C / C ++ 基于梯度下降法的线性回归法(适用于机器学习)
写在前面的话:
在第一学期做项目的时候用到过相应的知识,觉得挺有趣的,就记录整理了下来,基于C/C++语言
原贴地址:https://helloacm.com/cc-linear-regression-tutorial-using-gradient-descent/
---------------------------------------------------------------前言----------------------------------------------------------------------------------
在机器学习和数据挖掘处理等领域,梯度下降(Gradient Descent)是一种线性的、简单却比较有效的预测算法。它可以基于大量已知数据进行预测, 并可以通过控制误差率来确定误差范围。
--------------------------------------------------------准备------------------------------------------------------------------------
Gradient Descent
回到主题,线性回归算法有很多,但Gradient Descent是最简单的方法之一。对于线性回归,先假设数据满足线性关系,例如:
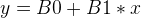
所以,作为线性回归,我们的任务就是找到最合适 B0 和 B1, 使最后的结果Y满足可接受的准确度。作为起步,首先让我们对B0和B1赋值初始值0,如下所示:
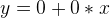
设误差 Error 为 e, 并引入下面几个点做例子:
x y
如果我们计算第一个点的误差,则得到 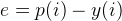 ,其中P(i)为表中的数据值,则 e 结果为 -1。但这只是开始,下面我们可以使用Gradient Descent来更新Y中的系数。这就涉及到数据 / 机器学习, 所谓的 数据 / 机器学习,其实可以大致理解为在相应的函数模型下,通过不停地更新其中系数,使新函数曲线可以拟合原始数据并预测走势的过程。
,其中P(i)为表中的数据值,则 e 结果为 -1。但这只是开始,下面我们可以使用Gradient Descent来更新Y中的系数。这就涉及到数据 / 机器学习, 所谓的 数据 / 机器学习,其实可以大致理解为在相应的函数模型下,通过不停地更新其中系数,使新函数曲线可以拟合原始数据并预测走势的过程。
回到主题,设刚才的初始状态为 t ,那么对于下一个状态 t+1 , B0可表示为 :
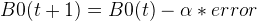
其中 B0(t + 1)是系数的更新版本,为套入下一个点做准备。∂ 是学习率,即为精度,这个我们可以自己设定。∂ 越大,说明每次学习的跨度就越大,预测结果在相应的正确答案两边的摆幅也就越大,所以此情况下学习次数不易过多,否则越摆越离谱。Ps:有次因为∂ 值太大的原因导致结果不精准,结过以为是学习次数不够多,后来等到把2.3的数值摆到10个亿才反应过来是∂出来问题。话说10个亿真是个小目标呢。
言归正传,这里取 ∂ = 0.01,即可得以下式子,B0=0.01.
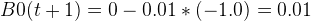 .
.
现在再来看 B1,在 t+1时刻,公式变为:
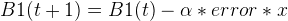
同样赋值,也同样得到:
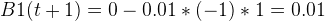
--------------------------------------------------------操作------------------------------------------------------------------------
现在,我们可以重复迭代这种过程到下一个点,再到下下个点,一直到所有点结束,这称为1回(an epoch)。但是我们可以通过反复不停地迭代,来使得到的线性拟合曲线更接近初始数据。比如迭代4回,每回5个点,也就是20次。C / C ++代码如下:
double x[] = {, , , , };
double y[] = {, , , , };
double b0 = ;
double b1 = ;
double alpha = 0.01;
for (int i = ; i < ; i ++) {
int idx = i % ; //5个点
double p = b0 + b1 * x[idx];
double err = p - y[idx];
b0 = b0 - alpha * err;
b1 = b1 - alpha * err * x[idx];
}
把B0、B1还有 误差(Error)的结果打印出来:
B0 = 0.01, B1 = 0.01, err = -
B0 = 0.0397, B1 = 0.0694, err = -2.97
B0 = 0.066527, B1 = 0.176708, err = -2.6827
B0 = 0.0805605, B1 = 0.218808, err = -1.40335
B0 = 0.118814, B1 = 0.410078, err = -3.8254
B0 = 0.123526, B1 = 0.414789, err = -0.471107
B0 = 0.143994, B1 = 0.455727, err = -2.0469
B0 = 0.154325, B1 = 0.497051, err = -1.0331
B0 = 0.157871, B1 = 0.507687, err = -0.354521
B0 = 0.180908, B1 = 0.622872, err = -2.3037
B0 = 0.18287, B1 = 0.624834, err = -0.196221
B0 = 0.198544, B1 = 0.656183, err = -1.56746
B0 = 0.200312, B1 = 0.663252, err = -0.176723
B0 = 0.198411, B1 = 0.65755, err = 0.190068
B0 = 0.213549, B1 = 0.733242, err = -1.51384
B0 = 0.214081, B1 = 0.733774, err = -0.0532087
B0 = 0.227265, B1 = 0.760141, err = -1.31837
B0 = 0.224587, B1 = 0.749428, err = 0.267831
B0 = 0.219858, B1 = 0.735242, err = 0.472871
B0 = 0.230897, B1 = 0.790439, err = -1.10393
怎么样,能发现什么?不容易看出来没关系,我们把点画下来:
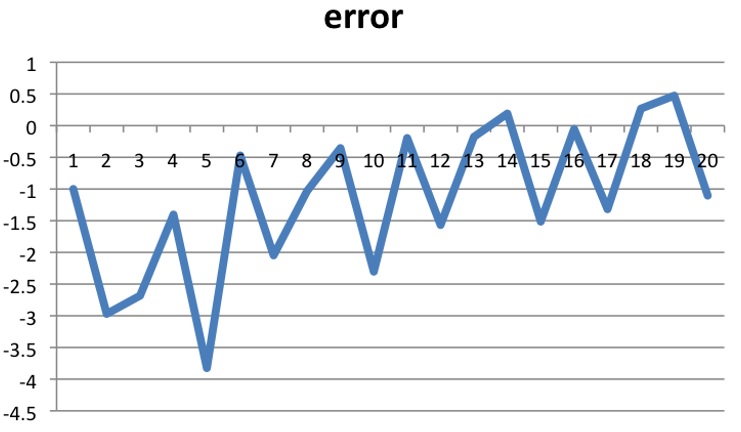
从图中,我们可以看到误差正逐渐变小,所以我们的最终模型也就是第20次的模型:
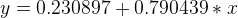
所以最后的曲线拟合结果如下:
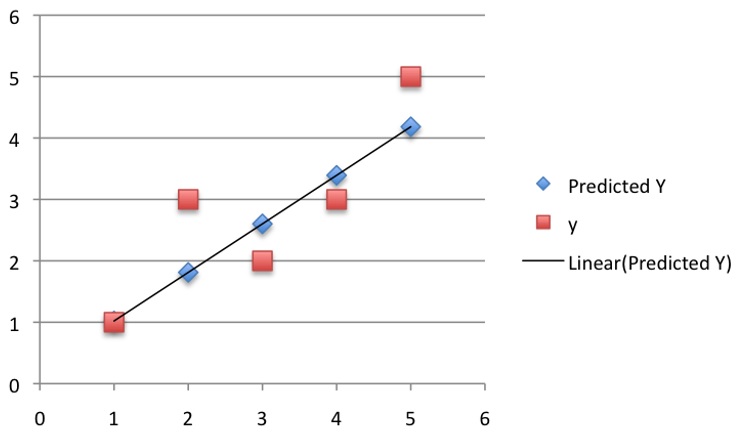
到这里其实不一定死板地局限于20次,也并不是迭代次数越多越好,因为这个过程像一个开口向下的二次函数, 适合的才是最好的。
 因为最合适的点可能就在中间,迭代太多次就跑偏了。解决这个问题可以在源代码里简单地加一个 If () 函数,当误差满足xxx时跳出循环就完事了。
因为最合适的点可能就在中间,迭代太多次就跑偏了。解决这个问题可以在源代码里简单地加一个 If () 函数,当误差满足xxx时跳出循环就完事了。
到这里应该就结束了。但原文章里多算了一次 Root-Mean-Square 值,也就是均方根,常用来分析噪声或者误差,公式如下:
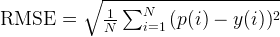 把每个点带入,得到RMSE=0.72。
把每个点带入,得到RMSE=0.72。
--------------------------------------------------------总结------------------------------------------------------------------------
其实Gradient Descent 通常适用于 量非常大且繁琐的数据(不在乎有那么几个因为跑偏而被淘汰的值)。
但如果要求数据足够精确、且数据模型复杂,不适合一次函数模型,那Gradient Descent 并不见得是一个好方法。
C / C ++ 基于梯度下降法的线性回归法(适用于机器学习)的更多相关文章
- Coursera在线学习---第一节.梯度下降法与正规方程法求解模型参数比较
一.梯度下降法 优点:即使特征变量的维度n很大,该方法依然很有效 缺点:1)需要选择学习速率α 2)需要多次迭代 二.正规方程法(Normal Equation) 该方法可以一次性求解参数Θ 优点:1 ...
- [ch04-02] 用梯度下降法解决线性回归问题
系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI, 点击star加星不要吝啬,星越多笔者越努力. 4.2 梯度下降法 有了上一节的最小二乘法做基准,我们这 ...
- tensorflow实现svm多分类 iris 3分类——本质上在使用梯度下降法求解线性回归(loss是定制的而已)
# Multi-class (Nonlinear) SVM Example # # This function wll illustrate how to # implement the gaussi ...
- tensorflow实现svm iris二分类——本质上在使用梯度下降法求解线性回归(loss是定制的而已)
iris二分类 # Linear Support Vector Machine: Soft Margin # ---------------------------------- # # This f ...
- 机器学习中梯度下降法原理及用其解决线性回归问题的C语言实现
本文讲梯度下降(Gradient Descent)前先看看利用梯度下降法进行监督学习(例如分类.回归等)的一般步骤: 1, 定义损失函数(Loss Function) 2, 信息流forward pr ...
- 最小二乘法 及 梯度下降法 分别对存在多重共线性数据集 进行线性回归 (Python版)
网上对于线性回归的讲解已经很多,这里不再对此概念进行重复,本博客是作者在听吴恩达ML课程时候偶然突发想法,做了两个小实验,第一个实验是采用最小二乘法对数据进行拟合, 第二个实验是采用梯度下降方法对数据 ...
- 梯度下降法实现最简单线性回归问题python实现
梯度下降法是非常常见的优化方法,在神经网络的深度学习中更是必会方法,但是直接从深度学习去实现,会比较复杂.本文试图使用梯度下降来优化最简单的LSR线性回归问题,作为进一步学习的基础. import n ...
- 对数几率回归法(梯度下降法,随机梯度下降与牛顿法)与线性判别法(LDA)
本文主要使用了对数几率回归法与线性判别法(LDA)对数据集(西瓜3.0)进行分类.其中在对数几率回归法中,求解最优权重W时,分别使用梯度下降法,随机梯度下降与牛顿法. 代码如下: #!/usr/bin ...
- 梯度下降法及一元线性回归的python实现
梯度下降法及一元线性回归的python实现 一.梯度下降法形象解释 设想我们处在一座山的半山腰的位置,现在我们需要找到一条最快的下山路径,请问应该怎么走?根据生活经验,我们会用一种十分贪心的策略,即在 ...
随机推荐
- 写C#代码时用到的中文简体字 、繁体字 对应的转化 (收藏吧)
简体字 下面有与之对应的繁体字 private const String Jian = "啊阿埃挨哎唉哀皑癌蔼矮艾碍爱隘鞍氨安俺按暗岸胺案肮昂盎凹敖熬翱袄傲奥懊澳芭捌扒叭吧笆疤巴拔跋靶 ...
- CTF传送门
https://www.zhihu.com/question/30505597详细见知乎 推荐书: A方向: RE for BeginnersIDA Pro权威指南揭秘家庭路由器0day漏洞挖掘技术自 ...
- Java中的锁之乐观锁与悲观锁
1. 分类一:乐观锁与悲观锁 a)悲观锁:认为其他线程会干扰本身线程操作,所以加锁 i.具体表现形式:synchronized关键字和lock实现类 b)乐观锁:认为没有其他线程会影响本身线程操作, ...
- Mysql性能调优方法
第一种方法 1.选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快.因此,在创建表的时候,为了获得更好的 性能,我们可以将表中字 ...
- 通过学生-课程关系表,熟悉hive语句
通过学生-课程关系表,熟悉hive语句 1.在hive中创建以下三个表. create table student(Sno int,Sname string,Sex string,Sage int, ...
- centOs升级
因为军佬放弃制作Centos7的网络重装包,又Centos7的安装引导和6有较大区别所以,选择曲线救国(技术不行,只能这样乱搞)前文:Centos6.9一键重装包https://ppx.ink/net ...
- ArcGIS Enterprise 10.5.1 静默安装部署记录(Centos 7.2 minimal)- 6、总结
安装小结 安装完成后,首先我们需要将Datastore托管给Server,再将Server托管给Portal以此来完成整个单机版Enterprise 部署流程.为了测试流程是否正确,我们可以采用上传一 ...
- 什么是PDM?
PDM的含义 PDM的中文名称为产品数据管理(Product Data Management). PDM是一门用来管理所有与产品相关信息(包括零件信息.配置.文档.CAD文件.结构.权限信息等)和所有 ...
- 安全隐患,你对X-XSS-Protection头部字段理解可能有误
0×00. 引言 我曾做过一个调查,看看网友们对关于X-XSS-Protection 字段的设置中,哪一个设置是最差的,调查结果令我非常吃惊,故有此文. 网友们认为 最差的配置是X-XSS-Prote ...
- 【Leetcode】【Easy】Pascal's Triangle II
Given an index k, return the kth row of the Pascal's triangle. For example, given k = 3,Return [1,3, ...