分布式服务框架 Zookeeper(二)官方介绍
ZooKeeper:为分布式应用而生的分布式协调服务
ZooKeeper是一个为分布式应用而设计的分布式的、开源的协调服务。它提供了一套简单的原语,分布式应用利用这套原语可以实现更高层的服务,比如一致性,配置维护,分组以及命名。它被设计为易于编程,并且采用了一套和文件系统的树形结构相似的数据模型。它在Java虚拟机上运行,并且同时绑定了Java和C。
协调服务是出了名的难以获取。在竞态条件以及死锁的时候尤其容易出错。推动ZooKeeper发展的动力是为了使分布式应用不用承受从底层开始构建协调服务的痛苦过程。
设计目标
ZooKeeper是简洁的。ZooKeeper允许分布式进程通过一个类似于标准文件系统的共享分层命名空间来彼此协调。命名空间包括数据注册——在ZooKeeper的术语中被称为znodes——它们就像是文件和目录一样。和标准的文件系统为了存储数据不一样的是,ZooKeeper的数据是存储在内存中的,这意味ZooKeeper能获得更高的吞吐量以及更低的延迟。
ZooKeeper的实现注重于高性能,高可用,严格的顺序访问。ZooKeeper的高性能使得它可以用于大型分布式系统中。高可靠性使得它免于单点失效的危险。严格的顺序意味着在客户端上可以实现复杂的一致性原语。
ZooKeeper是备份的(replicated)。就像它所协调的分布式进程一样,ZooKeeper本身就是在多个主机上部署的,就像是合奏一样。
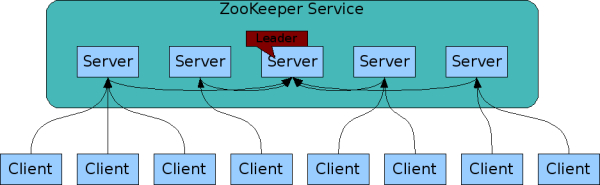
ZooKeeper服务
ZooKeeper是有序的。ZooKeeper给每次更新都会打一个戳,这个戳反映了ZooKeeper所有事物的顺序。后续的操作可以用这个顺序来实现更高层的抽象,比如一致性原语。
ZooKeeper是高速的。它在”以读为主“的负载中尤其快。ZooKeeper应用可以在数千台机器上运行,它在读比写更频繁的场景(读写比例大概是10:1)中性能是最好的。
数据模型和分层命名空间
ZooKeeper提供的命名空间就像是标准的文件系统一样。一个名字是以斜线(/)分隔的路径序列。在ZooKeeper命名空间中的每个节点都通过一个路径标识。
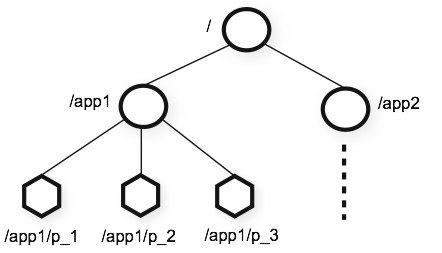
ZooKeeper的分层命名空间
节点和临时节点
和标准的文件系统不一样的是,在ZooKeeper命名空间中的每个节点有和它相关的数据和子节点。就像是允许文件系统中的可以同时是目录。(ZooKeeper被设计用于存储协调数据:状态信息,配置,本地信息等,因此每个节点中存储的数据通常都很小,范围在byte到kb之间。)我们用术语znode来表明我们谈论的是ZooKeeper中的数据节点。
znode中维护了一个包含数据改变,ACL改变以及时间戳的版本号的统计结构,并将其用于缓存验证以及协调更新。每次znode中的数据改变时,版本号就会增加。例如,在客户端取回数据的同时也会数据的版本信息。
命名空间中的每个znode上存储的数据都是以原子的方式读和写的。读操作获取和一个znode相关的所有数据,而写操作则会替换掉所有的数据。每个节点都有一个权限控制列表(ACL)来限制每个人可以做些什么。
ZooKeeper也有所谓的临时节点。这些节点只有在创建这些节点存在的时候才会存活。当会话结束的时候,这些节点就会被删除。临时节点在你想实现【tbd】的时候非常有用。
条件更新和监视
ZooKeeper支持监视的概念。客户端可以在一个znode上设置一个监视。当znode发生改变时,监视会被触发和移除。当监视触发的时候客户端会接收一个数据包表明znode已经发生变化了。并且如果在客户端和某个ZooKeeper服务器断开连接的时候,客户端将会接收到一个本地通知。这些特性可以用于【tbd】。
保障
ZooKeeper非常快速和简洁。由于它的目标是用于构建更加复杂的服务,例如一致性,所以他提供了一套保障。分别是:
序列化一致性:客户端发送的更新操作将会以发送顺序来执行。
原子性:更新要么成功,要么失败,没有多余的结果。
单一系统镜像:一个客户端将会看到同一的服务试图,不管它连接的是哪个服务器。
可靠性:一旦更新被执行,之后会持久保存下来直到有新的客户端发送新的覆盖更新。
及时性:系统的客户端视图在一定的时间范围内可以保证达到最新状态。
简单的API
ZooKeeper的设计目标之一就是提供简单的编程接口。因此,它仅仅提供如下的操作:
create:在树的某个位置创建一个节点
delete:删除一个节点
exists:测试在某个位置是否有一个节点
get data:读取一个节点上的数据
set data:向一个节点写入数据
get children:获取一个节点的子节点列表
sync:等待数据的传播
想要更加深入的讨论以及它们如何用于实现更高层的操作请参考【tbd】。
实现
ZooKeeper组件展示了ZooKeeper的高层组件。除了请求处理器,每个服务器都可以通过复制每个组件本身来构建。(马丹,就是请求处理器只能有一个,其他的组件都可以有多份。)
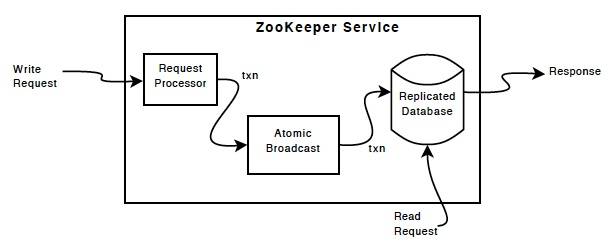
ZooKeeper组件
复制的数据库是一个包含了整个数据树的内存数据库。为了可恢复性,更新操作都会被记录到磁盘中,并且写操作在应用于内存数据库之前会先序列化到磁盘中。
每个ZooKeeper服务器都可以为客户端提供服务。客户端只会和一个服务器连接来提交请求。读请求可以从每个服务器的数据库中本地备份提供。更改服务状态的请求,比如写请求,会通过一个agreement协议来执行。
agreement协议规定所有的客户端发出写请求都会发送到一个单个服务器中,这个服务器称之为leader。剩下的服务器被称之为followers,follower会从leader那儿接受消息处理并同意消息发送。消息层会小心地替换失效的leader以及通过leader来同步所有的followers。
ZooKeeper使用私有的原子消息协议。由于消息层是原子的,ZooKeeper可以保证本地的备份不会出现分歧。当leader接收到了一个写请求,它会计算出当写操作执行之后系统的状态是什么,并且转移到补货新状态的事务中。
使用
ZooKeeper的编程接口故意设计的很简单。但是有了它之后,你可以实现更高阶的操作,比如一致性原语,分组关系,所有关系等。
性能和可靠性
树新风的我就不写了。
ZooKeeper项目
ZooKeeper已经成功应用于多个企业级项目。它在最开被用于Yahoo!的Yahoo! Message Broker的协调以及故障恢复中,Yahoo! Message Broker是一个高度可伸缩的发布-订阅系统,管理着数以千计的topics的备份和数据发送。它被用于Yahoo!爬虫的Fetching Service中,管理失效的恢复。有很多Yahoo!的广告系统同样使用ZooKeeper来实现可靠的服务。
notoriously 出了名的,臭名昭著的
prone
parlance
puts a premium on
ephemeral
diverge
deliberately
分布式服务框架 Zookeeper(二)官方介绍的更多相关文章
- 分布式服务框架 Zookeeper — 管理分布式环境中的数据
本节本来是要介绍ZooKeeper的实现原理,但是ZooKeeper的原理比较复杂,它涉及到了paxos算法.Zab协议.通信协议等相关知识,理解起来比较抽象所以还需要借助一些应用场景,来帮我们理解. ...
- 分布式服务框架 Zookeeper(转)
分布式服务框架 Zookeeper -- 管理分布式环境中的数据 Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题 ...
- 大数据 --> 分布式服务框架Zookeeper
分布式服务框架 Zookeeper Zookeeper系列 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
- 分布式服务框架 Zookeeper(一)介绍
一.概述 ZooKeeper(动物园管理员),顾名思义,是用来管理Hadoop(大象).Hive(蜜蜂).Pig(小猪)的管理员,同时Apache Hbase.Apache Solr.LinkedIn ...
- 分布式服务框架Zookeeper
协议介绍 zookeeper协议分为两种模式 崩溃恢复模式和消息广播模式 崩溃恢复协议是在集群中所选举的leader 宕机或者关闭 等现象出现 follower重新进行选举出新的leader 同时集群 ...
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/index.html Zookeeper 分布式服务框架是 Apa ...
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据(转载)
本文转载自:http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/ Zookeeper 分布式服务框架是 Apache Had ...
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据--转载
原文:http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/ Zookeeper 分布式服务框架是 Apache Hadoop ...
- 【Zookeeper】分布式服务框架 Zookeeper -- 管理分布式环境中的数据
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群管理.分布式应用配置项的管理 ...
- 【转】分布式服务框架 Zookeeper -- 管理分布式环境中的数据
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群管理.分布式应用配置项的管理 ...
随机推荐
- Exercise01_03
public class TuAn{ public static void main(String[] args){ System.out.println(" J A V V A" ...
- 《深入理解Spark-核心思想与源码分析》(一)总体规划和第一章环境准备
<深入理解Spark 核心思想与源码分析> 耿嘉安著 本书共计486页,计划每天读书20页,计划25天完成. 2018-12-20 1-20页 凡事豫则立,不豫则废:言前定,则不跲:事 ...
- javolution-core-java-6.1.0.jar 的使用
官方网址:http://javolution.org/apidocs/javolution/io/Struct.html 第一步:导包 第二步:创建继承的结构体 结构体定义如下所示: public c ...
- 如何在debug模式下,使用正式的签名文件
有两种方式(在集成第三方库的使用 使用的非常多) 签名配置信息 一是直接按F4,在项目结构面板中进行设置,只要操作两个两个选项卡就好了,signing(生成配置信息)和build types(打包类 ...
- Ubuntu 16.04屏幕阅读Screen Reader导致快捷键失灵的问题解决
开启和关闭快捷键:[Alt]+[Win]+[S] 如果关了之后开机还自动启动时,那么直接把它卸载: sudo apt-get remove gnome-orca killall orca 参考: ht ...
- 基于CentOS与VmwareStation10搭建Oracle11G RAC 64集群环境:2.搭建环境-2.10.配置用户NTF服务
2.10.配置用户NTF服务 2.10.1.配置节点RAC1 1) [root@linuxrac1 sysconfig]#sed -i 's/OPTIONS/#OPTIONS/g' /etc/sysc ...
- HA分布式集群一hadoop+zookeeper
一:HA分布式配置的优势: 1,防止由于一台namenode挂掉,集群失败的情形 2,适合工业生产的需求 二:HA安装步骤: 1,安装虚拟机 1,型号:VMware_workstation_full_ ...
- 使用Faric+Git进行分布式代码管理
Fabric是一个Python库,可以通过SSH在多个host上批量执行任务. 可以通过编写任务脚本,然后通过Fabric在本地就可以使用SSH在大量远程服务器上自动运行. 这些功能非常适合应用的自动 ...
- Java虚拟机中的栈和堆的定义和区别
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配. 当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配 ...
- android: android中dip、dp、px、sp和屏幕密度
android中dip.dp.px.sp和屏幕密度 转自:http://www.cnblogs.com/fbsk/archive/2011/10/17/2215539.html 1. dip: dev ...