Spark比MR快是因为在内存中计算?错!
MapReduce 就像一台又慢又稳的老爷车,虽然距离 MapReduce 面市到现在已经过去了十几年的时间,但它始终没有被淘汰,任由大数据技术日新月异、蓬蓬勃勃、花里胡哨地发展,这个生态圈始终有它的一席之地。
不过 Spark 的到来确实给了 MapReduce 不小的冲击,它比 MapReduce 理论上要快两个数量级,所以近几年不断有人讨论 Spark 是否可以完全替代 MapReduce ,但是为什么说是不断有人讨论呢?因为这些年 Spark 始终是无法完全取代 MapReduce 。
我们今天关注的问题是Spark为什么比 MapReduce 快?如果没有看文章的标题,你是不是会脱口而出:
“因为 Spark 是在内存中计算,而 MapReduce 是基于磁盘。”
这话乍一听没毛病,但是作为一个对技术很严谨的人,这让我忍不住想杠一下,
“那么 MapReduce 计算的时候不需要把数据加载到内存,在内存中计算吗?”
其实要对数据做计算,必然得把数据加载到内存, MapReduce 也不例外,Spark只是在计算模型和调度上做了更多的优化,不需要过多地和磁盘交互。
说到这里不得不提的就是 Spark 的 DAG(有向无环图),这个 DAG 就相当于改进版的 MapReduce,它可以说是由多个 MapReduce 组成,当数据处理流程中存在多个map和多个Reduce操作混合执行时,MapReduce只能提交多个Job执行,而Spark可以只提交一次,在一个任务中完成。
这就导致了 MapReduce 会存在多次耗时的资源申请和资源释放,另外 MapReduce 每次shuffle 操作后,必须写到磁盘,而 Spark 在 shuffle 后不一定落盘,如果Shuffle后的数据是需要反复用到的,则可以cache到内存中,方便迭代时使用,所以Spark对于需要对数据进行反复迭代的操作(比如跑机器学习算法或者有中间结果的复杂计算等)是非常友好的。
这里还有一个误区,很多人会认为 Spark 在计算时的所有过程都是在内存中完成的不用写磁盘,但是实际上不是这样的,在 shuffle 过程中 Spark 同样需要写磁盘,研究过 Sorted-Based Shuffle 的同学对这个写盘操作一定不陌生,如下图。
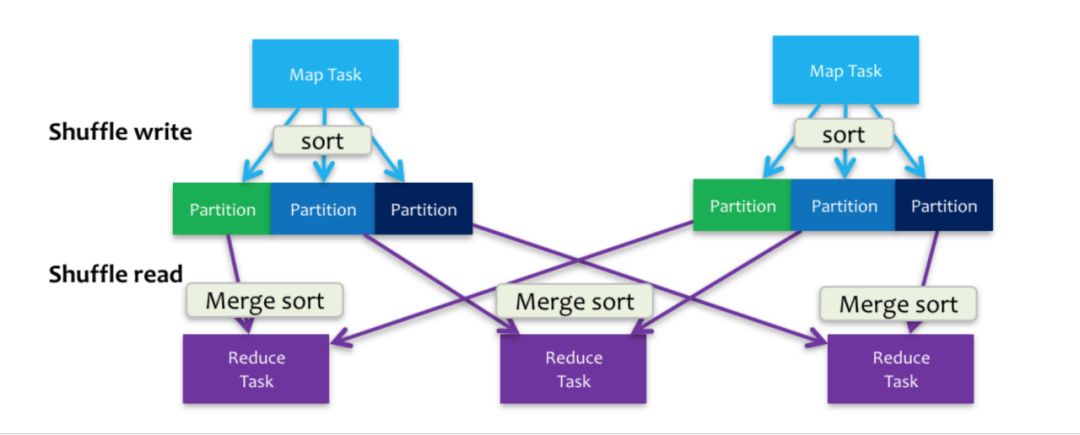
简单地说下,shuffle分成write和read两个阶段,write的过程不仅会写需要发向下一个Stage的数据到磁盘,还需要写一份数据的Index记录下游每个分区获取的数据范围。这里就不详细说了,有兴趣的同学可以去研究下。

另外,刚才提到了Spark尽管比MapReduce快两个数量级但是它始终没有被淘汰,这是因为它在每个阶段都落盘,虽然慢但是可以保证计算过程的稳定性,不会像Spark一样,一旦中间结果太大,内存装不下整个计算任务就崩了,这对于不讲究时效性的后台任务来说无疑是增加了维护成本,所以现在构建数据仓库的主要SQL工具还是Hive(Hive的底层是MapReduce),你见过用SparkSQL来跑数据量大的数仓任务的吗?
看完这篇,希望下次有人问你 Spark 为什么比 MapReduce 快的时候不要再说 Spark 在内存中计算了。
觉得有价值请关注 ▼

Spark比MR快是因为在内存中计算?错!的更多相关文章
- JS获取对象在内存中计算后的样式
通过obj.style的方式只能取得"内联style"的值,对于<style></style>中的css属性值,则无能为力 . 我们可以用obj.curre ...
- 内存中OLTP(Hekaton)里的事务日志记录
在今天的文章里,我想详细讨论下内存中OLTP里的事务日志如何写入事务日志.我们都知道,对于你的内存优化表(Memory Optimized Tables),内存中OLTP提供你2个持久性(durabi ...
- Spark(Python) 从内存中建立 RDD 的例子
Spark(Python) 从内存中建立 RDD 的例子: myData = ["Alice","Carlos","Frank"," ...
- QList介绍(QList比QVector更快,这是由它们在内存中的存储方式决定的。QStringList是在QList的基础上针对字符串提供额外的函数。at()操作比操作符[]更快,因为它不需要深度复制)非常实用
FROM:http://apps.hi.baidu.com/share/detail/33517814 今天做项目时,需要用到QList来存储一组点.为此,我对QList类的说明进行了如下翻译. QL ...
- 使用spark将内存中的数据写入到hive表中
使用spark将内存中的数据写入到hive表中 hive-site.xml <?xml version="1.0" encoding="UTF-8" st ...
- 内存中 OLTP - 常见的工作负荷模式和迁移注意事项(二)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<In-Memory OLTP – Comm ...
- SQL Server 内存中OLTP内部机制概述(二)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- C/C++数据在内存中的存储方式
目录 1 内存地址 2 内存空间 在学习C/C++编程语言时,免不了和内存打交道,在计算机中,我们存储有电影,文档,音乐等数据,这些数据在内存中是以什么形式存储的呢?下面做一下简单介绍. 本文是学 ...
- Linux内存中Swap机制(转)
在做监控时,发现内存中有一项Swap space,不是很理解,这里查了一些资料: http://blog.sina.com.cn/s/blog_502d765f0100krph.html 在linux ...
随机推荐
- 讲解开源项目:功能强大的 JS 文件上传库
本文作者:HelloGitHub-kalifun HelloGitHub 的<讲解开源项目>系列,项目地址:https://github.com/HelloGitHub-Team/Arti ...
- 纯数据结构Java实现(5/11)(Set&Map)
纯数据结构Java实现(5/11)(Set&Map) Set 和 Map 都是抽象或者高级数据结构,至于底层是采用树还是散列则根据需要而定. 可以细想一下 TreeMap/HashMap, T ...
- Spring中jdbcTemplate的用法实例
一.首先配置JdbcTemplate: 要使用Jdbctemplate 对象来完成jdbc 操作.通常情况下,有三种种方式得到JdbcTemplate 对象. 第一种方式:我们可以在自己定 ...
- 纯 Python 实现的 Google 批量翻译
测试通过时间:2019-8-20 参阅:C#实现谷歌翻译API.Python之Google翻译爬虫 首先声明,没有什么不良动机,因为经常会用 translate.google.cn,就想着用 Pyth ...
- k8s西游记 - 切换网络插件IP池
前言 最近在另一个k8s集群中,搭建了kong网关,在配置OIDC插件时,希望使用Memcahe代替Cookie来存储会话信息,于是把部署在同一局域网Memcahe的内网IP,比如:192.168.1 ...
- PicGo+GitHub:你的最佳免费图床选择!
# PicGo介绍 这是一款图片上传的工具,目前支持SM.MS图床,微博图床,七牛图床,腾讯云COS,阿里云OSS,Imgur,又拍云,GitHub等图床,未来将支持更多图床. 所以解决问题的思路就是 ...
- Unity进阶:用AssetBundle和Json做了一个玩家登陆界面
版权申明: 本文原创首发于以下网站: 博客园『优梦创客』的空间:https://www.cnblogs.com/raymondking123 优梦创客的官方博客:https://91make.top ...
- unity,C#,游戏面试笔试真题
最开始的两家公司笔试面试题目 一家公司是学校聘请研究教育方面VR课件的公司,面试没几天,就收到了面试通过的消息,后面因为通过了另一家游戏公司而拒绝了. 另一家公司是一家游戏外企,在春熙路,当时笔试还可 ...
- POJ 1661 暴力dp
题意略. 思路: 很有意思的一个题,我采用的是主动更新未知点的方式,也即刷表法来dp. 我们可以把整个路径划分成横向移动和纵向移动,题目一开始就给出了Jimmy的高度,这就是纵向移动的距离. 我们dp ...
- EF的3种开发模式
那么明显开发模式是三种. 即:DateBase First(数据库优先).Model First(模型优先)和Code First(代码优先). 当然,如果把Code First模式的两种具体方式独立 ...