Java Stream函数式编程图文详解(二):管道数据处理

一、Java Stream管道数据处理操作
在本号之前发布的文章《Java Stream函数式编程?用过都说好,案例图文详解送给你》中,笔者对Java Stream的介绍以及简单的使用方法给大家做了介绍。在开始本文之前,我们有必要介绍一下这张Java Stream 数据处理过程图,图中主要分三个部分:
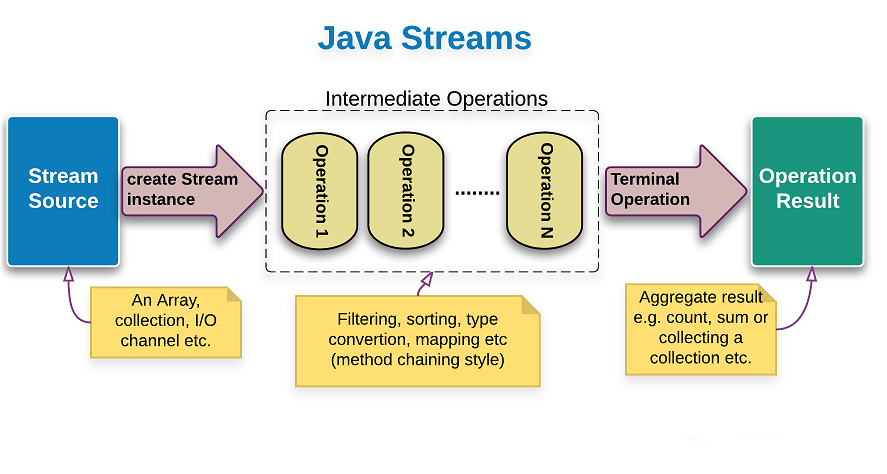
- 将数组、集合类、文本文件转换为管道流(图中的蓝色方块的部分,在本号的上一篇文章中已经给大家介绍过了)
- Java Stream管道数据处理操作(也就是下图中中间的虚线内的数据处理操作,本文的主要内容)
- 管道流处理结果的聚合、累加、计数、转换为集合类等操作(图中的绿色方块部分)
需要注意的是:Java Stream的中间数据处理操作的输入是一个管道流(Stream),输出仍然是一个管道流(Stream)。下面我们就来详细的学习一下!在上一篇文章中,我们给大家讲了这样一个例子:
List<String> nameStrs = Arrays.asList("Monkey", "Lion", "Giraffe","Lemur");
List<String> list = nameStrs.stream()
.filter(s -> s.startsWith("L"))
.map(String::toUpperCase)
.sorted()
.collect(toList());
System.out.println(list);
这个例子完成的功能就是:首先使用stream()函数将数组转换为管道流,然后对管道流中的元素进行过滤filter(),只保留L开头的元素,然后对每一个元素转换为大写(map(String::toUpperCase)),然后排序sorted(),最终转换为List类型。经过处理之后的输出结果是: [LEMUR, LION].在上面的例子中,filter()、map()、sorted()都属于中间数据处理操作,下面就给大家讲解一下这些函数的详细用法。
二、filter管道数据过滤
根据笔者的的经验,filter()是Stream API最有用的操作之一,它可以过滤掉不符合条件的元素。下面的代码过滤掉管道中的不是以L开头的字符串元素。处理完成之后,管道中剩下的元素是:[Lion, Lemur]
Stream<String> startsWithT = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.filter(s -> s.startsWith("L"));
如果没有学过lambda表达式的同学,可能对上面的代码感到困惑。其实很简单,lambda表达式用来表达函数,箭头左侧是参数,箭头右侧是函数体。函数的参数类型和返回值类型,会根据上下文做自动化的判断,不用你管。上文中的lambda表达式写成函数是这样的
public static boolean filterUpperL(String str){
return str.startsWith("L");
}
//.filter(BootLaunchApplicationTests::filterUpperL)
我甚至见过有的人排斥使用lambda表达式,说这种语法使代码的可读性下降。这个怎么说呢,如果一篇专业期刊中包含英语专业名词与引用,而读者恰巧不会英语就不想读了,我觉得这不是文章的问题,而是读者的问题。而且lamdba表达式在各种编程语言里面得到广泛的使用,提高编码效率。其实很简单:箭头左侧是参数,箭头右侧是函数体,你已经学会了!
三、Limit与Skip管道数据截取
Stream<String> startsWithT = Stream.of("Monkey", "Lion", "Giraffe", "Lemur").limit(2);
Stream<String> startsWithT = Stream.of("Monkey", "Lion", "Giraffe", "Lemur").skip(2);
- limt方法传入一个整数n,用于截取管道中的前n个元素。经过管道处理之后的数据是:[Monkey, Lion]。
- skip方法与limit方法的使用相反,用于跳过前n个元素,截取从n到末尾的元素。经过管道处理之后的数据是: [Giraffe, Lemur]
四、Distinct元素去重
我们还可以使用distinct方法对管道中的元素去重,涉及到去重就一定涉及到元素之间的比较,distinct方法时调用Object的equals方法进行对象的比较的,如果你有自己的比较规则,可以重写equals方法。
Stream<String> uniqueAnimals = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.distinct();
上面代码去重之后的结果是: ["Monkey", "Lion", "Giraffe", "Lemur"]
五、Sorted排序
默认的情况下,sorted是按照字母的自然顺序进行排序。如下代码的排序结果是:[Giraffe, Lemur, Lion, Monkey],字数按顺序G在L前面,L在M前面。第一位无法区分顺序,就比较第二位字母。
Stream<String> alphabeticOrder = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.sorted();
有的时候,我们希望排序的规则能够自定义,这就需要使用到Comparator。有的朋友这里可能忘了,可以自行回顾一下java基础的Comparator和Comparable接口。下面的代码是根据字符串的长度排序,排序结果是:[Lion, Lemur, Monkey, Giraffe]
Stream<String> lengthOrder = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.sorted(Comparator.comparing(String::length));
六、Map数据转换处理
map()函数的作用是将管道流中的每一个元素,以某种规则转换为另外一个元素。下面代码处理过的管道中的元素为: [monkey, lion, giraffe, lemur],所有元素的字母全部小写。
Stream<String> lowerCase = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.map(String::toLowerCase);
//这两种写法的实现效果是一样的,一个是lambda表达式,一个是函数引用的方式
Stream<String> lowerCase = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.map(s -> s.toLowerCase());
map()函数不仅可以处理数据,还可以转换数据的类型。如下:
IntStream lengths = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.mapToInt(String::length);
上面代码的处理结果是:[6, 4, 7, 5],规则是字符串的长度。将管道流的字符串,使用mapToInt方法,以String::length为规则进行转换。当然除了mapToInt,还为我们提供了mapToDouble()和mapToLong()方法。我们可以通过自定义转换规则函数,返回int、double、long类型的返回值。
期待您的关注
- 博主最近新写了一本书:《手摸手教您学习SpringBoot系列-16章97节》
- 本文转载注明出处(必须带连接,不能只转文字):字母哥博客。
Java Stream函数式编程图文详解(二):管道数据处理的更多相关文章
- Java Stream函数式编程第三篇:管道流结果处理
一.Java Stream管道数据处理操作 在本号之前写过的文章中,曾经给大家介绍过 Java Stream管道流是用于简化集合类元素处理的java API.在使用的过程中分为三个阶段.在开始本文之前 ...
- Java Stream函数式编程案例图文详解
导读 作者计划把Java Stream写成一个系列的文章,本文只是其中一节.更多内容期待您关注我的号! 一.什么是Java Stream? Java Stream函数式编程接口最初是在Java 8中引 ...
- Java之函数式接口@FunctionalInterface详解(附源码)
Java之函数式接口@FunctionalInterface详解 函数式接口的定义 在java8中,满足下面任意一个条件的接口都是函数式接口: 1.被@FunctionalInterface注释的接口 ...
- Java单链表反转图文详解
Java单链表反转图文详解 最近在回顾链表反转问题中,突然有一些新的发现和收获,特此整理一下,与大家分享 背景回顾 单链表的存储结构如图: 数据域存放数据元素,指针域存放后继结点地址 我们以一条 N1 ...
- Java 8系列之Stream的基本语法详解
本文转至:https://blog.csdn.net/io_field/article/details/54971761 Stream系列: Java 8系列之Stream的基本语法详解 Java 8 ...
- Java WebService接口生成和调用 图文详解>【转】【待调整】
webservice简介: Web Service技术, 能使得运行在不同机器上的不同应用无须借助附加的.专门的第三方软件或硬件, 就可相互交换数据或集成.依据Web Service规范实施的应用之间 ...
- 【适合公司业务】全网最详细的IDEA里如何正确新建【普通或者Maven】的Java web项目并发布到Tomcat上运行成功【博主强烈推荐】(类似eclipse里同一个workspace下【多个子项目】并存)(图文详解)
不多说,直接上干货! 首先,大家要明确,IDEA.Eclipse和MyEclipse等编辑器之间的新建和运行手法是不一样的. 如果是在Myeclipse里,则是File -> new -> ...
- Scala IDEA for Eclipse里用maven来创建scala和java项目代码环境(图文详解)
这篇博客 是在Scala IDEA for Eclipse里手动创建scala代码编写环境. Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群模式) ...
- 用maven来创建scala和java项目代码环境(图文详解)(Intellij IDEA(Ultimate版本)、Intellij IDEA(Community版本)和Scala IDEA for Eclipse皆适用)(博主推荐)
不多说,直接上干货! 为什么要写这篇博客? 首先,对于spark项目,强烈建议搭建,用Intellij IDEA(Ultimate版本),如果你还有另所爱好尝试Scala IDEA for Eclip ...
随机推荐
- 29道Zookeeper面试题超详细(附答案)
原文链接 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件 ...
- Cocos Creator 中 _worldMatrix 到底是什么(上)
Cocos Creator 中 _worldMatrix 到底是什么(上) 1. (矩阵)Matrix是什么,有什么用 (矩阵)Matrix一个神奇的存在?在开发过程中对里边各项值的含义是不是抓耳挠腮 ...
- Spring Cloud系列之Eureka服务治理
写在前面 Spring Cloud Eureka是基于Netflix Eureka做的二次封装.主要包含两部分: 服务注册中心 eureka server 服务提供者 eureka client ps ...
- Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计
要求编写的程序可爬取斗鱼直播网站上的直播信息,如:房间数,直播类别和人气等.熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析. 一.项目 ...
- Spring Boot (七): Mybatis极简配置
Spring Boot (七): Mybatis极简配置 1. 前言 ORM 框架的目的是简化编程中的数据库操作,经过这么多年的发展,基本上活到现在的就剩下两家了,一个是宣称可以不用写 SQL 的 H ...
- Spring框架(三)
对象依赖关系 Spring中,如何给对象的属性赋值? [DI, 依赖注入] 1) 通过构造函数 2) 通过set方法给属性注入值 3) p名称空间 4)自动装配(了解) 5) 注解 代码示例: &l ...
- 如何免费使用GPU跑深度学习代码
从事深度学习的研究者都知道,深度学习代码需要设计海量的数据,需要很大很大很大(重要的事情说三遍)的计算量,以至于CPU算不过来,需要通过GPU帮忙,但这必不意味着CPU的性能没GPU强,CPU是那种综 ...
- jedis 2.9版本部分属性变更
1.控制一个pool可分配多少个jedis实例 “maxActive” -> “maxTotal” 2.最大建立连接等待时间.如果超过此时间将接到异常.设为-1表示无限制. “maxWait” ...
- Java静态代理&动态代理&Cglib代理详解
一.静态代理 根据被代理的类的时机的不同,如果在编译阶段就能确定下来的被代理的类是哪一个,那么,就可以使用静态代理的方式. 申明一个接口: /** * @author jiaqing.xu@hand- ...
- CSS3相关编码规范
一.CSS书写顺序 1.位置属性(position, top, right, z-index, display, float等)2.大小(width, height, padding, margin) ...