Hadoop(10)-HDFS的DataNode详解
1.DataNode工作机制
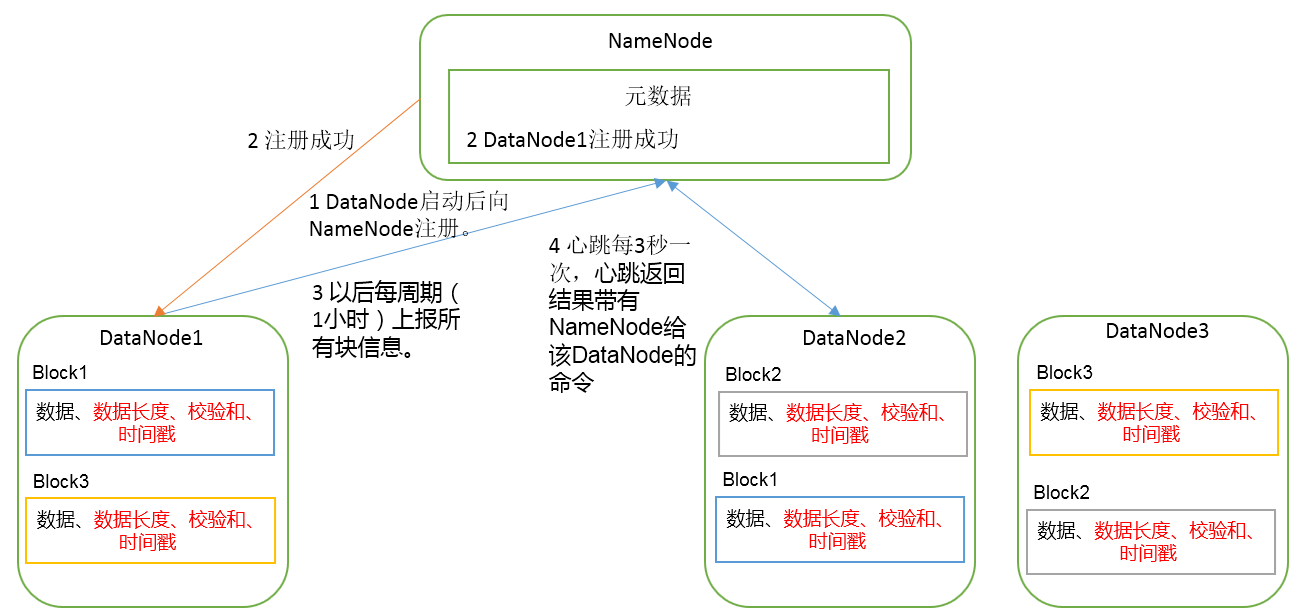
1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器
2 数据完整性
如果电脑磁盘里面存储的数据是控制高铁信号灯的红灯信号(1)和绿灯信号(0),但是存储该数据的磁盘坏了,一直显示是绿灯,是否很危险?
同理DataNode节点上的数据损坏了,却没有发现,是否也很危险,那么如何解决呢?
如下是DataNode节点保证数据完整性的方法。
1)当DataNode读取Block的时候,它会计算CheckSum。
2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
3)Client读取其他DataNode上的Block。
4)DataNode在其文件创建后周期验证CheckSum
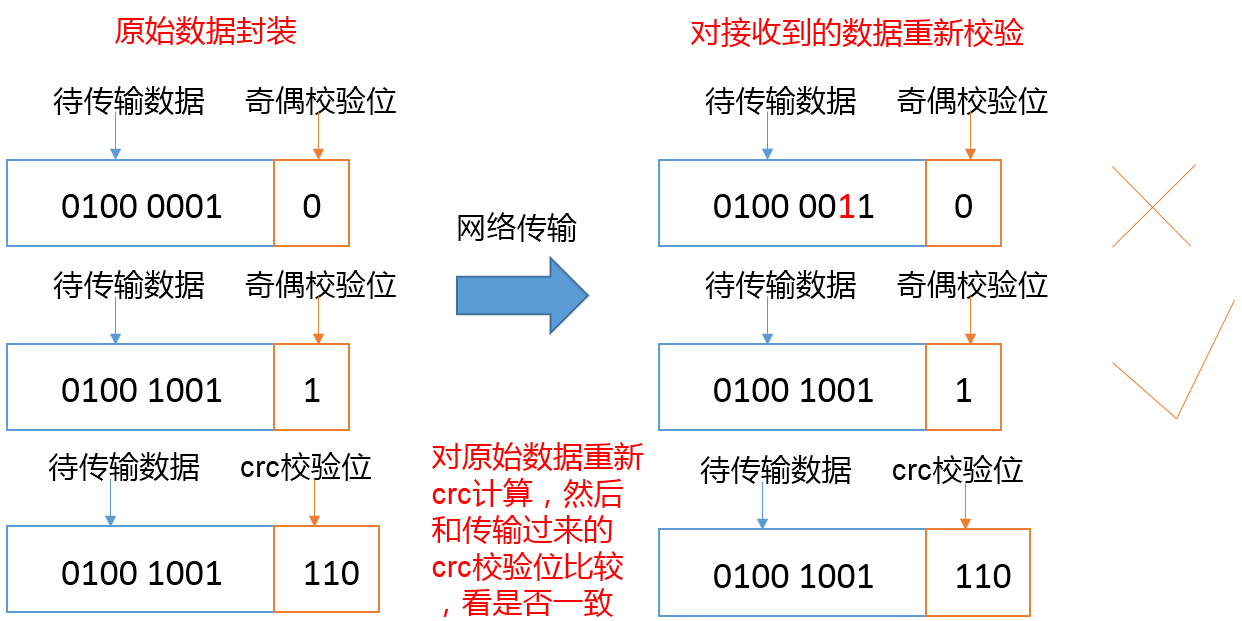
DataNode的校验法用的是crc校验,感兴趣的同学可以百度一下~
3.DataNode掉线时限
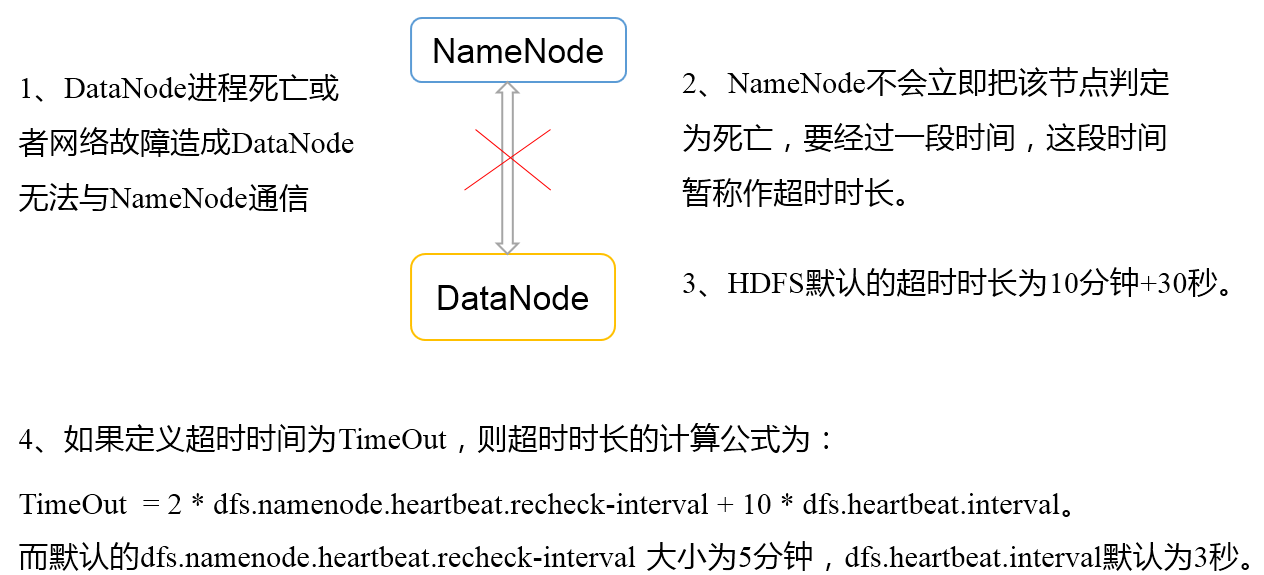
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property> <property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
Hadoop(10)-HDFS的DataNode详解的更多相关文章
- 【史上最全】Hadoop 核心 - HDFS 分布式文件系统详解(上万字建议收藏)
1. HDFS概述 Hadoop 分布式系统框架中,首要的基础功能就是文件系统,在 Hadoop 中使用 FileSystem 这个抽象类来表示我们的文件系统,这个抽象类下面有很多子实现类,究竟使用哪 ...
- Hadoop(四)HDFS集群详解
前言 前面几篇简单介绍了什么是大数据和Hadoop,也说了怎么搭建最简单的伪分布式和全分布式的hadoop集群.接下来这篇我详细的分享一下HDFS. HDFS前言: 设计思想:(分而治之)将大文件.大 ...
- HDFS体系结构(NameNode、DataNode详解)
hadoop项目地址:http://hadoop.apache.org/ NameNode.DataNode详解 (一)分布式文件系统概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配 ...
- hdfs文件系统架构详解
hdfs文件系统架构详解 官方hdfs分布式介绍 NameNode *Namenode负责文件系统的namespace以及客户端文件访问 *NameNode负责文件元数据操作,DataNode负责文件 ...
- Hadoop 新 MapReduce 框架 Yarn 详解
Hadoop 新 MapReduce 框架 Yarn 详解: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ Ap ...
- Hadoop 发行版本 Hortonworks 安装详解(一) 准备工作
一.前言 目前Hadoop发行版非常多,所有这些发行版均是基于Apache Hadoop衍生出来的,之所以有这么多的版本,完全是由Apache Hadoop的开源协议决定的:任何人可以对其进行修改,并 ...
- adoop(四)HDFS集群详解
阅读目录(Content) 一.HDFS概述 1.1.HDFS概述 1.2.HDFS的概念和特性 1.3.HDFS的局限性 1.4.HDFS保证可靠性的措施 二.HDFS基本概念 2.1.HDFS主从 ...
- Hadoop 发行版本 Hortonworks 安装详解(二) 安装Ambari
一.通过yum安装ambari-server 由于上一步我们搭建了本地源,实际上yum是通过本地源安装的ambari-server,虽然也可以直接通过官方源在线安装,不过体积巨大比较费时. 这里我选择 ...
- Hadoop生态圈-Hbase的Region详解
Hadoop生态圈-Hbase的Region详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
随机推荐
- 内存分配malloc函数注意事项。
malloc的全称是memory allocation,中文叫动态内存分配,用于向系统申请分配指定字节的内存空间 原型:extern void *malloc(unsigned int num_byt ...
- BIEE入门(三)业务模型层
正如它的名字所示(Business Model and Mapping Layer),业务逻辑层需要把物理层的数据源以一种业务用户的视角来重新组织物理层的各个数据源(所谓的Mapping),同时在业务 ...
- Struts2学习-拦截器
1.新建项目user4,建立好和user3一样的目录,与之相比只是添加几个类,主要是struts.xml和action类的改变,其结果没有太大的变化 struts,xml <?xml versi ...
- Python——追加学习笔记(三)
错误与异常 AttributeError:尝试访问未知的对象属性 eg. >>> class myClass(object): ... pass ... >>> m ...
- adb工具包使用方法
ADB工具包总共有四个文件,两个exe后缀,两个dll后缀.里面还带有fastboot.exe下载后在PC上安装,如安装到D:\adb_tools-2.0目录,确认目录中带有fastboot.exe文 ...
- 开发时复制aspx网页的方法
简单的copy /paste *.aspx网页,所使用的是同一个CodeBehind ,这往往不是我们所想要的!!!我们一般都希望使这两个网页具有各自的 *.cs文件.步骤:①新建一个Web ...
- Hybris ECP(Enterprise Commerce Platform)的调试
This blog is written to demonstrate how to setup debug environment for Hybris ECP(Enterprise Commerc ...
- ubuntu16.4安装最新版wine3.0
1.主体大致过程 $ wget https://dl.winehq.org/wine/source/3.0/wine-3.0.tar.xz $ tar -xvf wine-3.0.tar.xz $ c ...
- linux shell中 if else以及大于、小于、等于逻辑表达式介绍
在linux shell编程中,大多数情况下,可以使用测试命令来对条件进行测试,这里简单的介绍下, 比如比较字符串.判断文件是否存在及是否可读等,通常用"[]"来表示条件测试. 注 ...
- NodeJS服务器端平台实践记录
[2015 node.js learning notes]by lijun 01-note Nodejs是服务器端的javascript,是一种单线程.异步I/O.事件驱动型的javascript:其 ...