基于apache —HttpClient的小爬虫获取网页内容
今天(17-03-31)忙了一下午研究webmagic,发现自己还太年轻,对于这样难度的框架(类库)
还是难以接受,还是从基础开始吧,因为相对基础的东西教程相多一些,于是乎我找了apache其下的
HttpClient,根据前辈们发的教程自己也简单写了一下,感觉还好。
下面实现的是单个页面的获取:
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils; import java.io.IOException; public class Main { public static void main(String[] args) throws IOException{
try {
//创建client实例
HttpClient client= HttpClients.createDefault();
//创建httpget实例
HttpGet httpGet=new HttpGet("http://www.btba.com.cn");
//执行 get请求
HttpResponse response=client.execute(httpGet);
//返回获取实体
HttpEntity entity=response.getEntity();
//获取网页内容,指定编码
String web= EntityUtils.toString(entity,"UTF-8");
//输出网页
System.out.println(web); } catch (IOException e) {
e.printStackTrace();
} }
}
部分截图展示:
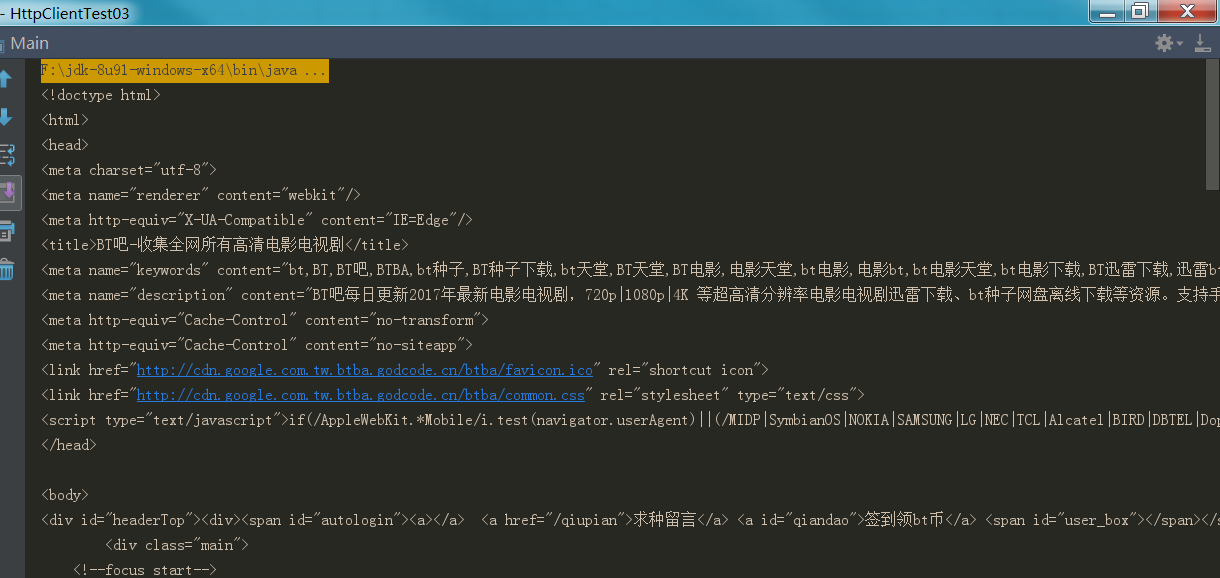
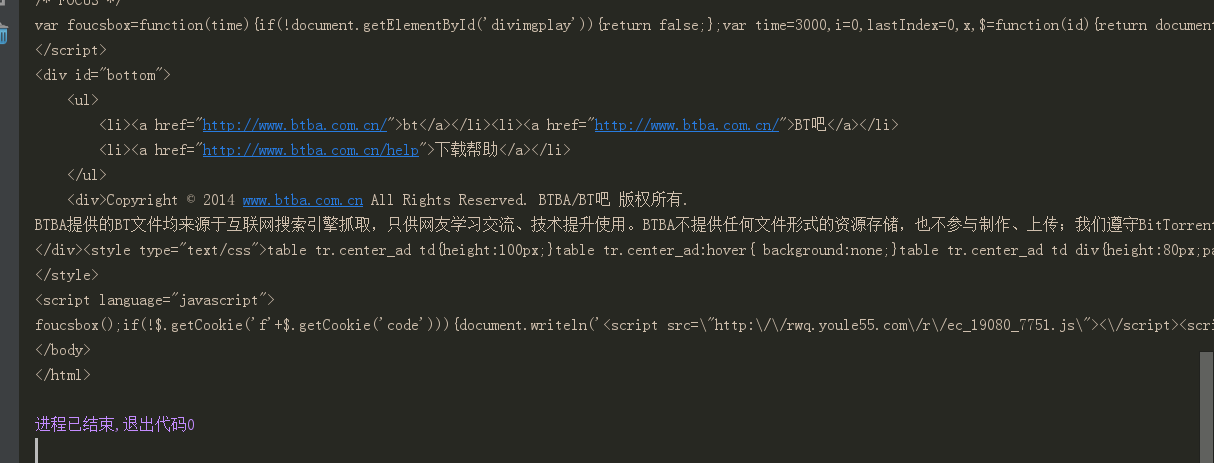
下面提供了HttpClient的下载: http://hc.apache.org/downloads.cgi
webmagic基于HttpClient、Jsoup 所以,现将这两个学会了、学懂了在去尝试啃webmagic吧
下一篇讲Jsoup对于本篇下载网页的简单解析处理。。。
本人还是小白一只,以上有什么不足或者不对之处请指出,非常感谢个位。
基于apache —HttpClient的小爬虫获取网页内容的更多相关文章
- 基于apache httpclient 调用Face++ API
简要: 本文简要介绍使用Apache HttpClient工具调用旷世科技的Face API. 前期准备: 依赖包maven地址: <!-- https://mvnrepository.com/ ...
- 基于apache httpclient的常用接口调用方法
现在的接口开发,大部分是基于http的请求和处理,现在整理了一份常用的调用方式工具类 package com.xh.oms.common.util; import java.io.BufferedRe ...
- Python实现简单的爬虫获取某刀网的更新数据
昨天晚上无聊时,想着练习一下Python所以写了一个小爬虫获取小刀娱乐网里的更新数据 #!/usr/bin/python # coding: utf-8 import urllib.request i ...
- 基于HttpClient、Jsoup的爬虫获取指定网页内容
不断尝试,发现越来越多有趣的东西,刚刚接触Jsoup感觉比正则表达式用起来方便,但也有局限只适用HTML的解析. 不能尝试运用到四则运算中(工作室刚开始联系的小程序). 在原来写的HttpClient ...
- 基于HttpClient实现网络爬虫~以百度新闻为例
转载请注明出处:http://blog.csdn.net/xiaojimanman/article/details/40891791 基于HttpClient4.5实现网络爬虫请訪问这里:http:/ ...
- 放养的小爬虫--京东定向爬虫(AJAX获取价格数据)
放养的小爬虫--京东定向爬虫(AJAX获取价格数据) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wang/Sp ...
- 新旧apache HttpClient 获取httpClient方法
在apache httpclient 4.3版本中对很多旧的类进行了deprecated标注,通常比较常用的就是下面两个类了. DefaultHttpClient -> CloseableHtt ...
- 使用selenium和phantomJS浏览器获取网页内容的小演示
# 使用selenium和phantomJS浏览器获取网页内容的小演示 # 导入包 from selenium import webdriver # 使用selenium库里的webdriver方法调 ...
- Python 基于学习 网络小爬虫
<span style="font-size:18px;"># # 百度贴吧图片网络小爬虫 # import re import urllib def getHtml( ...
随机推荐
- 【Python3 爬虫】02_利用urllib.urlopen向百度翻译发送数据并返回结果
上一节进行了网页的简单抓取,接下来我们详细的了解一下两个重要的参数url与data urlopen详解 urllib.request.urlopen(url, data=None, [timeout, ...
- 《深入PHP:面向对象、模式与实践》(二)
第4章 高级特性 本章内容提要: 静态属性和方法:通过类而不是对象来访问数据和功能 抽象类和接口:设计和实现分离 错误处理:异常 Final类和方法:限制继承 拦截器方法:自动委托 析构方法:对象销毁 ...
- lucene 加速索引建立速度
加速 lucene 索引建立速度 ImproveIndexingSpeed
- Cookie的增删改查
增加: 第一种方法:Response.Cookies[“UserName”].Value=”张三” Response.Cookies[“UserName”].Expires=DateTime.Now. ...
- 轻量级代码生成器-OnlyCoder 第一篇
程序猿利器:代码生成器,使用代码生成器已经好几年了,增删改查各种生成,从UI到DATA层均生成过.之前有使用过动软的,T4模板等.... T4生成实体还是没有问题的,但是生成MVC视图就有点烦杂了, ...
- Xilinx DDR3 IP核使用问题汇总(持续更新)和感悟
一度因为DDR3的IP核使用而发狂. 后来因为解决问题,得一感悟.后面此贴会完整讲述ddr3 ip的使用.(XILINX K7) 感悟:对于有供应商支持的产品,遇到问题找官方的流程.按照官方的指导进行 ...
- NPOI读取操作excel
.读取using (FileStream stream = new FileStream(@"c:\客户资料.xls", FileMode.Open, FileAccess.Rea ...
- RPMforge(Repoforge)源
centos使用rpmforge-release 时间:2017-10-09 09:48:29 阅读:536 评论:0 收藏:0 [点我收藏+] 标签:rpmf ...
- 电脑的文件怎么拷贝复制到VMware虚拟机
我们有时候想要在电脑和虚拟机之间复制粘贴文件,当然最笨的方法是用U盘进行复制转移,但是这样也太落伍了吧,那么我们怎么利用虚拟机自带的功能,然后将电脑的文件复制拷贝到VMware虚拟机中呢?有些朋友不太 ...
- Hibernate每个具体类一张表映射(使用注释)
在每个类创建一张表的情况下, 表中不使用Null值的列. 这种方法的缺点是在子类表中创建了重复的列. 在这里,我们需要在父类中使用@Inheritance(strategy = Inheritance ...