( 转 ) 优化 Group By -- MYSQL一次千万级连表查询优化
概述:
交代一下背景,这算是一次项目经验吧,属于公司一个已上线平台的功能,这算是离职人员挖下的坑,随着数据越来越多,原本的SQL查询变得越来越慢,用户体验特别差,因此SQL优化任务交到了我手上。
这个SQL查询关联两个数据表,一个是攻击IP用户表主要是记录IP的信息,如第一次攻击时间,地址,IP等等,一个是IP攻击次数表主要是记录每天IP攻击次数。而需求是获取某天攻击IP信息和次数。(以下SQL语句测试均在测试服务器上上,正式服务器的性能好,查询时间快不少。)
准备:
查看表的行数: 

未优化前SQL语句为:
SELECT
attack_ip,
country,
province,
city,
line,
info_update_time AS attack_time,
sum( attack_count ) AS attack_times
FROM
`blacklist_attack_ip`
INNER JOIN `blacklist_ip_count_date` ON `blacklist_attack_ip`.`attack_ip` = `blacklist_ip_count_date`.`ip`
WHERE
`attack_count` > 0
AND `date` BETWEEN '2017-10-13 00:00:00'
AND '2017-10-13 23:59:59'
GROUP BY
`ip`
LIMIT 10 OFFSET 1000- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
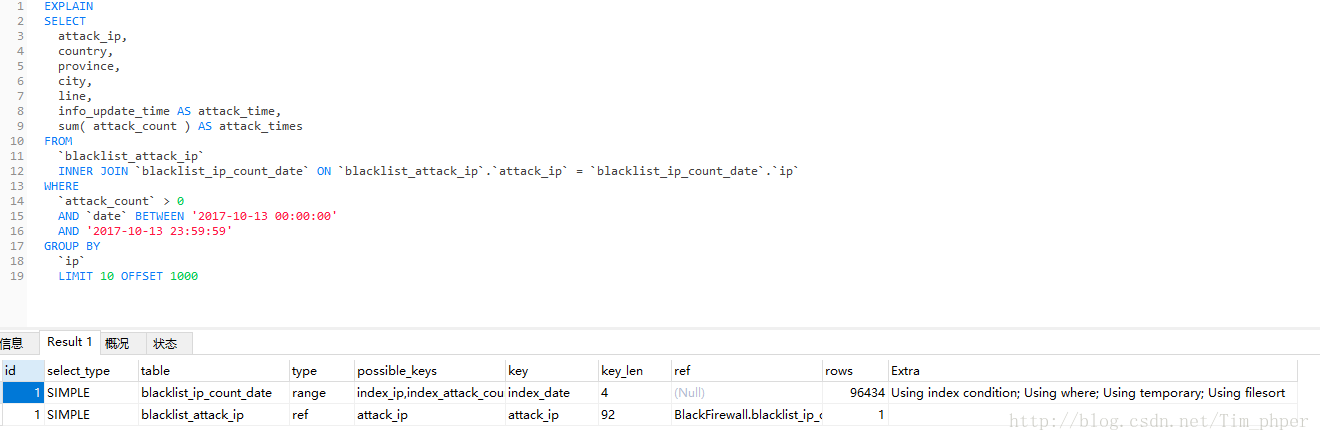
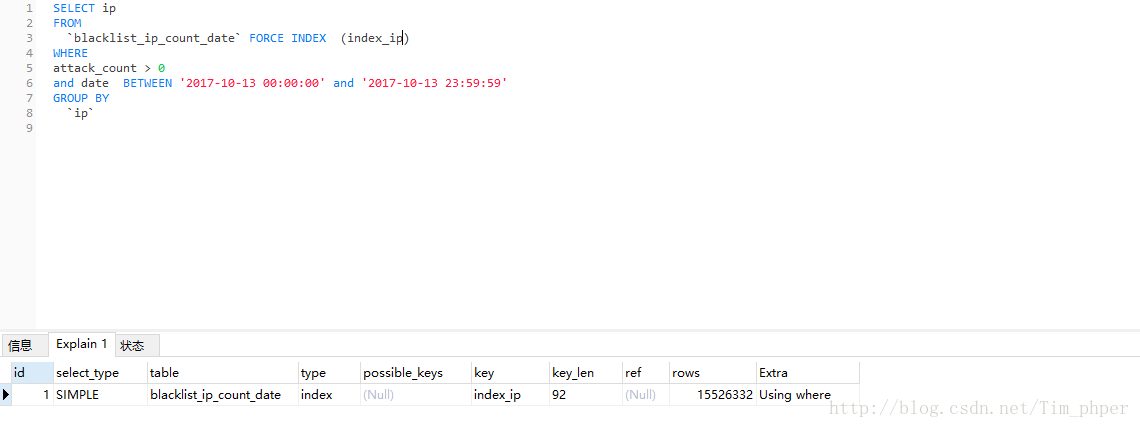
先EXPLAIN分析一下:
这里看到索引是有的,但是IP攻击次数表blacklist_ip_count_data也用上了临时表。那么这SQL不优化直接第一次执行需要多久(这里强调第一次是因为MYSQL带有缓存功能,执行过一次的同样SQL,第二次会快很多。)
实际查询时间为300+秒,这完全不能接受呀,这还是没有其他搜索条件下的。
那么我们怎么优化呢,索引既然走了,我尝试一下避免临时表,这时我们先了解一下临时表跟group by的使联系:
查找了网上一些博客分析GROUP BY 与临时表的关系 :
1. 如果GROUP BY 的列没有索引,产生临时表.
2. 如果GROUP BY时,SELECT的列不止GROUP BY列一个,并且GROUP BY的列不是主键 ,产生临时表.
3. 如果GROUP BY的列有索引,ORDER BY的列没索引.产生临时表.
4. 如果GROUP BY的列和ORDER BY的列不一样,即使都有索引也会产生临时表.
5. 如果GROUP BY或ORDER BY的列不是来自JOIN语句第一个表.会产生临时表.
6. 如果DISTINCT 和 ORDER BY的列没有索引,产生临时表.
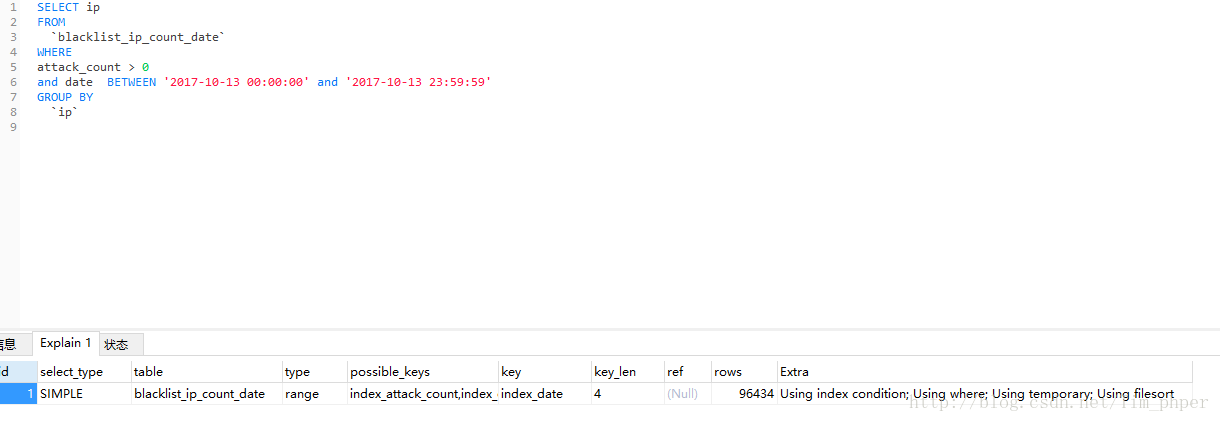
仔细按照上面分析一下,这SQL可能是因为第二条导致的,blacklist_ip_count_date这个表的确主键不是IP,SELECT是多列的,那么我们试试单独提出单表测试能不能避免临时表:
很遗憾,并不能避免,但是我们仔细看看这EXPLAIN 里面的KEY 分析,用的索引是date单字段的索引。这好像就是导致了第一条的问题了,相当于GROUP BY没有用索引。那么我们试试强制使用IP单字段的索引呢?
这里看来的确是索引的问题,导致了临时表啊,然而再看看ROWS的数量,原来的9W变成了1552W,这不是不是捡了芝麻掉了西瓜吗?
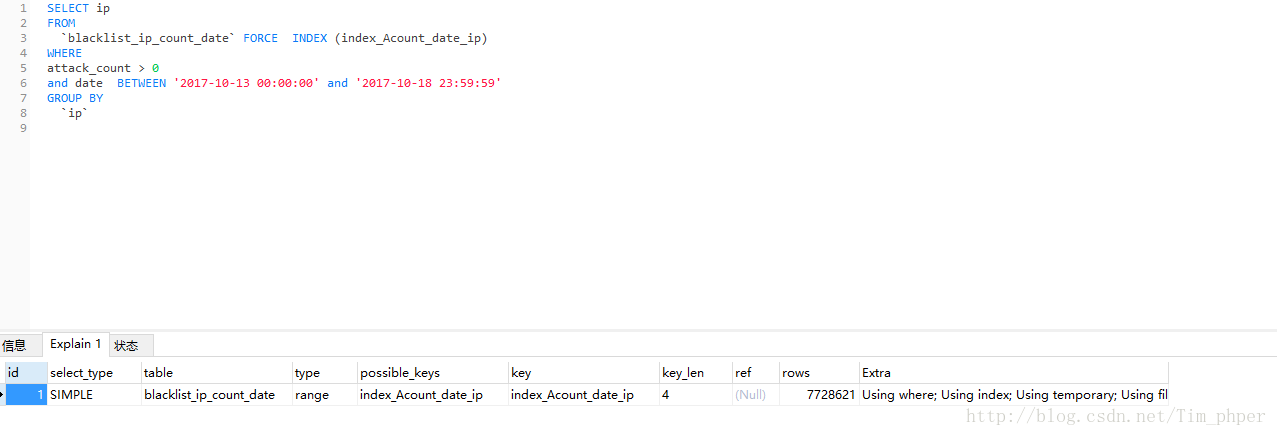
这里单列索引 避免了临时表可是联系的行数又增加了,那么我们再试试复合索引呢?
于是创建attack_count、date、ip的复合索引index_Acount_date_ip
ROWS的行数770W而且还是有临时表,看来这复合索引也是不可取。
到此,避免临时表方法失败了,我们得从其他角度想想如何优化。
其实,9W的临时表并不算多,那么为什么导致会这么久的查询呢?我们想想这没优化的SQL的执行过程是怎么样的呢?
网上搜索得知内联表查询一般的执行过程是:
1、执行FROM语句
2、执行ON过滤
3、添加外部行
4、执行where条件过滤
5、执行group by分组语句
6、执行having
7、select列表
8、执行distinct去重复数据
9、执行order by字句
10、执行limit字句- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
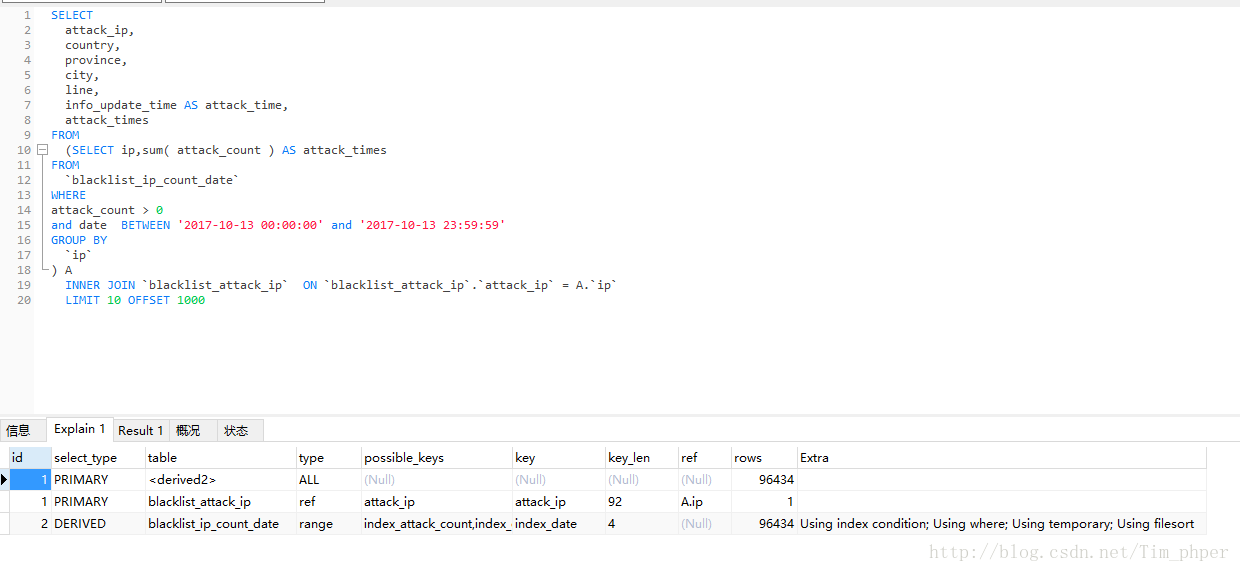
这里得知,Mysql 是先执行内联表然后再进行条件查询的最后再分组,那么想想这SQL的条件查询和分组都只是一个表的,内联后数据就变得臃肿了,这时候再进行条件查询和分组是否太吃亏了,我们可以尝试一下提前进行分组和条件查询,实现方法就是子查询联合内联查询。
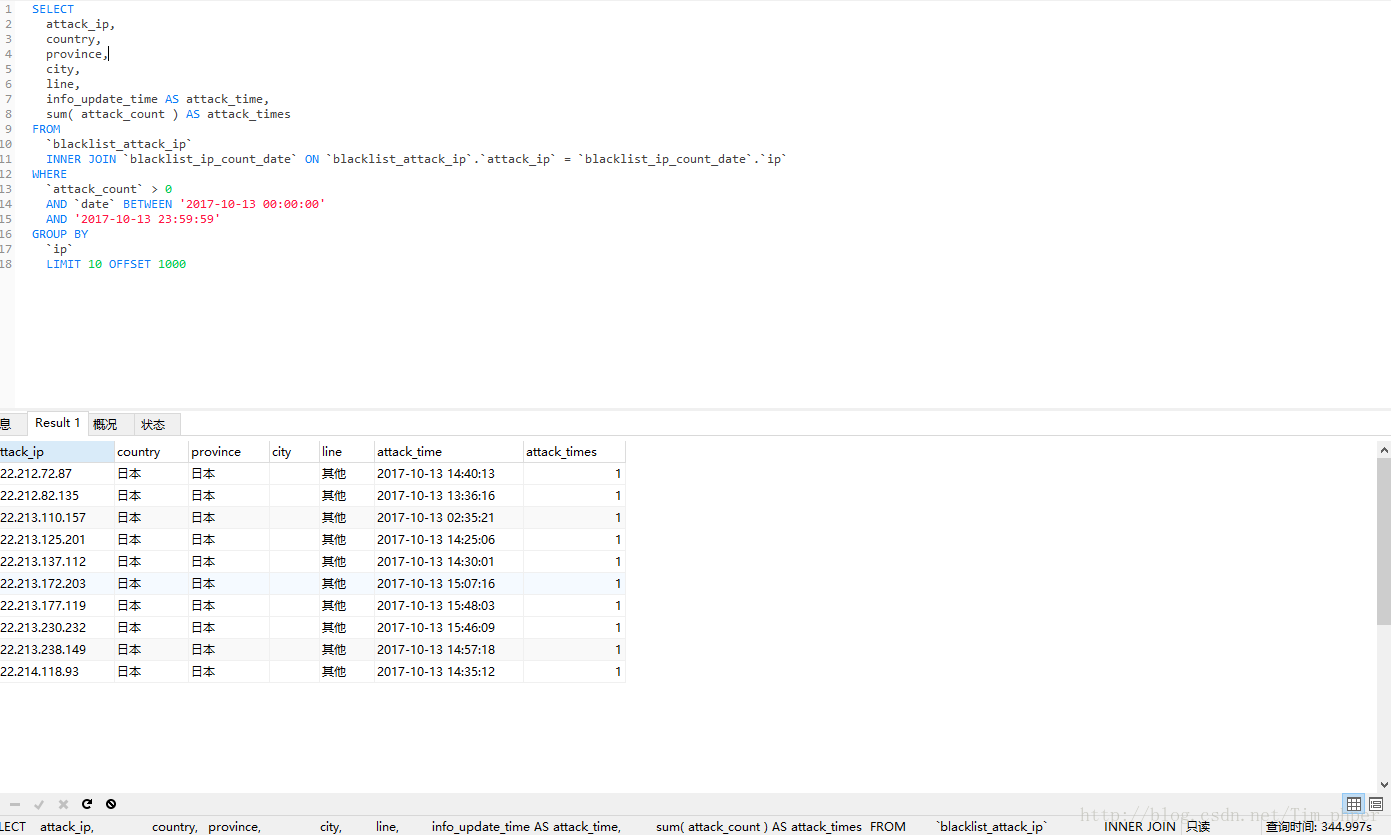
这里EXPLAIN看来,只是多了子查询,ROWS和临时表都没有变化。那么我们看看实际的效果呢?
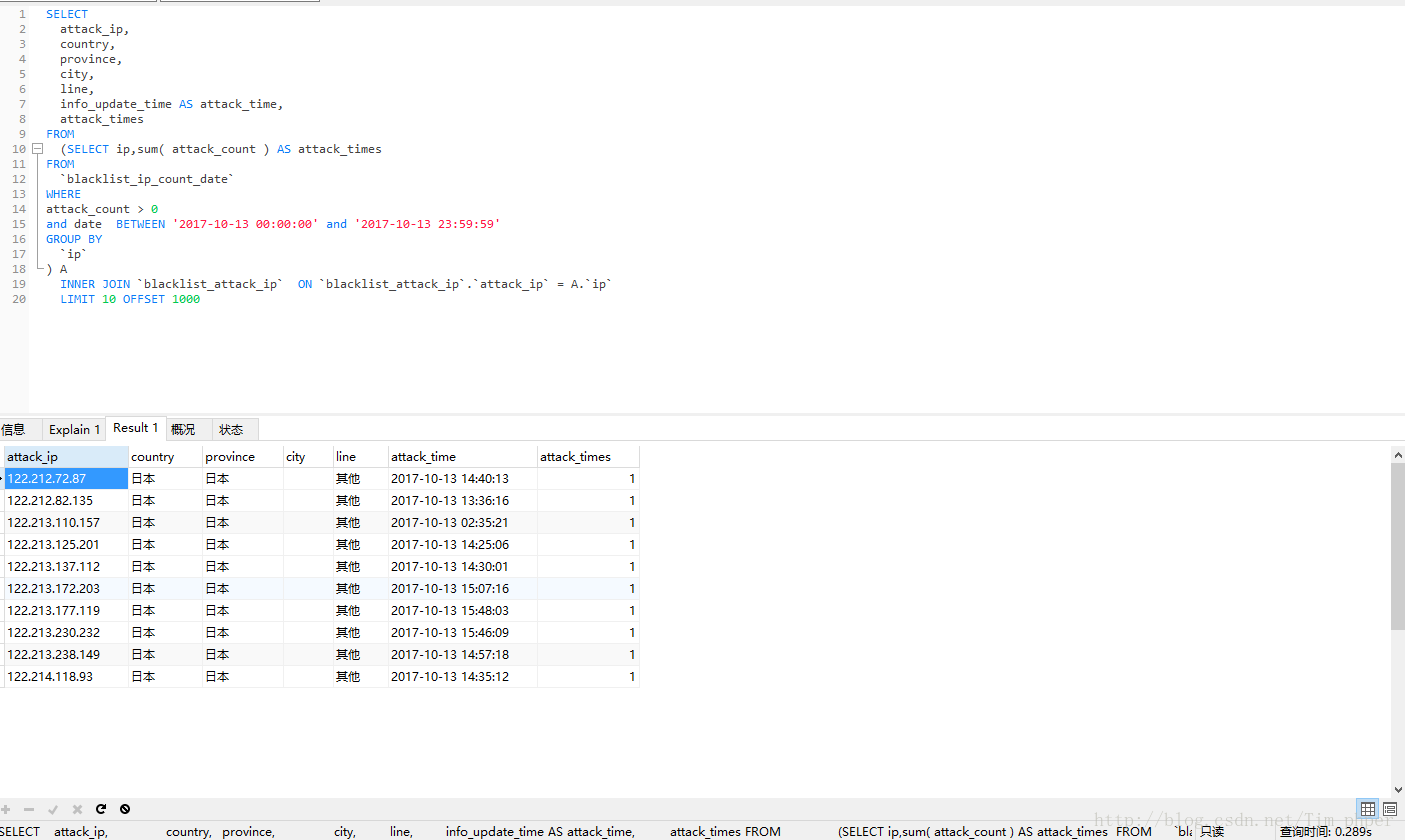
可见,取出来的数据完全一模一样,可是优化后效率从原来的330秒变成了0.28秒,这里足足提升了1000多倍的速度。这也基本满足了我们的优化需求。
估计到这里,你猜这里就是全部的优化方案?不不不,整个优化过程怎么可能只是发现一个优化方案。还有其他方案我会分开文章写,具体请查看我的下一篇文章MYSQL一次千万级连表查询优化(二)。
总结:
整个过程中我们得知,其实EXPLAIN有时候并不能指出你的SQL的所有问题,有一些隐藏问题必须要你自己思考,正如我们这个例子,看起来临时表是最大效率低的源头,但是实际上9W的临时表对MYSQL来说不足以挂齿的。我们进行内联查询前,最好能限制连的表大小的条件都先用上了,同时尽量让条件查询和分组执行的表尽量小。感谢您们的阅读,如果有更好的方案,欢迎留言交流!!!
( 转 ) 优化 Group By -- MYSQL一次千万级连表查询优化的更多相关文章
- MYSQL一次千万级连表查询优化
概述:交代一下背景,这算是一次项目经验吧,属于公司一个已上线平台的功能,这算是离职人员挖下的坑,随着数据越来越多,原本的SQL查询变得越来越慢,用户体验特别差,因此SQL优化任务交到了我手上. 这个S ...
- MYSQL一次千万级连表查询优化(二) 作为一的讲解思路
这里摘自网上,仅供自己学习之用,再次鸣谢 概述: 交代一下背景,这算是一次项目经验吧,属于公司一个已上线平台的功能,这算是离职人员挖下的坑,随着数据越来越多,原本的SQL查询变得越来越慢,用户体验特别 ...
- MYSQL一次千万级连表查询优化(一)
摘自网上学习之用 https://blog.csdn.net/Tim_phper/article/details/78344444 概述: 交代一下背景,这算是一次项目经验吧,属于公司一个已上线平台的 ...
- Mysql千万级大表优化
Mysql的单张表的最大数据存储量尚没有定论,一般情况下mysql单表记录超过千万以后性能会变得很差.因此,总结一些相关的Mysql千万级大表的优化策略. 1.优化sql以及索引 1.1优化sql 1 ...
- 如何优化MySQL千万级大表
很好的一篇博客,转载 如何优化MySQL千万级大表 原文链接::https://blog.csdn.net/yangjianrong1985/article/details/102675334 千万级 ...
- MySQL千万级大表优化解决方案
MySQL千万级大表优化解决方案 非原创,纯属记录一下. 背景 无意间看到了这篇文章,作者写的很棒,于是乎,本人自私一把,把干货保存下来.:-) 问题概述 使用阿里云rds for MySQL数据库( ...
- 在mysql数据库中制作千万级测试表
在mysql数据库中制作千万级测试表 前言: 最近准备深入的学一下mysql,包括各种引擎的特性.性能优化.分表分库等.为了方便测试性能.分表等工作,就需要先建立一张比较大的数据表.我这里准备先建一张 ...
- Oracle中创建千万级大表归纳
从一月至今,我总共归纳了三种创建千万级大表的方案,它们是: 下面是这三种方案的对比表格: # 名称 地址 主要机制 速度 1 在Oracle中十分钟内创建一张千万级别的表 https://www.cn ...
- mysql循环插入千万级数据
mysql使用存储过程循环插入大量数据,简单的一条条循环插入,效率会很低,需要考虑批量插入. 测试准备: 1.建表: CREATE TABLE `mysql_genarate` ( `id` ) NO ...
随机推荐
- [洛谷P3946] ことりのおやつ(小鸟的点心)
题目大意:最短路,第$i$个点原有积雪$h_i$,极限雪高$l_i$(即雪超过极限雪高就不可以行走),每秒降雪$q$,ことり速度为$1m/s$,若时间大于$g$,则输出$wtnap wa kotori ...
- ZOJ 3229 Shoot the Bullet | 有源汇可行流
题目: 射命丸文要给幻想乡的居民照相,共照n天m个人,每天射命丸文照相数不多于d个,且一个人n天一共被拍的照片不能少于g个,且每天可照的人有限制,且这些人今天照的相片必须在[l,r]以内,求是否有可行 ...
- BZOJ4785 [Zjoi2017]树状数组 【二维线段树 + 标记永久化】
题目链接 BZOJ4785 题解 肝了一个下午QAQ没写过二维线段树还是很难受 首先题目中的树状数组实际维护的是后缀和,这一点凭分析或经验或手模观察可以得出 在\(\mod 2\)意义下,我们实际求出 ...
- 【BZOJ 3123】 [Sdoi2013]森林 主席树启发式合并
我们直接按父子关系建主席树,然后记录倍增方便以后求LCA,同时用并查集维护根节点,而且还要记录根节点对应的size,用来对其启发式合并,然后每当我们合并的时候我们都要暴力拆小的一部分重复以上部分,总时 ...
- JavaScript渐变效果的实现
鼠标移上去透明度渐渐增加,鼠标移出,透明度渐渐减小. 关键代码: view source print? 1 var speed = 0; 2 if(target>obj.alpha){ 3 ...
- ng父组件调用子组件的方法
https://www.pocketdigi.com/20170204/1556.html 组件之间方法的调用统一用中间人调用.数据传递直接input和output即可
- hbase vs mongodb
1.HBase依赖于HDFS,HBase按照列族将数据存储在不同的hdfs文件中:MongoDB直接存储在本地磁盘中,MongoDB不分列,整个文档都存储在一个(或者说一组)文件中 (存储) 2.Mo ...
- tomcat内存配置及配置参数详解
1.jvm内存管理机制: 1)堆(Heap)和非堆(Non-heap)内存 按照官方的说法:“Java 虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配.堆是在 Java 虚拟 ...
- html与地图
html:<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <meta ...
- noip2016 普及组
T1 买铅笔 题目传送门 #include<cstdio> #include<cstring> #include<algorithm> using namespac ...