tensorflow中的学习率调整策略
通常为了模型能更好的收敛,随着训练的进行,希望能够减小学习率,以使得模型能够更好地收敛,找到loss最低的那个点.
tensorflow中提供了多种学习率的调整方式.在https://www.tensorflow.org/api_docs/python/tf/compat/v1/train搜索decay.可以看到有多种学习率的衰减策略.
- cosine_decay
- exponential_decay
- inverse_time_decay
- linear_cosine_decay
- natural_exp_decay
- noisy_linear_cosine_decay
- polynomial_decay
本文介绍两种学习率衰减策略,指数衰减和多项式衰减.
tf.compat.v1.train.exponential_decay(
learning_rate,
global_step,
decay_steps,
decay_rate,
staircase=False,
name=None
)
learning_rate 初始学习率
global_step 当前总共训练多少个迭代
decay_steps 每xxx steps后变更一次学习率
decay_rate 用以计算变更后的学习率
staircase: global_step/decay_steps的结果是float型还是向下取整
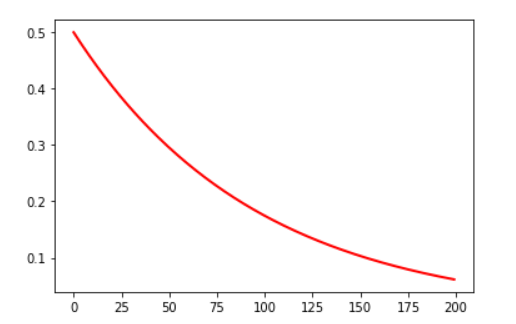
学习率的计算公式为:decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)
我们用一段测试代码来绘制一下学习率的变化情况.
#coding=utf-8
import matplotlib.pyplot as plt
import tensorflow as tf
x=[]
y=[]
N = 200 #总共训练200个迭代
num_epoch = tf.Variable(0, name='global_step', trainable=False)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for num_epoch in range(N):
##初始学习率0.5,每10个迭代更新一次学习率.
learing_rate_decay = tf.train.exponential_decay(learning_rate=0.5, global_step=num_epoch, decay_steps=10, decay_rate=0.9, staircase=False)
learning_rate = sess.run([learing_rate_decay])
y.append(learning_rate)
#print(y)
x = range(N)
fig = plt.figure()
ax.set_xlabel('step')
ax.set_ylabel('learing rate')
plt.plot(x, y, 'r', linewidth=2)
plt.show()
结果如图:
- 多项式衰减
tf.compat.v1.train.polynomial_decay(
learning_rate,
global_step,
decay_steps,
end_learning_rate=0.0001,
power=1.0,
cycle=False,
name=None
)
设定一个初始学习率,一个终止学习率,然后线性衰减.cycle控制衰减到end_learning_rate后是否保持这个最小学习率不变,还是循环往复. 过小的学习率会导致收敛到局部最优解,循环往复可以一定程度上避免这个问题.
根据cycle是否为true,其计算方式不同,如下:

#coding=utf-8
import matplotlib.pyplot as plt
import tensorflow as tf
x=[]
y=[]
z=[]
N = 200 #总共训练200个迭代
num_epoch = tf.Variable(0, name='global_step', trainable=False)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for num_epoch in range(N):
##初始学习率0.5,每10个迭代更新一次学习率.
learing_rate_decay = tf.train.polynomial_decay(learning_rate=0.5, global_step=num_epoch, decay_steps=10, end_learning_rate=0.0001, cycle=False)
learning_rate = sess.run([learing_rate_decay])
y.append(learning_rate)
learing_rate_decay2 = tf.train.polynomial_decay(learning_rate=0.5, global_step=num_epoch, decay_steps=10, end_learning_rate=0.0001, cycle=True)
learning_rate2 = sess.run([learing_rate_decay2])
z.append(learning_rate2)
#print(y)
x = range(N)
fig = plt.figure()
ax.set_xlabel('step')
ax.set_ylabel('learing rate')
plt.plot(x, y, 'r', linewidth=2)
plt.plot(x, z, 'g', linewidth=2)
plt.show()
绘图结果如下:
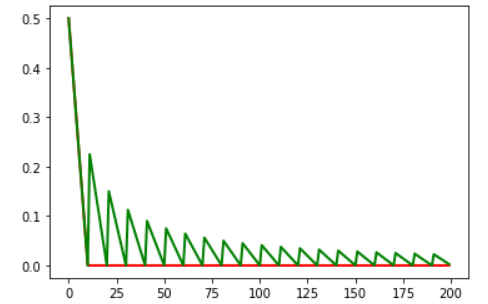
cycle为false时对应红线,学习率下降到0.0001后不再下降. cycle=true时,下降到0.0001后再突变到一个更大的值,在继续衰减,循环往复.
在代码里,通常通过参数去控制不同的学习率策略,例如
def _configure_learning_rate(num_samples_per_epoch, global_step):
"""Configures the learning rate.
Args:
num_samples_per_epoch: The number of samples in each epoch of training.
global_step: The global_step tensor.
Returns:
A `Tensor` representing the learning rate.
Raises:
ValueError: if
"""
# Note: when num_clones is > 1, this will actually have each clone to go
# over each epoch FLAGS.num_epochs_per_decay times. This is different
# behavior from sync replicas and is expected to produce different results.
decay_steps = int(num_samples_per_epoch * FLAGS.num_epochs_per_decay /
FLAGS.batch_size)
if FLAGS.sync_replicas:
decay_steps /= FLAGS.replicas_to_aggregate
if FLAGS.learning_rate_decay_type == 'exponential':
return tf.train.exponential_decay(FLAGS.learning_rate,
global_step,
decay_steps,
FLAGS.learning_rate_decay_factor,
staircase=True,
name='exponential_decay_learning_rate')
elif FLAGS.learning_rate_decay_type == 'fixed':
return tf.constant(FLAGS.learning_rate, name='fixed_learning_rate')
elif FLAGS.learning_rate_decay_type == 'polynomial':
return tf.train.polynomial_decay(FLAGS.learning_rate,
global_step,
decay_steps,
FLAGS.end_learning_rate,
power=1.0,
cycle=False,
name='polynomial_decay_learning_rate')
else:
raise ValueError('learning_rate_decay_type [%s] was not recognized' %
FLAGS.learning_rate_decay_type)
推荐一篇:https://blog.csdn.net/dcrmg/article/details/80017200 对各种学习率衰减策略描述的很详细.并且都有配图,可以很直观地看到各种衰减策略下学习率变换情况.
tensorflow中的学习率调整策略的更多相关文章
- tensorflow中常用学习率更新策略
神经网络训练过程中,根据每batch训练数据前向传播的结果,计算损失函数,再由损失函数根据梯度下降法更新每一个网络参数,在参数更新过程中使用到一个学习率(learning rate),用来定义每次参数 ...
- 【转载】 PyTorch学习之六个学习率调整策略
原文地址: https://blog.csdn.net/shanglianlm/article/details/85143614 ----------------------------------- ...
- 深度学习训练过程中的学习率衰减策略及pytorch实现
学习率是深度学习中的一个重要超参数,选择合适的学习率能够帮助模型更好地收敛. 本文主要介绍深度学习训练过程中的6种学习率衰减策略以及相应的Pytorch实现. 1. StepLR 按固定的训练epoc ...
- 史上最全学习率调整策略lr_scheduler
学习率是深度学习训练中至关重要的参数,很多时候一个合适的学习率才能发挥出模型的较大潜力.所以学习率调整策略同样至关重要,这篇博客介绍一下Pytorch中常见的学习率调整方法. import torch ...
- 【转载】 Pytorch中的学习率调整lr_scheduler,ReduceLROnPlateau
原文地址: https://blog.csdn.net/happyday_d/article/details/85267561 ------------------------------------ ...
- PyTorch学习之六个学习率调整策略
PyTorch学习率调整策略通过torch.optim.lr_scheduler接口实现.PyTorch提供的学习率调整策略分为三大类,分别是 有序调整:等间隔调整(Step),按需调整学习率(Mul ...
- TensorFlow中设置学习率的方式
目录 1. 指数衰减 2. 分段常数衰减 3. 自然指数衰减 4. 多项式衰减 5. 倒数衰减 6. 余弦衰减 6.1 标准余弦衰减 6.2 重启余弦衰减 6.3 线性余弦噪声 6.4 噪声余弦衰减 ...
- pytorch中的学习率调整函数
参考:https://pytorch.org/docs/master/optim.html#how-to-adjust-learning-rate torch.optim.lr_scheduler提供 ...
- 深度学习---1cycle策略:实践中的学习率设定应该是先增再降
深度学习---1cycle策略:实践中的学习率设定应该是先增再降 本文转载自机器之心Pro,以作为该段时间的学习记录 深度模型中的学习率及其相关参数是最重要也是最难控制的超参数,本文将介绍 Lesli ...
随机推荐
- 支撑微博亿级社交平台,小白也能玩转Redis集群(原理篇)
Redis作为一款性能优异的内存数据库,支撑着微博亿级社交平台,也成为很多互联网公司的标配.这里将以Redis Cluster集群为核心,基于最新的Redis5版本,从原理再到实战,玩转Redis集群 ...
- 某PHP发卡系统SQL注入
源码出自:https://www.0766city.com/yuanma/11217.html 安装好是这样的 审计 发现一处疑似注入的文件 地址:/other/submit.php 看到这个有个带入 ...
- 实验吧之【简单的sql注入 1、2、3】
实验吧的三道sql注入(感觉实验吧大部分web都是注入) 简单的SQL注入 地址:http://ctf5.shiyanbar.com/423/web/ 这道题也是sql注入,输入1,页面显示正常,输出 ...
- Opentracing + Uber Jaeger 全链路灰度调用链,Nepxion Discovery
当网关和服务在实施全链路分布式灰度发布和路由时候,我们需要一款追踪系统来监控网关和服务走的是哪个灰度组,哪个灰度版本,哪个灰度区域,甚至监控从Http Header头部全程传递的灰度规则和路由策略.这 ...
- 宋宝华:Docker 最初的2小时(Docker从入门到入门)
本文系转载,著作权归作者所有. 商业转载请联系作者获得授权,非商业转载请注明出处. 作者: 宋宝华 来源: 微信公众号linux阅码场(id: linuxdev) 最初的2小时,你会爱上Docker, ...
- 通过CSS3实现圆形头像显示
很久没更新博客了,因为比较菜,也没什么能在上面分享的.作为新手,马上要毕业找工作了,最近又在重新学习web的一些知识,刚刚学到CSS3,跟大家分享一些比较有趣的知识.今天分享的是利用CSS实现圆形头像 ...
- 2018.8.10 python中的迭代器
主要内容: 1.函数名的使用 2.闭包 3.迭代器 一.函数名的运用 函数名是一个变量,但他是一个特殊的变量,与括号配合可执行函数的变量. 1.函数名的内存地址 def func(): print(' ...
- spring boot项目启动报错
在eclipse中运行没有任何问题,项目挪到idea之后就报错 Unable to start EmbeddedWebApplicationContext due to miss EmbeddedSe ...
- 二:Mysql库相关操作
1:系统数据库 information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息.列信息.权限信息.字符信息等.performance_schema: My ...
- (IDEA) 设置编码统一为UTF-8
File->Settings->Editor->File Encodings