Python基础库之jieba库的使用(第三方中文词汇函数库)
各位学python的朋友,是否也曾遇到过这样的问题,举个例子如下:
“I am proud of my motherland”
如果我们需要提取中间的单词要走如何做?
自然是调用string中的split()函数即可

那么将这转换成中文呢,“我为我的祖国感到骄傲”再分词会怎样?
中国词汇并不像是英文文本那样可以通过空格又或是标点符号来区分,
这将会导致比如“骄傲”拆开成“骄”、“傲”,又或者将“为”“我的”组合成“为我的”等等
那如何避免这些问题呢? 这就用到了今天介绍的python基础库——jieba库
一、什么是jieba库?
jieba库是优秀的中文分词第三方库 ,它可以利用一个中文词库,确定汉字之间的关联概率,
将汉字间概率大的组成词组,形成分词结果,将中文文本通过分词获得单个的词语。
jieba分词的三种模式 :精确模式、全模式、搜索引擎模式
- 精确模式:把文本精确的切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分
二、安装jieba库
安装jieba库还是比较简单的,我介绍几种简单的方法
1.全自动安装
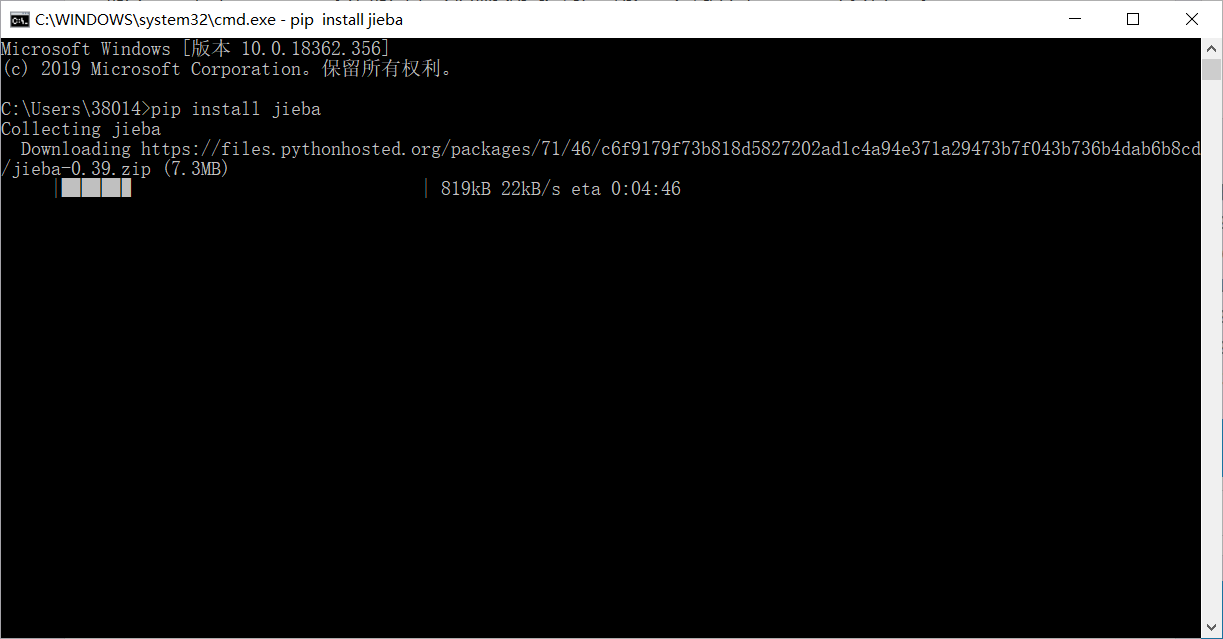
打开cmd命令提示符然后输入代码
easy_install jieba
pip install jieba
pip3 install jieba
三段代码任意一个即可自动下载安装
2.半自动安装
首先打开jieba库网站:http://pypi.python.org/pypi/jieba/
然后下载并运行python setup.py install
最后将 jieba 目录放置于当前目录或者 site-packages 目录

3.软件安装
许多编辑软件都可以在软件内部安装,以pycharm2019为例子
首先打开pycharm,在左上角文件中可以找到设置,然后打开设置
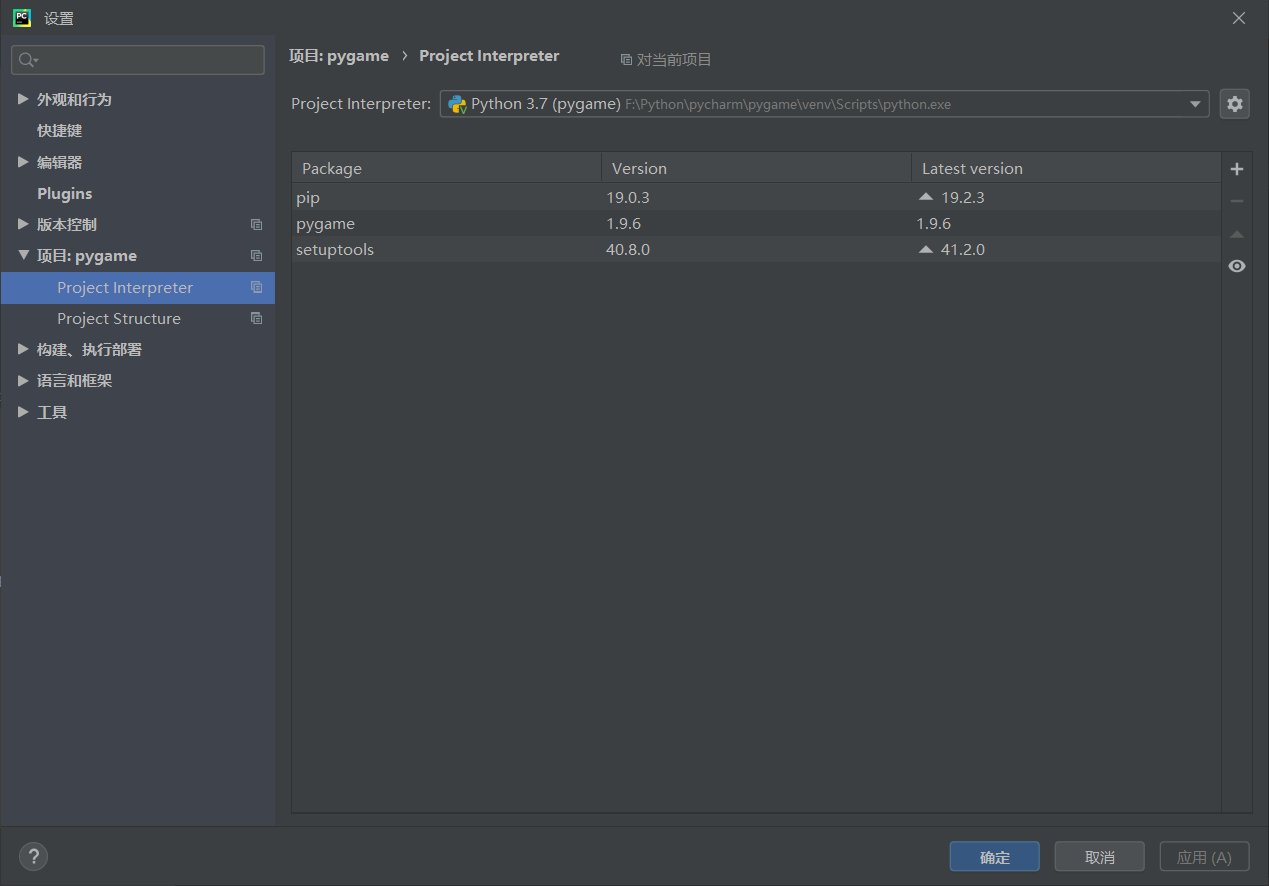
右侧项目相关可以找到 project interpreter,进入可以查看项目引用的模块
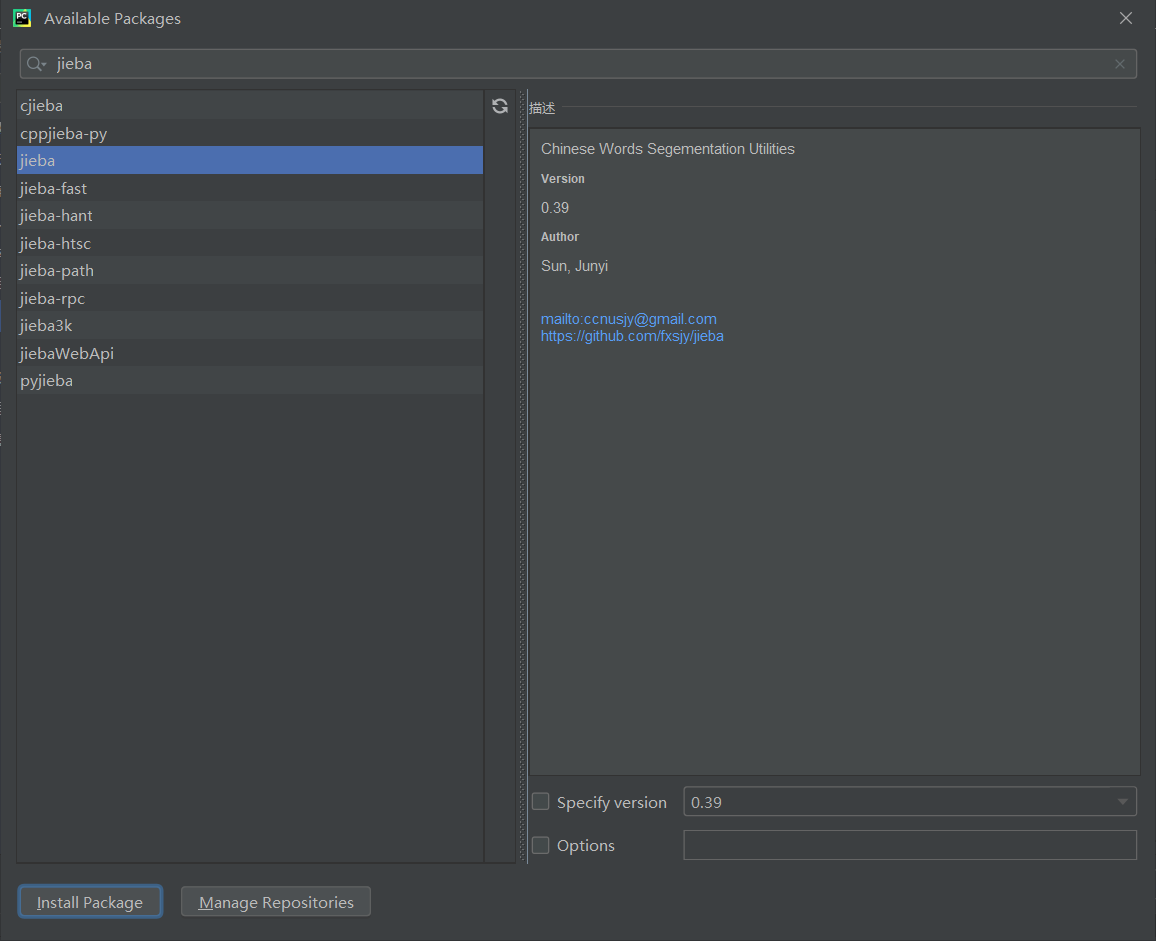
点击右侧的加号,在available packages 中搜索jieba 选中后点击左下角安装即可
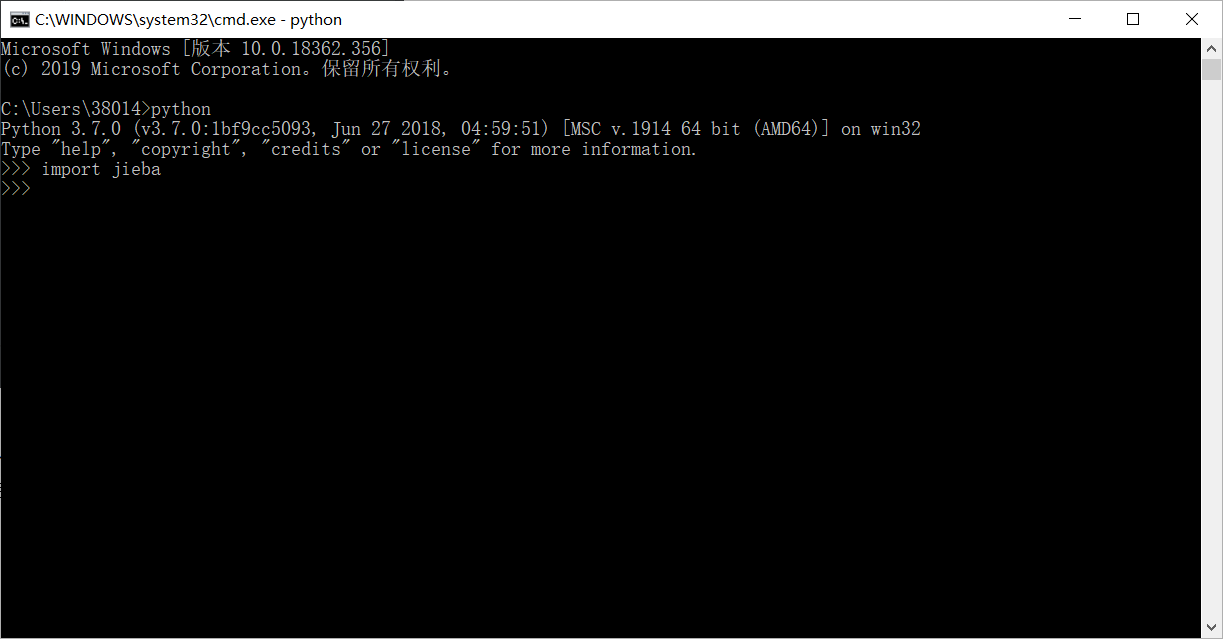
4.检测安装
打开命令提示符(cmd)进入python环境
输入import jieba 如下图所示即为安装成功
三、主要函数
jieba.cut(s)
被运用于精确模式,将会返回一个可迭代的数据类型
jieba.cut(s,cut_all=True)
被运用于全模式,输出文本s中的所有可能单词
jieba.cut_for_search(s)
搜索引擎模式,适合搜索引擎建立索引的分词结果
jieba.lcut(s)
被运用于精确模式,将会返回一个列表类型
jieba.lcut(s,cut_all=True)
被运用于全模式,返回一个列表类型
jieba.lcut_for_search(s)
搜索引擎模式,返回一个列表类型
jieba.add_word(w)
向分词词典加入新词
相信不少同学已经看得有点蒙,那么接下来我将通过代码来实际对比不同点
首先我们对比三个不同的模式 ,之前的介绍可以看出:
精确模式将不会出现冗余,所有词汇都是根据最大可能性而进行组合的出结果
全模式与精确模式最大区别在于,全模式将会把所有可能拼接的词汇全部展现
搜索引擎模式则是在精确模式的前提下对较长词汇进行再一次分割
我们以“我因自己是中华人民共和国的一份子而感到骄傲”为例
*精确模式结果如下 :

['我', '因', '自己', '是', '中华人民共和国', '的', '一份', '子', '而', '感到', '骄傲']
*全模式结果如下:

['我', '因', '自己', '是', '中华', '中华人民', '中华人民共和国', '华人', '人民', '人民共和国', '共和', '共和国', '的', '一份', '份子', '而', '感到', '骄傲']
*搜索引擎模式结果如下:

['我', '因', '自己', '是', '中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '的', '一份', '子', '而', '感到', '骄傲']
可以很明显的对比出来,全模式将所有课能出现的词汇进行罗列,而搜索引擎模式与精确模式十分相似,但对“中华人名共和国“”这一词汇进行分词
至于有的同学发现有些函数十分相似,比如说cut()与lcut()
两者之间其实差距不大,主要不同在于返回类型,加“l”的一般返回为列表类型。
如果觉得有所帮助,还望各位大佬点赞支持谢谢

Python基础库之jieba库的使用(第三方中文词汇函数库)的更多相关文章
- 学习参考《Python基础教程(第3版)》中文PDF+英文PDF+源代码
python基础教程ed3: 基础知识 列表和元组 字符串 字典 流程控制 抽象(参数 作用域 递归) 异常 魔术方法/特性/迭代器 模块/标准库 文件 GUI DB 网络编程 测试 扩展python ...
- Python基础学习笔记(八)常用字典内置函数和方法
参考资料: 1. <Python基础教程> 2. http://www.runoob.com/python/python-dictionary.html 3. http://www.lia ...
- Python基础学习笔记(七)常用元组内置函数
参考资料: 1. <Python基础教程> 2. http://www.runoob.com/python/python-tuples.html 3. http://www.liaoxue ...
- 【笔记】Python基础二:数据类型之集合,字符串格式化,函数
一,新类型:集合 集合出现之前 python_l = ['lcg','szw','zjw'] linux_l = ['lcg','szw','sb'] #循环方法求交集 python_and_linu ...
- python基础3之文件操作、字符编码解码、函数介绍
内容概要: 一.文件操作 二.字符编码解码 三.函数介绍 一.文件操作 文件操作流程: 打开文件,得到文件句柄并赋值给一个变量 通过句柄对文件进行操作 关闭文件 基本操作: #/usr/bin/env ...
- python基础编程: 编码补充、文件操作、集合、函数参数、函数递归、二分查找、匿名函数与高阶函数
目录: 编码的补充 文件操作 集合 函数的参数 函数的递归 匿名函数与高阶函数 二分查找示例 一.编码的补充: 在python程序中,首行一般为:#-*- coding:utf-8 -*-,就是告诉p ...
- python基础(内存分析,不引入第三方变量的方式交换变量的值)
a,b指向同一块内存地址 下面方法是重新给b赋值;a,b指向不同的内存地址 字符串或int类型内存分析 不引入第三方变量的方式,交换a,b的值
- Win10系统下Anaconda下安装多种Python函数库
建议直接安装Anaconda,这是一个包含Numpy,Pandas,Sklearn等函数库的计算机科学软件包,下面的软件可以在此环境下进行安装下载. 一.计算机视觉 1. OpenCV图像处理 在ht ...
- 通过编译函数库来学习GCC【转】
转自:http://blog.csdn.net/u012365926/article/details/51446295 基本概念 什么是库 在windows平台和linux平台下都大量存在着库. 本质 ...
随机推荐
- Python二元操作符
def quiz_message(grade): outcome = 'failed' if grade<50 else 'passid' print ('grade', grade, 'out ...
- opencv边缘检测报错
cnts = cv2.findContours(edged_image.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)cnts = cnts[0] if ...
- 一些数组排序算法的简单实现(冒泡、插入、希尔、归并和qsort)
#include <stdlib.h> #include <string.h> #include "sort.h" //冒泡排序 int bubbleSor ...
- 不用JS,教你只用纯HTML做出几个实用网页效果
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者.原文出处:https://blog.bitsrc.io/pure-html-widgets-for-your- ...
- Elastic Stack 笔记(八)Elasticsearch5.6 Java API
博客地址:http://www.moonxy.com 一.前言 Elasticsearch 底层依赖于 Lucene 库,而 Lucene 库完全是 Java 编写的,前面的文章都是发送的 RESTf ...
- 小白专场-是否同一颗二叉搜索树-python语言实现
目录 一.二叉搜索树的相同判断 二.问题引入 三.举例分析 四.方法探讨 4.1 中序遍历 4.2 层序遍历 4.3 先序遍历 4.4 后序遍历 五.总结 六.代码实现 一.二叉搜索树的相同判断 二叉 ...
- 关于mock
关于mock 一.什么是mock? 通俗来讲,在开发和测试过程中,由于环境不稳定或者协同开发的同事未完成等情况下,有些数据不容易构造或者不容易获取,就创建一个虚拟的对象或者数据样本,用来辅助开发或者测 ...
- C#使用Oxyplot绘制监控界面
C#中可选的绘图工具有很多,除了Oxyplot还有DynamicDataDisplay(已经改名为InteractiveDataDisplay)等等.不过由于笔者这里存在一些环境上的特殊要求,.Net ...
- Linux Centos7部署环境安装-CentOS
Linux Centos7部署环境安装-CentOS Centos7部署环境安装及Linux常用命令 centos系统下各文件夹的作用 centos7修改系统默认语言 centos7安装rz/sz命令 ...
- 前台提交数据到node服务器(get方式)
.有两种办法,一种是表单提交,一种是ajax方式提交. 1.form提交 在前台模板文件上写: <form action="/reg" method="get&q ...