深入理解SQL Server数据库Select查询原理(一)
使用SQL Server十年有余,但是一直对其Select查询机制原理一致不明,直到最近有个通讯录表,很简单的一张表(但因简单,所以当时并没有考虑按部门排序问题),结果想查询某个单位所有部门(不重复),结果出现查询的结果排序并不是自己当前数据存储的部门顺序。经过仔细核实发现,在Select中使用distinct时,就会触发中文排序,按照拼音字母的顺序进行排序。度娘后网上有类似文章,感谢网友的无私分享。
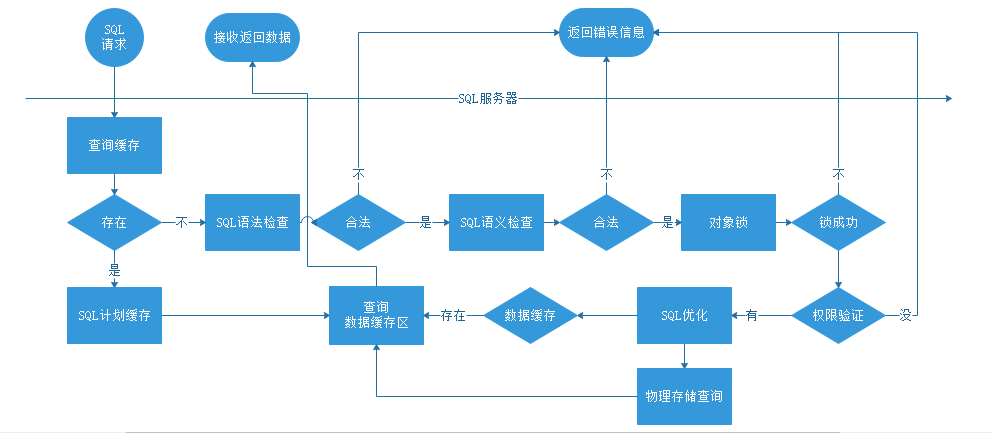
第一步:应用程序把查询SQL语句发给服务器端执行
我们在数据层执行SQL语句时,应用程序会连接到相应的数据库服务器,把SQL语句发送给服务器处理。
第二步:服务器解析请求的SQL语句
1.SQL计划缓存,经常用查询分析器的朋友大概都知道这样一个事实,往往一个查询语句在第一次运行的时候需要执行特别长的时间,但是如果你马上或者在一定时间内运行同样的语句,会在很短的时间内返回查询结果。
原因:
- 服务器在接收到查询请求后,并不会马上去数据库查询,而是在数据库中的计划缓存中找是否有相对应的执行计划,如果存在,就直接调用已经编译好的执行计划,节省了执行计划的编译时间。
- 如果所查询的行已经存在于数据缓冲存储区中,就不用查询物理文件了,而是从缓存中取数据,这样从内存中取数据就会比从硬盘上读取数据快很多,提高了查询效率.数据缓冲存储区会在后面提到。
2.如果在SQL计划缓存中没有对应的执行计划,服务器首先会对用户请求的SQL语句进行语法效验,如果有语法错误,服务器会结束查询操作,并用返回相应的错误信息给调用它的应用程序。
注意:此时返回的错误信息中,只会包含基本的语法错误信息,例如select写成selec等,错误信息中如果包含一列表中本没有的列,此时服务器是不会检查出来的,因为只是语法验证,语义是否正确放在下一步进行。
3.语法符合后,就开始验证它的语义是否正确,例如,表名,列名,存储过程等等数据库对象是否真正存在,如果发现有不存在的,就会报错给应用程序,同时结束查询。
4.接下来就是获得对象的解析锁,我们在查询一个表时,首先服务器会对这个对象加锁,这是为了保证数据的统一性,如果不加锁,此时有数据插入,但因为没有加锁的原因,查询已经将这条记录读入,而有的插入会因为事务的失败会回滚,就会形成脏读的现象。
5.接下来就是对数据库用户权限的验证,SQL语句语法,语义都正确,此时并不一定能够得到查询结果,如果数据库用户没有相应的访问权限,服务器会报出权限不足的错误给应用程序,在稍大的项目中,往往一个项目里面会包含好几个数据库连接串,这些数据库用户具有不同的权限,有的是只读权限,有的是只写权限,有的是可读可写,根据不同的操作选取不同的用户来执行,稍微不注意,无论你的SQL语句写的多么完善,完美无缺都没用。
6.解析的最后一步,就是确定最终的执行计划。当语法,语义,权限都验证后,服务器并不会马上给你返回结果,而是会针对你的SQL进行优化,选择不同的查询算法以最高效的形式返回给应用程序。例如在做表联合查询时,服务器会根据开销成本来最终决定采用hashjoin,mergejoin,还是loopjoin,采用哪一个索引会更高效等等,不过它的自动化优化是有限的,要想写出高效的查询SQL还是要优化自己的SQL查询语句。
当确定好执行计划后,就会把这个执行计划保存到SQL计划缓存中,下次在有相同的执行请求时,就直接从计划缓存中取,避免重新编译执行计划。
第三步:语句执行
服务器对SQL语句解析完成后,服务器才会知道这条语句到底代表了什么意思,接下来才会真正的执行SQL语句。
这时分两种情况:
- 如果查询语句所包含的数据行已经读取到数据缓冲存储区的话,服务器会直接从数据缓冲存储区中读取数据返回给应用程序,避免了从物理文件中读取,提高查询速度。
- 如果数据行没有在数据缓冲存储区中,则会从物理文件中读取记录返回给应用程序,同时把数据行写入数据缓冲存储区中,供下次使用。
说明:SQL缓存分好几种,这里有兴趣的朋友可以去搜索一下,有时因为缓存的存在,使得我们很难马上看出优化的结果,因为第二次执行因为有缓存的存在,会特别快速,所以一般都是先消除缓存,然后比较优化前后的性能表现,这里有几个常用的方法:
DBCCDROPCLEANBUFFERS
从缓冲池中删除所有清除缓冲区。
DBCCFREEPROCCACHE
从过程缓存中删除所有元素。
DBCCFREESYSTEMCACHE
从所有缓存中释放所有未使用的缓存条目。SQLServer2005数据库引擎会事先在后台清理未使用的缓存条目,以使内存可用于当前条目。但是,可以使用此命令从所有缓存中手动删除未使用的条目。
深入理解SQL Server数据库Select查询原理(一)的更多相关文章
- SQL Server数据库————连接查询和分组查询
SQL Server数据库————连接查询和分组查询 分组查询 select 列from <表名> where …… group by 列 注意:跟order by一样group ...
- SQL Server数据库 优化查询速度
查询速度慢的原因很多,常见如下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 ...
- SQL Server 数据库子查询基本语法
一.SQL子查询语句 1.单行子查询 select ename,deptno,sal from emp where deptno=(select deptno ...
- 转!!sql server 数据库 索引的原理与应用
索引的概念 索引的用途:我们对数据查询及处理速度已成为衡量应用系统成败的标准,而采用索引来加快数据处理速度通常是最普遍采用的优化方法. 索引是什么:数据库中的索引类似于一本书的目录,在一本书中使用目录 ...
- sql server数据库数据查询成功
<%@ page language="java" contentType="text/html; charset=utf-8" pageEncoding= ...
- SQL Server 数据库差异 查询
-- 比较两个数据库中表的差异 -- u表,p存储过程,v视图 -- INTFSIMSNEW新库,INTFSIMS旧库 SELECT NTABLE = A.NAME, OTABLE = B.NAME ...
- SQL Server数据库————模糊查询和聚合函数
***********模糊查询*********/ 关键字: like (!!!!字符串类型) in (,,) 匹配()内的某个具体值(括号里可以写多个值) between... and.. 在某两 ...
- T-SQL查询进阶--理解SQL Server中索引的概念,原理以及其他
简介 在SQL Server中,索引是一种增强式的存在,这意味着,即使没有索引,SQL Server仍然可以实现应有的功能.但索引可以在大多数情况下大大提升查询性能,在OLAP中尤其明显.要完全理解索 ...
- T-SQL查询进阶--理解SQL Server中索引的概念,原理
简介 在SQL Server中,索引是一种增强式的存在,这意味着,即使没有索引,sql server仍然可以实现应有的功能,但索引可以在大多数情况下提升查询性能,在OLAP(On line Trans ...
随机推荐
- kubernetes离线包分析
k8s离线包解析 产品地址 鸣谢 大家好,首先感谢大家对我们产品的支持,特别是一些老客户的持续支持,让我可以有动力把这个事情持续进行下去. 感谢大家对付费产品的认可,尊重付费 产品介绍 我们专注于k8 ...
- 对数变换(一些基本的灰度变换函数)基本原理及Python实现
1. 基本原理 变换形式如下 $$T(r) = c\lg(r+1)$$ c为常数 由于对数函数的导数随自变量的增大而减小,对数变换将输入窄范围的低灰度值扩展为范围宽的灰度值和宽范围的高灰度值压缩为映射 ...
- Python 命令行之旅 —— 深入 argparse (一)
作者:HelloGitHub-Prodesire HelloGitHub 的<讲解开源项目>系列,项目地址:https://github.com/HelloGitHub-Team/Arti ...
- Linux的crond和crontab
一.crond cron是一个linux下的定时执行工具(相当于windows下的scheduled task),可以在无需人工干预的情况下定时地运行任务task. 由于cron 是Linux的ser ...
- net core Webapi基础工程搭建(六)——数据库操作_Part 1
目录 前言 SqlSugar Service层 BaseService(基类) 小结 前言 后端开发最常打交道的就是数据库了(静态网站靠边),上一篇net core Webapi基础工程搭建(五)-- ...
- Python学习 之三 Python基础&运算符
第三章:Python基础 & 运算符 3.1 内容回顾 & 补充 计算机基础 编码 字符串: "中国" "Hello" 字 符: 中 e 字 节 ...
- Spring学习之旅(九)--SpringMVC高级技术
文件上传 在 Web 应用中,允许用户上传文件是很常见的需求.文件上传通常是采用 multipart 格式,而 DispatcherServlet 并没有任何解析 multipart 请求数据的功能, ...
- 自制微信小程序 提示插件 -- noticeUitis.js
/* noticeMsg.js by: FEer_llx Modify 2016/08/24 */ function weNotice(obj) { this.fadeFlag = true; thi ...
- Filter(过滤器)(有待补充)
Filter(过滤器) 一.Filter(过滤器)简介 Filter 的基本功能是对 Servlet 容器调用 Servlet 的过程进行拦截,从而在 Servlet 进行响应处理的前后实现一些特殊的 ...
- Fastjson反序列化漏洞概述
Fastjson反序列化漏洞概述 背景 在推动Fastjson组件升级的过程中遇到一些问题,为帮助业务同学理解漏洞危害,下文将从整体上对其漏洞原理及利用方式做归纳总结,主要是一些概述性和原理上的东 ...