解决C#结构体数组间的转化问题的由来:在写C#TCP通信程序时,发送数据时,如果是和VC6.0等 ...
- Linux多网卡的时候执行机器Ip
在Linux部署的时候,经常会有多网卡的情况出现,这时候项目又需要指定Ip.在这种情况下,要配置linux机子的host,指定里头要使用的ip地址,否则linux机子不知道去找哪个ip. 一.查看本机 ...
- aspupload ,在winows server 2008 下无法使用
aspupload ,在winows server 2008 下无法使用.求助解决办法 2014-01-12 13:31 goolean | 浏览 775 次 操作系统 aspupload64位,安装 ...
- mysql函数之六:mysql插入数据后返回自增ID的方法,last_insert_id(),selectkey
mysql插入数据后返回自增ID的方法 mysql和oracle插入的时候有一个很大的区别是,oracle支持序列做id,mysql本身有一个列可以做自增长字段,mysql在插入一条数据后,如何能获得 ...
- 过河卒(Noip2002)(dp)
过河卒(Noip2002) 时间限制: 1 Sec 内存限制: 128 MB提交: 7 解决: 6[提交][状态][讨论版][命题人:quanxing] 题目描述 棋盘上A点有一个过河卒,需要走到 ...