Hadoop 系列(一)—— 分布式文件系统 HDFS
一、介绍
HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。
二、HDFS 设计原理
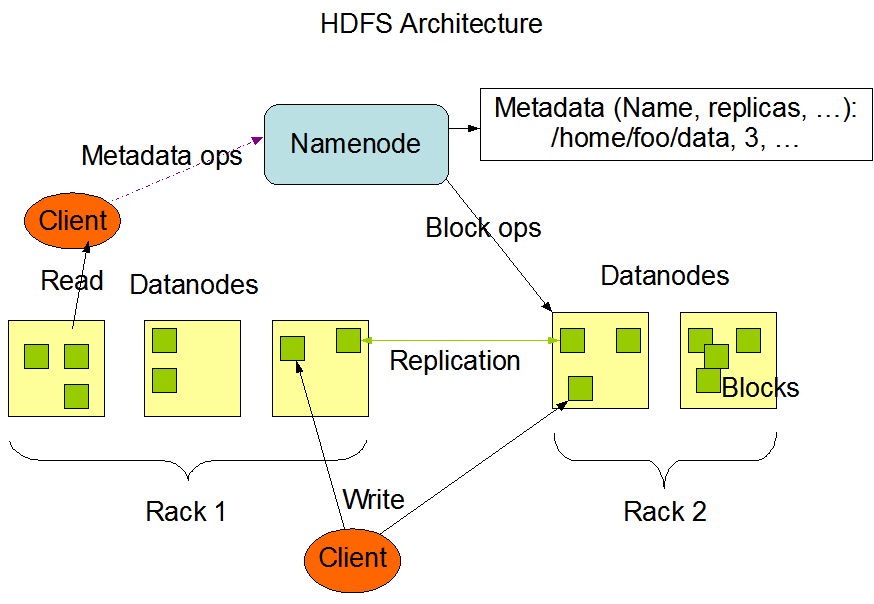
2.1 HDFS 架构
HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成:
- NameNode : 负责执行有关
文件系统命名空间的操作,例如打开,关闭、重命名文件和目录等。它同时还负责集群元数据的存储,记录着文件中各个数据块的位置信息。 - DataNode:负责提供来自文件系统客户端的读写请求,执行块的创建,删除等操作。
2.2 文件系统命名空间
HDFS 的 文件系统命名空间 的层次结构与大多数文件系统类似 (如 Linux), 支持目录和文件的创建、移动、删除和重命名等操作,支持配置用户和访问权限,但不支持硬链接和软连接。NameNode 负责维护文件系统名称空间,记录对名称空间或其属性的任何更改。
2.3 数据复制
由于 Hadoop 被设计运行在廉价的机器上,这意味着硬件是不可靠的,为了保证容错性,HDFS 提供了数据复制机制。HDFS 将每一个文件存储为一系列块,每个块由多个副本来保证容错,块的大小和复制因子可以自行配置(默认情况下,块大小是 128M,默认复制因子是 3)。
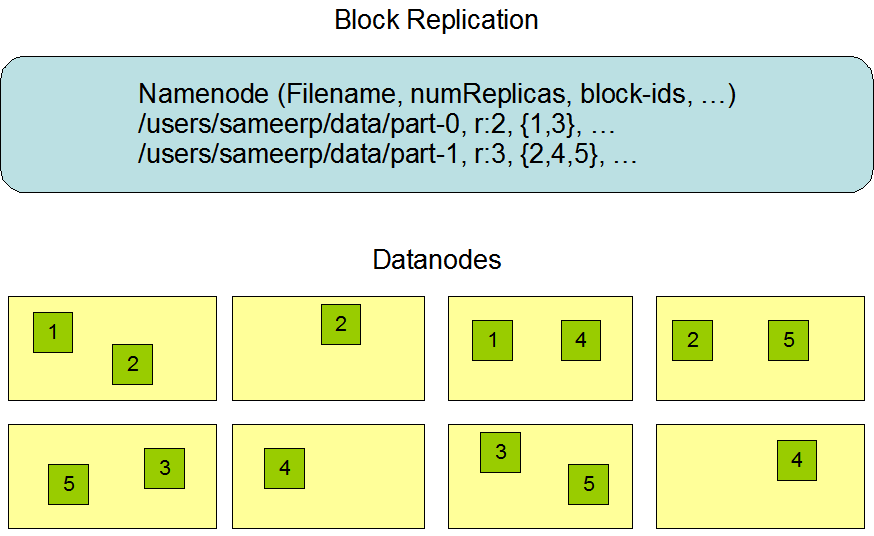
2.4 数据复制的实现原理
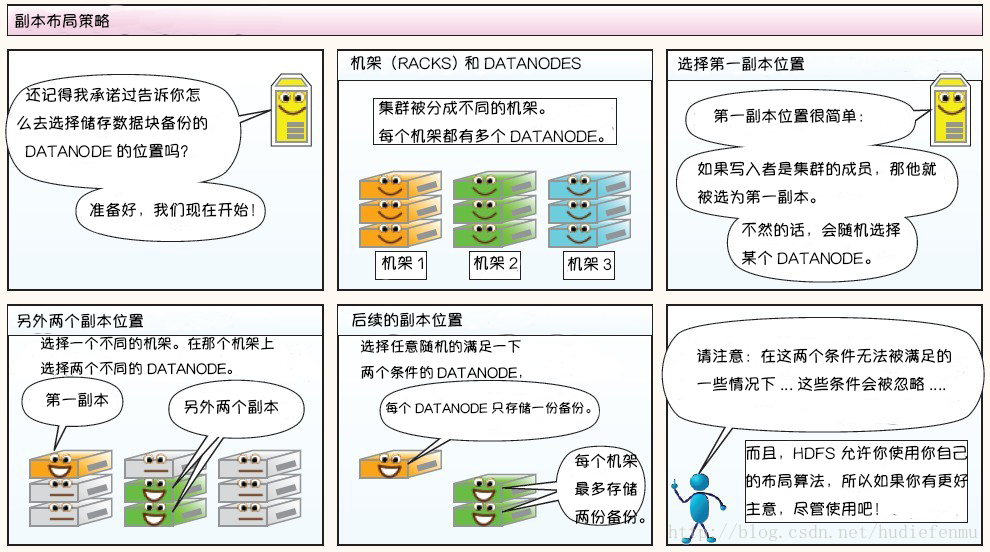
大型的 HDFS 实例在通常分布在多个机架的多台服务器上,不同机架上的两台服务器之间通过交换机进行通讯。在大多数情况下,同一机架中的服务器间的网络带宽大于不同机架中的服务器之间的带宽。因此 HDFS 采用机架感知副本放置策略,对于常见情况,当复制因子为 3 时,HDFS 的放置策略是:
在写入程序位于 datanode 上时,就优先将写入文件的一个副本放置在该 datanode 上,否则放在随机 datanode 上。之后在另一个远程机架上的任意一个节点上放置另一个副本,并在该机架上的另一个节点上放置最后一个副本。此策略可以减少机架间的写入流量,从而提高写入性能。
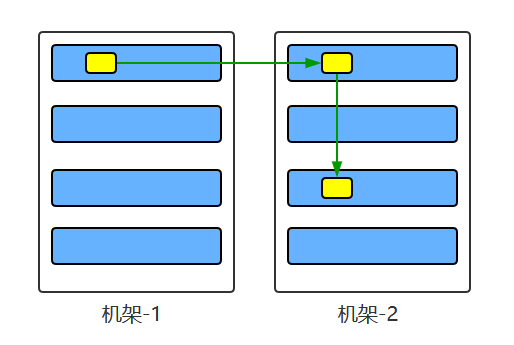
如果复制因子大于 3,则随机确定第 4 个和之后副本的放置位置,同时保持每个机架的副本数量低于上限,上限值通常为 (复制系数 - 1)/机架数量 + 2,需要注意的是不允许同一个 dataNode 上具有同一个块的多个副本。
2.5 副本的选择
为了最大限度地减少带宽消耗和读取延迟,HDFS 在执行读取请求时,优先读取距离读取器最近的副本。如果在与读取器节点相同的机架上存在副本,则优先选择该副本。如果 HDFS 群集跨越多个数据中心,则优先选择本地数据中心上的副本。
2.6 架构的稳定性
1. 心跳机制和重新复制
每个 DataNode 定期向 NameNode 发送心跳消息,如果超过指定时间没有收到心跳消息,则将 DataNode 标记为死亡。NameNode 不会将任何新的 IO 请求转发给标记为死亡的 DataNode,也不会再使用这些 DataNode 上的数据。 由于数据不再可用,可能会导致某些块的复制因子小于其指定值,NameNode 会跟踪这些块,并在必要的时候进行重新复制。
2. 数据的完整性
由于存储设备故障等原因,存储在 DataNode 上的数据块也会发生损坏。为了避免读取到已经损坏的数据而导致错误,HDFS 提供了数据完整性校验机制来保证数据的完整性,具体操作如下:
当客户端创建 HDFS 文件时,它会计算文件的每个块的 校验和,并将 校验和 存储在同一 HDFS 命名空间下的单独的隐藏文件中。当客户端检索文件内容时,它会验证从每个 DataNode 接收的数据是否与存储在关联校验和文件中的 校验和 匹配。如果匹配失败,则证明数据已经损坏,此时客户端会选择从其他 DataNode 获取该块的其他可用副本。
3.元数据的磁盘故障
FsImage 和 EditLog 是 HDFS 的核心数据,这些数据的意外丢失可能会导致整个 HDFS 服务不可用。为了避免这个问题,可以配置 NameNode 使其支持 FsImage 和 EditLog 多副本同步,这样 FsImage 或 EditLog 的任何改变都会引起每个副本 FsImage 和 EditLog 的同步更新。
4.支持快照
快照支持在特定时刻存储数据副本,在数据意外损坏时,可以通过回滚操作恢复到健康的数据状态。
三、HDFS 的特点
3.1 高容错
由于 HDFS 采用数据的多副本方案,所以部分硬件的损坏不会导致全部数据的丢失。
3.2 高吞吐量
HDFS 设计的重点是支持高吞吐量的数据访问,而不是低延迟的数据访问。
3.3 大文件支持
HDFS 适合于大文件的存储,文档的大小应该是是 GB 到 TB 级别的。
3.3 简单一致性模型
HDFS 更适合于一次写入多次读取 (write-once-read-many) 的访问模型。支持将内容追加到文件末尾,但不支持数据的随机访问,不能从文件任意位置新增数据。
3.4 跨平台移植性
HDFS 具有良好的跨平台移植性,这使得其他大数据计算框架都将其作为数据持久化存储的首选方案。
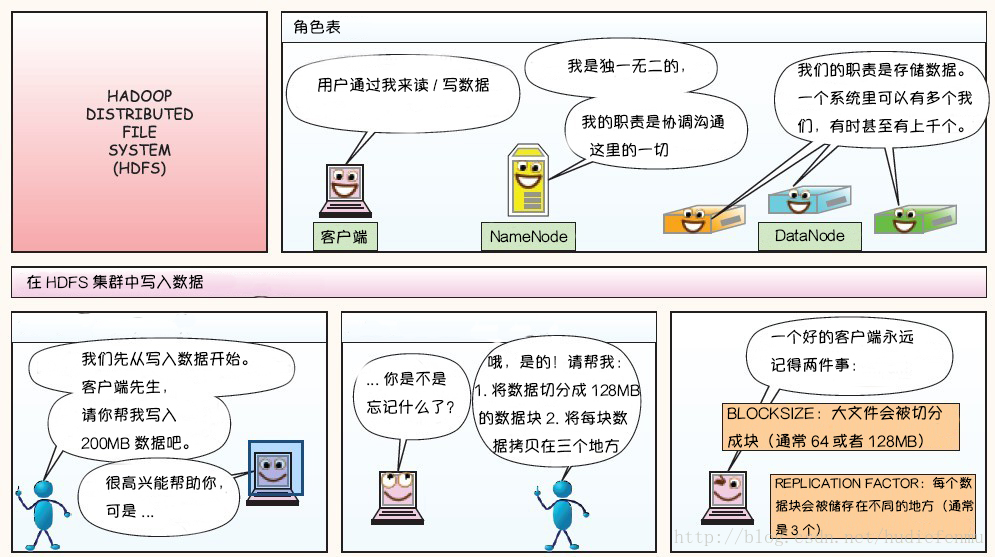
附:图解HDFS存储原理
说明:以下图片引用自博客:翻译经典 HDFS 原理讲解漫画
1. HDFS写数据原理
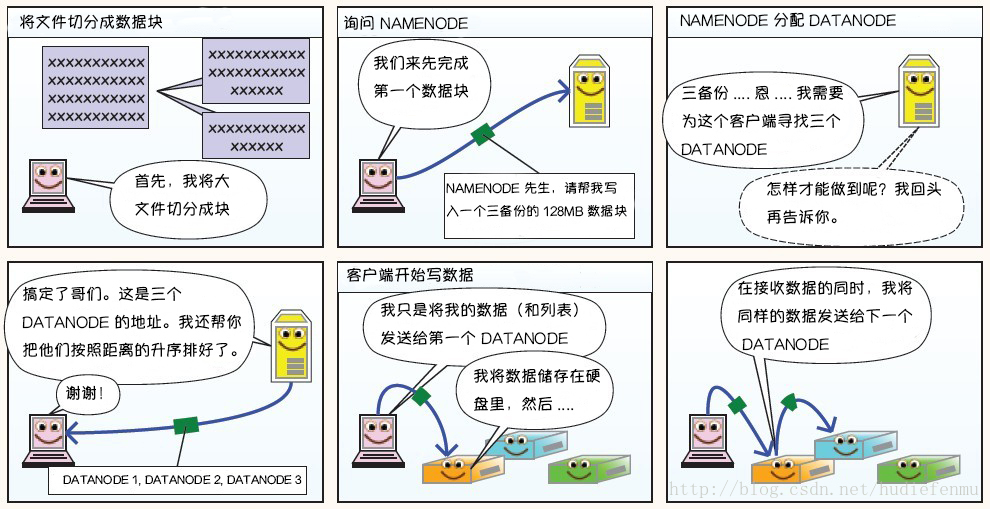
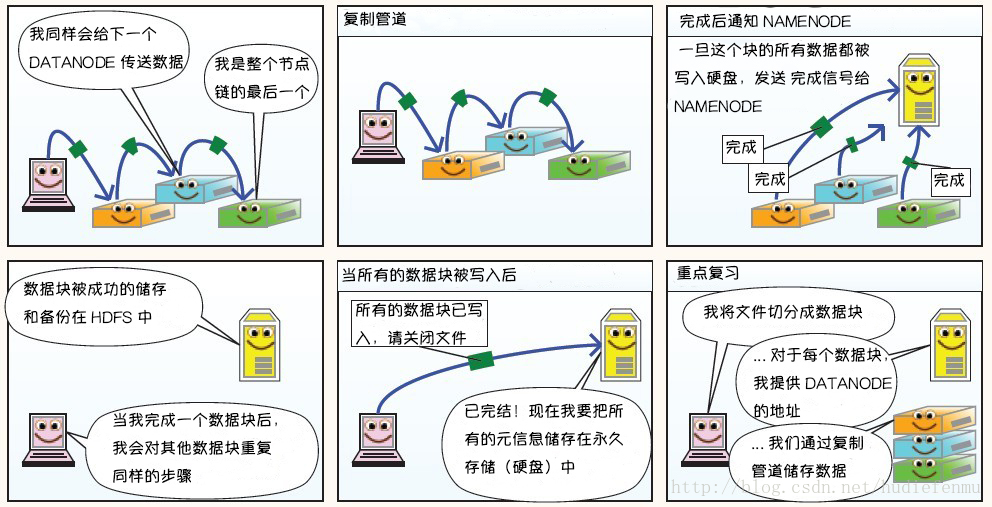
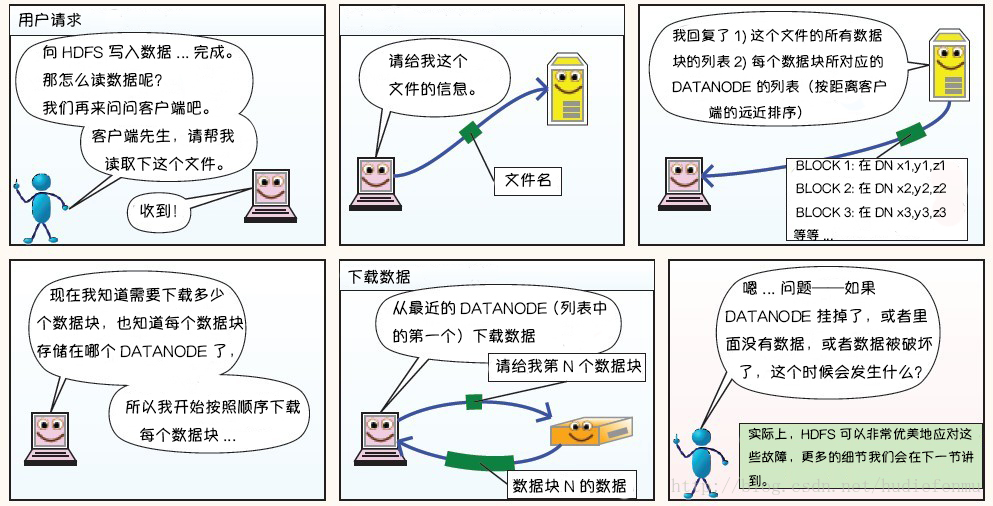
2. HDFS读数据原理
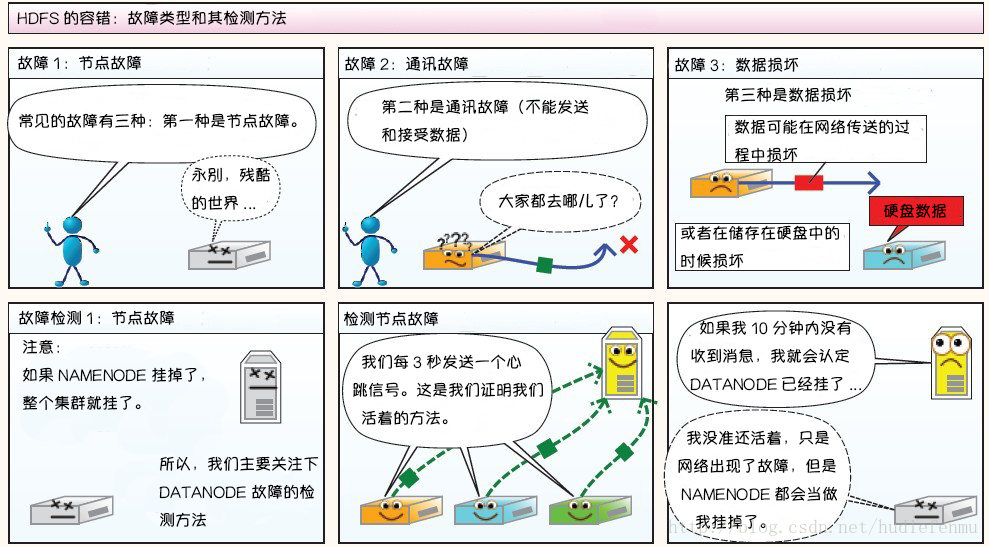
3. HDFS故障类型和其检测方法
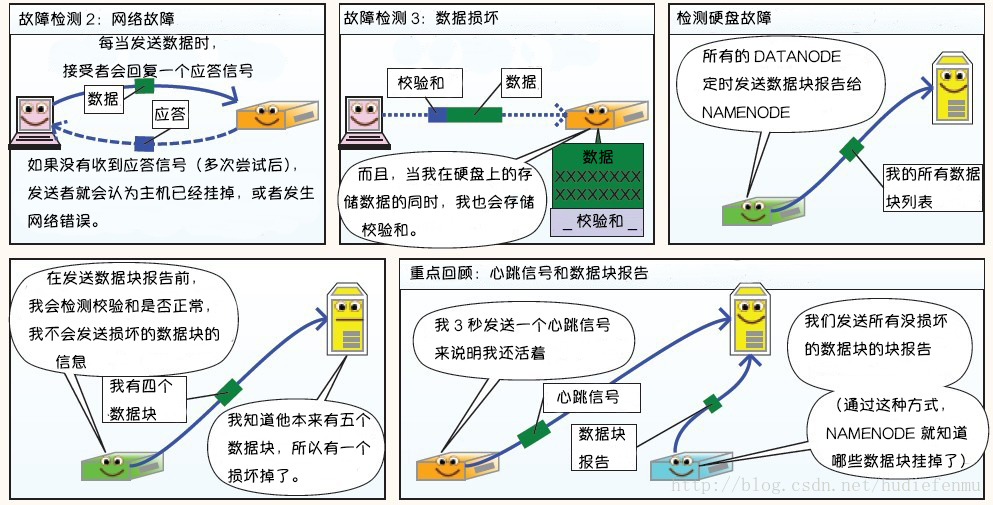
第二部分:读写故障的处理
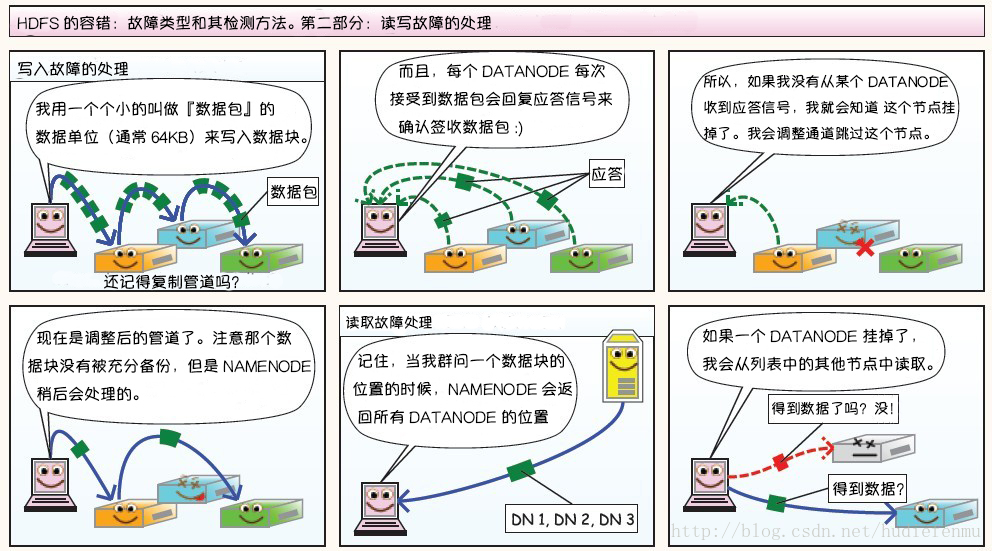
第三部分:DataNode 故障处理
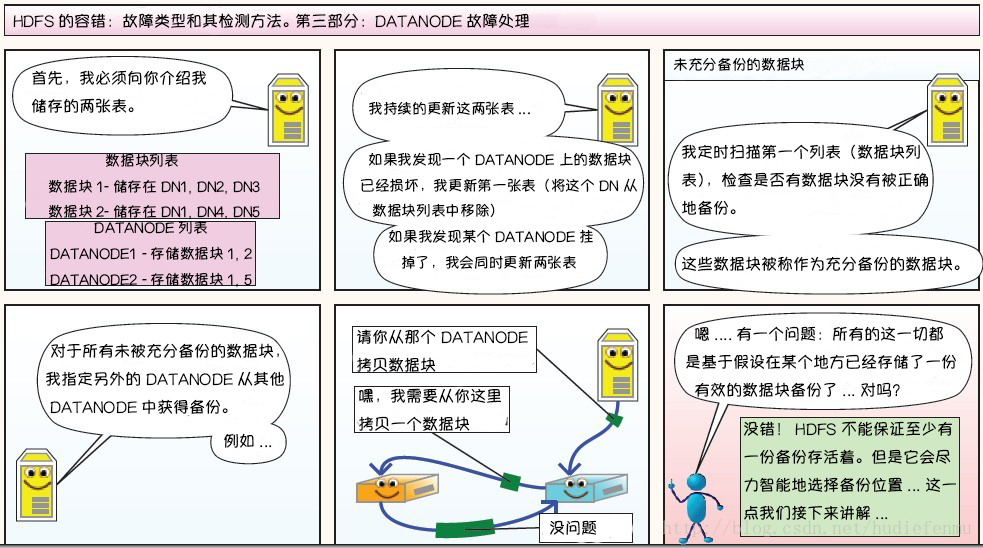
副本布局策略:
参考资料
- Apache Hadoop 2.9.2 > HDFS Architecture
- Tom White . hadoop 权威指南 [M] . 清华大学出版社 . 2017.
- 翻译经典 HDFS 原理讲解漫画
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Hadoop 系列(一)—— 分布式文件系统 HDFS的更多相关文章
- Hadoop分布式文件系统--HDFS结构分析
转自:http://blog.csdn.net/androidlushangderen/article/details/47377543 HDFS系列:http://blog.csdn.net/And ...
- Hadoop 学习之路(一)—— 分布式文件系统 HDFS
一.介绍 HDFS (Hadoop Distributed File System)是Hadoop下的分布式文件系统,具有高容错.高吞吐量等特性,可以部署在低成本的硬件上. 二.HDFS 设计原理 2 ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- 大数据技术原理与应用——分布式文件系统HDFS
分布式文件系统概述 相对于传统的本地文件系统而言,分布式文件系统(Distribute File System)是一种通过网络实现文件在多台主机上进行分布式存储的文件系统.分布式文件系统的设计一般采用 ...
- 你想了解的分布式文件系统HDFS,看这一篇就够了
1.分布式文件系统 计算机集群结构 分布式文件系统把文件分布存储到多个节点(计算机)上,成千上万的计算机节点构成计算机集群. 分布式文件系统使用的计算机集群,其配置都是由普通硬件构成的,与用多个处理器 ...
- Hadoop 分布式文件系统 - HDFS
当数据集超过一个单独的物理计算机的存储能力时,便有必要将它分不到多个独立的计算机上.管理着跨计算机网络存储的文件系统称为分布式文件系统.Hadoop 的分布式文件系统称为 HDFS,它 是为 以流式数 ...
- Hadoop概念学习系列之分布式文件系统(三十)
===============> 数据量越来越多,在一个操作系统管辖的范围存下不了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就 ...
- Hadoop分布式文件系统HDFS详解
Hadoop分布式文件系统即Hadoop Distributed FileSystem. 当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区(Partition)并 ...
随机推荐
- Codeforces Round #563 (Div. 2)B
B.Ehab Is an Odd Person 题目链接:http://codeforces.com/contest/1174/problem/B 题目 You’re given an array a ...
- VirtualBox基础使用
VirtualBox基础使用 VirtualBox相对VMware来说是轻量级的虚拟软件, 最关键的是VirtualBox是开源免费的. 配置全局选项 点击管理-->全局设定, 进入设置界面. ...
- Centos7.3搭建DNS服务器--BIND
1.系统环境说明 [root@dns-server etc]# cat /etc/redhat-release CentOS Linux release (Core) 防火墙和Selinux关闭 [r ...
- c# 开发ActiveX控件,添加事件,QT调用事件
c# 开发 ActiveX 的过程参考我的另一篇文章 : https://www.cnblogs.com/baqifanye/p/10414004.html 本篇讲如何 在C# 开发的ActiveX ...
- Maven项目读取resources下文件的路径
要取编译后的路径,而不是你看到的src/main/resources的路径.如下: URL url = 类名.class.getClassLoader().getResource("conf ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- jsp传值
是由a1.jsp发出请求然后由a2.jsp转发给ok.jsp,由ok.jsp响应a1.jsp. 但是这个转发过程是在服务端发生的,客户端不知道所以地址是不变的 转发请求的代码: request.get ...
- U盘被写保护大全解
相信大家的U盘在使用的过程中多或少都有出现过一些问题,写保护,程序写蹦而造成的逻辑错误,或者在使用过程中因电脑而中毒,内部零件损伤等等各种各样倒霉的错误. 简单了解一下是个什么东西吧.U盘写保护其实就 ...
- Bzoj 2563: 阿狸和桃子的游戏 题解
2563: 阿狸和桃子的游戏 Time Limit: 3 Sec Memory Limit: 128 MBSubmit: 970 Solved: 695[Submit][Status][Discu ...
- 20140115-SqlHelper为什么是静态的
为什么SqlHelper(或工具类)是静态的? 静态构造函数仅调用一次(即只是在程序生命周期中实例一次),在程序驻留的应用程序域的生存期内,静态类一直保留在内存中 这样可以减少每次使用的实例过程,就是 ...