Hadoop相关知识整理系列之一:HBase基本架构及原理
1. HBase框架简单介绍
HBase是一个分布式的、面向列的开源数据库,它不同于一般的关系数据库,是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。HBase使用和 BigTable非常相同的数据模型。用户存储数据行在一个表里。一个数据行拥有一个可选择的键和任意数量的列,一个或多个列组成一个ColumnFamily,一个Fmaily下的列位于一个HFile中,易于缓存数据。表是疏松的存储的,因此用户可以给行定义各种不同的列。在HBase中数据按主键排序,同时表按主键划分为多个Region。
在分布式的生产环境中,HBase 需要运行在 HDFS 之上,以 HDFS 作为其基础的存储设施。HBase 上层提供了访问的数据的 Java API 层,供应用访问存储在 HBase 的数据。在 HBase 的集群中主要由 Master 和 Region Server 组成,以及 Zookeeper,具体模块如下图所示:
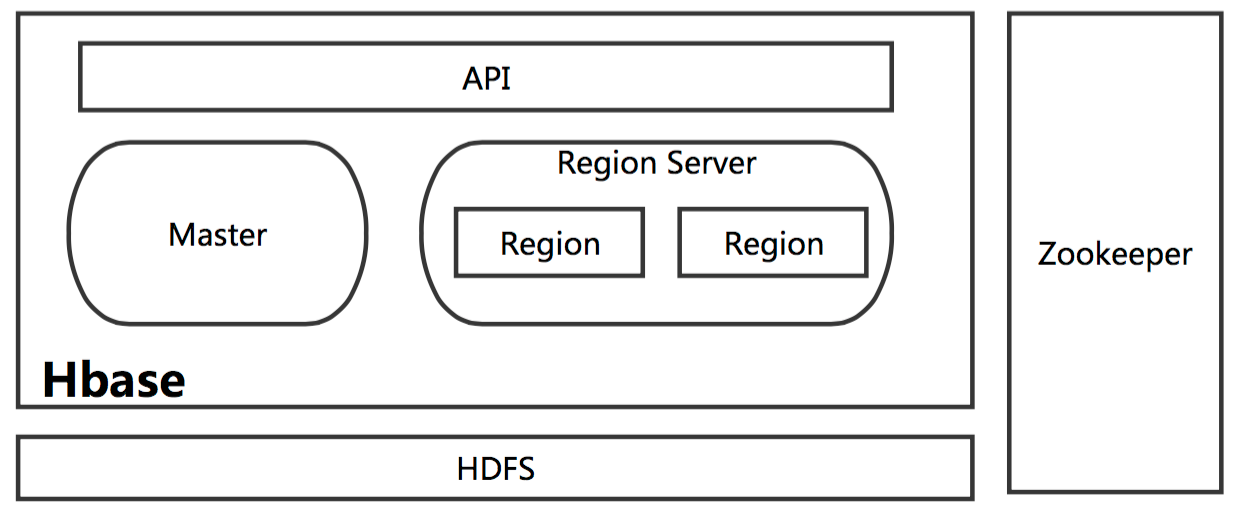
简单介绍一下 HBase 中相关模块的作用:
- Master
HBase Master用于协调多个Region Server,侦测各个RegionServer之间的状态,并平衡RegionServer之间的负载。HBaseMaster还有一个职责就是负责分配Region给RegionServer。HBase允许多个Master节点共存,但是这需要Zookeeper的帮助。不过当多个Master节点共存时,只有一个Master是提供服务的,其他的Master节点处于待命的状态。当正在工作的Master节点宕机时,其他的Master则会接管HBase的集群。 - Region Server
对于一个RegionServer而言,其包括了多个Region。RegionServer的作用只是管理表格,以及实现读写操作。Client直接连接RegionServer,并通信获取HBase中的数据。对于Region而言,则是真实存放HBase数据的地方,也就说Region是HBase可用性和分布式的基本单位。如果当一个表格很大,并由多个CF组成时,那么表的数据将存放在多个Region之间,并且在每个Region中会关联多个存储的单元(Store)。 - Zookeeper
对于 HBase 而言,Zookeeper的作用是至关重要的。首先Zookeeper是作为HBase Master的HA解决方案。也就是说,是Zookeeper保证了至少有一个HBase Master 处于运行状态。并且Zookeeper负责Region和Region Server的注册。其实Zookeeper发展到目前为止,已经成为了分布式大数据框架中容错性的标准框架。不光是HBase,几乎所有的分布式大数据相关的开源框架,都依赖于Zookeeper实现HA。
2. Hbase数据模型
2.1 逻辑视图

基本概念:
- RowKey:是Byte array,是表中每条记录的“主键”,方便快速查找,Rowkey的设计非常重要;
- Column Family:列族,拥有一个名称(string),包含一个或者多个相关列;
- Column:属于某一个columnfamily,familyName:columnName,每条记录可动态添加;
- Version Number:类型为Long,默认值是系统时间戳,可由用户自定义;
- Value(Cell):Byte array。
2.2 物理模型:
- 每个column family存储在HDFS上的一个单独文件中,空值不会被保存。
- Key 和 Version number在每个column family中均有一份;
- HBase为每个值维护了多级索引,即:<key, columnfamily, columnname, timestamp>;
- 表在行的方向上分割为多个Region;
- Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上。
- Region按大小分割的,随着数据增多,Region不断增大,当增大到一个阀值的时候,Region就会分成两个新的Region;
- Region虽然是分布式存储的最小单元,但并不是存储的最小单元。每个Region包含着多个Store对象。每个Store包含一个MemStore或若干StoreFile,StoreFile包含一个或多个HFile。MemStore存放在内存中,StoreFile存储在HDFS上。
疑问:每一个Region都只存储一个ColumnFamily的数据,并且是该CF中的一段(按Row的区间分成多个 Region)?这个需要查证,每个Region只包含一个ColumnFamily可以提高并行性?然而,我只知道每个Store只包含一个ColumnFamily的数据。
2.3 ROOT表和META表
HBase的所有Region元数据被存储在.META.表中,随着Region的增多,.META.表中的数据也会增大,并分裂成多个新的Region。为了定位.META.表中各个Region的位置,把.META.表中所有Region的元数据保存在-ROOT-表中,最后由Zookeeper记录-ROOT-表的位置信息。所有客户端访问用户数据前,需要首先访问Zookeeper获得-ROOT-的位置,然后访问-ROOT-表获得.META.表的位置,最后根据.META.表中的信息确定用户数据存放的位置,如下图所示。
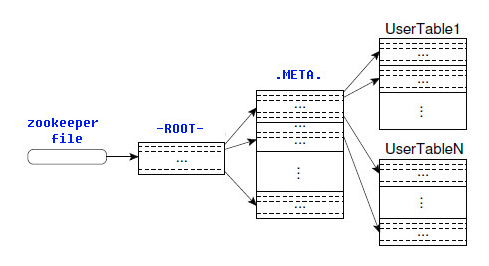
-ROOT-表永远不会被分割,它只有一个Region,这样可以保证最多只需要三次跳转就可以定位任意一个Region。为了加快访问速度,.META.表的所有Region全部保存在内存中。客户端会将查询过的位置信息缓存起来,且缓存不会主动失效。如果客户端根据缓存信息还访问不到数据,则询问相关.META.表的Region服务器,试图获取数据的位置,如果还是失败,则询问-ROOT-表相关的.META.表在哪里。最后,如果前面的信息全部失效,则通过ZooKeeper重新定位Region的信息。所以如果客户端上的缓存全部是失效,则需要进行6次网络来回,才能定位到正确的Region。
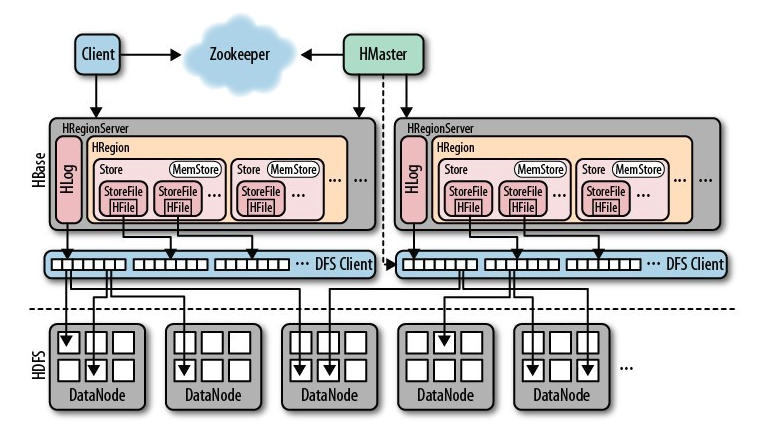
一个完整分布式的HBase的组成示意图如下,后面我们再详细谈其工作原理。
3. 高可用
3.1 Write-Ahead-Log(WAL)保障数据高可用
我们理解下HLog的作用。HBase中的HLog机制是WAL的一种实现,而WAL(一般翻译为预写日志)是事务机制中常见的一致性的实现方式。每个RegionServer中都会有一个HLog的实例,RegionServer会将更新操作(如 Put,Delete)先记录到 WAL(也就是HLo)中,然后将其写入到Store的MemStore,最终MemStore会将数据写入到持久化的HFile中(MemStore 到达配置的内存阀值)。这样就保证了HBase的写的可靠性。如果没有 WAL,当RegionServer宕掉的时候,MemStore 还没有写入到HFile,或者StoreFile还没有保存,数据就会丢失。或许有的读者会担心HFile本身会不会丢失,这是由 HDFS 来保证的。在HDFS中的数据默认会有3份。因此这里并不考虑 HFile 本身的可靠性。
HFile由很多个数据块(Block)组成,并且有一个固定的结尾块。其中的数据块是由一个Header和多个Key-Value的键值对组成。在结尾的数据块中包含了数据相关的索引信息,系统也是通过结尾的索引信息找到HFile中的数据。
3.2 组件高可用
- Master容错:Zookeeper重新选择一个新的Master。如果无Master过程中,数据读取仍照常进行,但是,region切分、负载均衡等无法进行;
- RegionServer容错:定时向Zookeeper汇报心跳,如果一旦时间内未出现心跳,Master将该RegionServer上的Region重新分配到其他RegionServer上,失效服务器上“预写”日志由主服务器进行分割并派送给新的RegionServer;
- Zookeeper容错:Zookeeper是一个可靠地服务,一般配置3或5个Zookeeper实例。
4. HBase读写流程

上图是RegionServer数据存储关系图。上文提到,HBase使用MemStore和StoreFile存储对表的更新。数据在更新时首先写入HLog和MemStore。MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到Flush队列,由单独的线程Flush到磁盘上,成为一个StoreFile。与此同时,系统会在Zookeeper中记录一个CheckPoint,表示这个时刻之前的数据变更已经持久化了。当系统出现意外时,可能导致MemStore中的数据丢失,此时使用HLog来恢复CheckPoint之后的数据。
StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定阈值后,就会进行一次合并操作,将对同一个key的修改合并到一起,形成一个大的StoreFile。当StoreFile的大小达到一定阈值后,又会对 StoreFile进行切分操作,等分为两个StoreFile。
4.1 写操作流程
- (1) Client通过Zookeeper的调度,向RegionServer发出写数据请求,在Region中写数据。
- (2) 数据被写入Region的MemStore,直到MemStore达到预设阈值。
- (3) MemStore中的数据被Flush成一个StoreFile。
- (4) 随着StoreFile文件的不断增多,当其数量增长到一定阈值后,触发Compact合并操作,将多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除。
- (5) StoreFiles通过不断的Compact合并操作,逐步形成越来越大的StoreFile。
- (6) 单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个新的Region。父Region会下线,新Split出的2个子Region会被HMaster分配到相应的RegionServer上,使得原先1个Region的压力得以分流到2个Region上。
可以看出HBase只有增添数据,所有的更新和删除操作都是在后续的Compact历程中举行的,使得用户的写操作只要进入内存就可以立刻返回,实现了HBase I/O的高机能。
4.2 读操作流程
- (1) Client访问Zookeeper,查找-ROOT-表,获取.META.表信息。
- (2) 从.META.表查找,获取存放目标数据的Region信息,从而找到对应的RegionServer。
- (3) 通过RegionServer获取需要查找的数据。
- (4) Regionserver的内存分为MemStore和BlockCache两部分,MemStore主要用于写数据,BlockCache主要用于读数据。读请求先到MemStore中查数据,查不到就到BlockCache中查,再查不到就会到StoreFile上读,并把读的结果放入BlockCache。
寻址过程:client-->Zookeeper-->-ROOT-表-->.META.表-->RegionServer-->Region-->client
其它相关内容待补充
Hadoop相关知识整理系列之一:HBase基本架构及原理的更多相关文章
- 机器学习相关知识整理系列之一:决策树算法原理及剪枝(ID3,C4.5,CART)
决策树是一种基本的分类与回归方法.分类决策树是一种描述对实例进行分类的树形结构,决策树由结点和有向边组成.结点由两种类型,内部结点表示一个特征或属性,叶结点表示一个类. 1. 基础知识 熵 在信息学和 ...
- 机器学习相关知识整理系列之三:Boosting算法原理,GBDT&XGBoost
1. Boosting算法基本思路 提升方法思路:对于一个复杂的问题,将多个专家的判断进行适当的综合所得出的判断,要比任何一个专家单独判断好.每一步产生一个弱预测模型(如决策树),并加权累加到总模型中 ...
- 机器学习相关知识整理系列之二:Bagging及随机森林
1. Bagging的策略 从样本集中重采样(有放回)选出\(n\)个样本,定义子样本集为\(D\): 基于子样本集\(D\),所有属性上建立分类器,(ID3,C4.5,CART,SVM等): 重复以 ...
- Redis相关知识整理
Redis相关知识整理 1. Redis和MySQL的区别?a).mysql是关系型数据库,而redis是NOSQL,非关系型数据库.mysql将数据持久化到硬盘,读取数据慢,而redis数据先存储在 ...
- podSpec文件相关知识整理
上一篇文章整理了我用SVN创建私有库的过程,本文将整理一下有关podSpec文件的相关知识. podSpec中spec的全称是“Specification”,说明书的意思.顾名思义,这是用来描述你这个 ...
- OpenCV&Qt学习之四——OpenCV 实现人脸检测与相关知识整理
开发配置 OpenCV的例程中已经带有了人脸检测的例程,位置在:OpenCV\samples\facedetect.cpp文件,OpenCV的安装与这个例子的测试可以参考我之前的博文Linux 下编译 ...
- [Cxf] cxf 相关知识整理
① 请求方式为GET @GET @Path(value = "/userAddressManage") @Produces( { MediaType.APPLICATION_JSO ...
- Web缓存相关知识整理
一.前言 工作上遇到一个这样的需求,一个H5页面在APP端,如果勾选已读状态,则下次打开该链接,会跳过此页面.用到了HTML5 的本地存储 API 中的 localStorage作为解决方案,回顾了 ...
- JVM的相关知识整理和学习--(转载)
JVM是虚拟机,也是一种规范,他遵循着冯·诺依曼体系结构的设计原理.冯·诺依曼体系结构中,指出计算机处理的数据和指令都是二进制数,采用存储程序方式不加区分的存储在同一个存储器里,并且顺序执行,指令由操 ...
随机推荐
- 目标跟踪之klt---光流跟踪法
近来在研究跟踪,跟踪的方法其实有很多,如粒子滤波(pf).meanshift跟踪,以及KLT跟踪或叫Lucas光流法,这些方法各自有各自的有点,对于粒子滤波而言,它能够比较好的在全局搜索到最优解,但其 ...
- 用ActivatedRoute获取url中的参数
突然让我用ActivatedRoute import {Injectable} from "@angular/core"; import {ActivatedRoute} from ...
- go http的三种实现---2
package main import ( "io" "log" "net/http" "os" ) func main ...
- ApiDoc 和 Swagger 接口文档
ApiDoc:https://blog.csdn.net/weixin_38682852/article/details/78812244 Swagger git: https://github.co ...
- PowerDesigner如何导出表到word的方法
from:https://jingyan.baidu.com/article/295430f1c385970c7f005056.html PowerDesigner如何导出表到word的方法 听语音 ...
- Android开发:使用DialogFragment实现dialog自定义布局
使用DialogFragment实现dialog的自定义布局最大的好处是可以更好控制dialog的生命周期. TestFragment的代码: public class TestFragment ex ...
- iOS学习笔记(四)——iOS应用程序生命周期
开发应用程序都要了解其生命周期,开始接触android时也是从应用程序生命周期开始的,android的应用程序生命周期更多是其组件的生命周期,例如Activity.Service.今天我们接触一下iO ...
- PAT trie
最近在上计算机应用编程,老师给了一个大小为900MB的含20000000行邮箱地址的文件. 然后再给出了1000条查询数据,让你用字典树建树然后查询是否出现过. 试了下普通的tire树,特意用二进制写 ...
- B - The Suspects(并查集)
B - The Suspects Time Limit:1000MS Memory Limit:20000KB 64bit IO Format:%lld & %llu Desc ...
- EasyUI 相关
根据关键字值取行 var rowIndex = $('#tt').datagrid('getRowIndex', id);//id是关键字值 var data = $('#tt').datagrid( ...