(一)分布式数据库tidb-简介
因为数据磁盘问题,最近进行了更换库,所以决定写关于这方面的专题的博客,博客信息参考的官方文档。
一、分布式数据库使用背景
随着互联网的飞速发展,业务量可能在短短的时间内爆发式地增长,对应的数据量可能快速地从几百 GB 涨到几百个 TB,传统的单机数据库提供的服务,在系统的可扩展性、性价比方面已经不再适用。比如MySQL数据库,缺点是没法做到水平扩展。MySQL 要想能做到水平扩展,唯一的方法就业务层的分库分表或者使用中间件等方案。但是,这些中间层方案也有很大局限性,执行计划不是最优,分布式事务,跨节点 join,扩容复杂等。
二、分布式数据库TiDB简介
TiDB 是 PingCAP 公司设计的开源分布式 HTAP (Hybrid Transactional and Analytical Processing) 数据库,结合了传统的 RDBMS 和 NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的目标是为 OLTP (Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案。。
TiDB 具备如下特性:
- 高度兼容 MySQL
大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
- 水平弹性扩展
通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
- 分布式事务
TiDB 100% 支持标准的 ACID 事务。
- 真正金融级高可用
相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
- 一站式 HTAP 解决方案
TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解决方案,一份存储同时处理 OLTP & OLAP,无需传统繁琐的 ETL 过程。
- 云原生 SQL 数据库
TiDB 是为云而设计的数据库,支持公有云、私有云和混合云,使部署、配置和维护变得十分简单。
TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景,更复杂的 OLAP 分析可以通过 TiSpark 项目来完成。
TiDB 对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力。
三、TiDB整体架构
要深入了解 TiDB 的水平扩展和高可用特点,首先需要了解 TiDB 的整体架构。
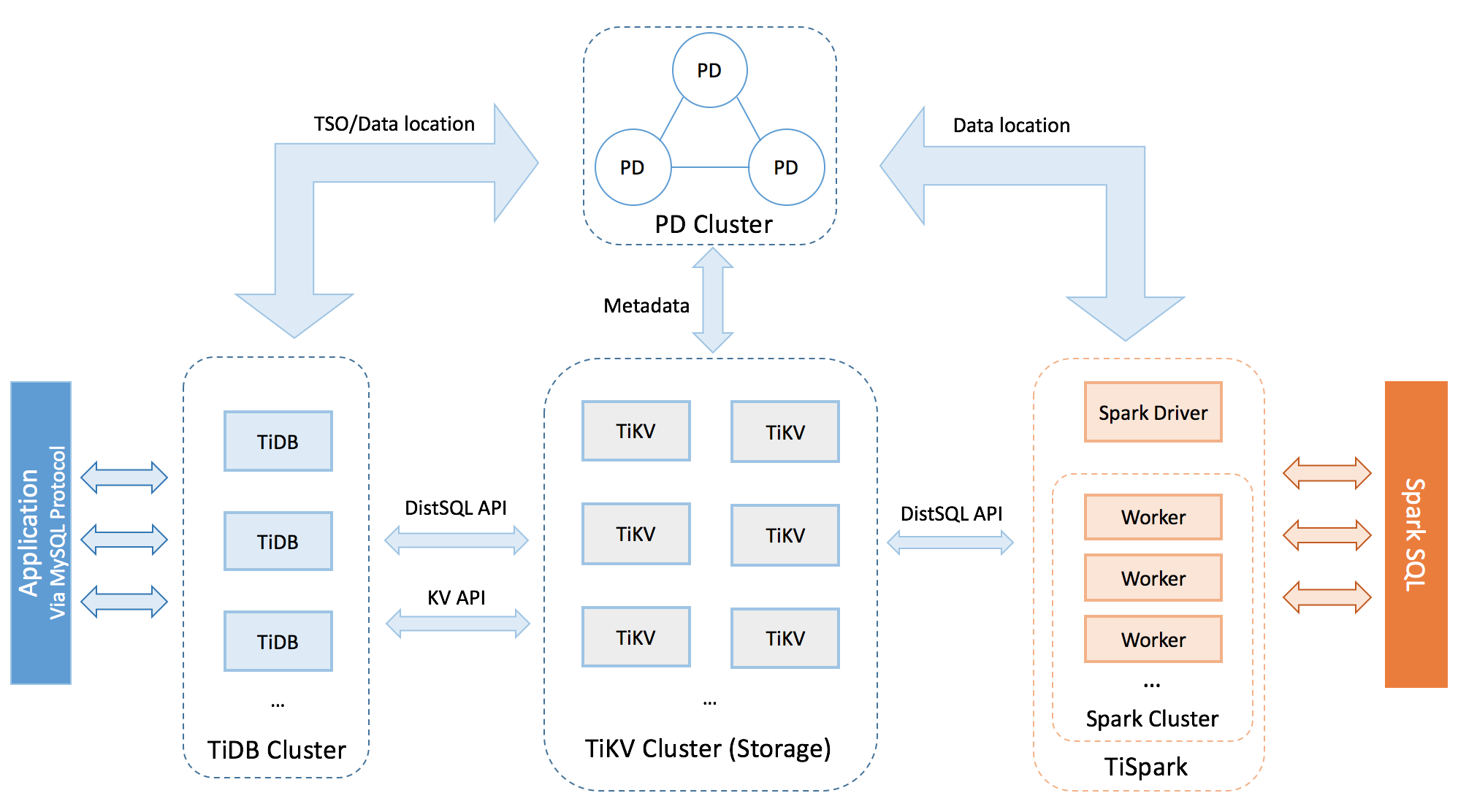
TiDB 集群主要分为三个组件:
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。 TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署 3 个节点。
TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region(区域),每个 Region 负责存储一个 Key Range (从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
四、核心特性
- 水平扩展
无限水平扩展是 TiDB 的一大特点,这里说的水平扩展包括两方面:计算能力和存储能力。TiDB Server 负责处理 SQL 请求,随着业务的增长,可以简单的添加 TiDB Server 节点,提高整体的处理能力,提供更高的吞吐。TiKV 负责存储数据,随着数据量的增长,可以部署更多的 TiKV Server 节点解决数据 Scale 的问题。PD 会在 TiKV 节点之间以 Region 为单位做调度,将部分数据迁移到新加的节点上。所以在业务的早期,可以只部署少量的服务实例,随着业务量的增长,按照需求添加 TiKV 或者 TiDB 实例。
- 高可用
高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。
五、TiDB原理与实现
TiDB 架构是 SQL 层和 KV 存储层分离,相当于 InnoDB 插件存储引擎与 MySQL 的关系。从下图可以看出整个系统是高度分层的,最底层选用了当前比较流行的存储引擎 RocksDB,RockDB 性能很好但是是单机的,为了保证高可用所以写多份,上层使用 Raft 协议来保证单机失效后数据不丢失不出错。保证有了比较安全的 KV 存储的基础上再去构建多版本,再去构建分布式事务,这样就构成了存储层 TiKV。有了TiKV,TiDB 层只需要实现 SQL 层,再加上 MySQL 协议的支持,应用程序就能像访问 MySQL 那样去访问 TiDB 了。

(一)分布式数据库tidb-简介的更多相关文章
- 【Hadoop】一、分布式数据库HBase简介
1.分布式数据库特点 说到数据库,我们最熟悉的是类似于mysql这样的关系型数据库,称为RDBMS.关系型数据库作为一种数据存储和数据检索的关键技术,它支持SQL语言的结构化查询,但是它天生不是为 ...
- 分布式数据库TiDB的部署
转自:https://my.oschina.net/Kenyon/blog/908370 一.环境 CentOS Linux release 7.3.1611 (Core)172.26.11.91 ...
- NewSQL分布式数据库,例如TIDB用K/V的底层逻辑
内容参考 对分布式对定义参考这篇文章: 微服务都想用,先把分布式和微服务之间的关系说清楚 对分布式架构中心或无中心对比参考这篇文章: 分布式存储单主.多主和无中心架构的特征与趋势 对HDFS对内部机制 ...
- 新一代数据库TiDB在美团的实践
1. 背景和现状 近几年,基于MySQL构建的传统关系型数据库服务,已经很难支撑美团业务的爆发式增长,这就促使我们去探索更合理的数据存储方案和实践新的运维方式.而随着分布式数据库大放异彩,美团DBA团 ...
- 【TIDB】1、TiDb简介
一 TiDb简介 TiDB 是 PingCAP 公司受 Google Spanner / F1 论文启发而设计的开源分布式 HTAP (Hybrid Transactional and Analyti ...
- 云时代的分布式数据库:阿里分布式数据库服务DRDS
发表于2015-07-15 21:47| 10943次阅读| 来源<程序员>杂志| 27 条评论| 作者王晶昱 <程序员>杂志数据库DRDS分布式沈询 摘要:伴随着系统性能.成 ...
- 怎样打造一个分布式数据库——rocksDB, raft, mvcc,本质上是为了解决跨数据中心的复制
摘自:http://www.infoq.com/cn/articles/how-to-build-a-distributed-database?utm_campaign=rightbar_v2& ...
- net Core 使用MyCat分布式数据库,实现读写分离
net Core 使用MyCat分布式数据库,实现读写分离 目录索引 [无私分享:ASP.NET CORE 项目实战]目录索引 简介 MyCat2.0版本很快就发布了,关于MyCat的动态和一些问题, ...
- Amoeba是一个类似MySQL Proxy的分布式数据库中间代理层软件,是由陈思儒开发的一个开源的java项目
http://www.cnblogs.com/xiaocen/p/3736095.html amoeba实现mysql读写分离 application shang 2年前 (2013-03-28) ...
随机推荐
- [Spring cloud 一步步实现广告系统] 16. 增量索引实现以及投送数据到MQ(kafka)
实现增量数据索引 上一节中,我们为实现增量索引的加载做了充足的准备,使用到mysql-binlog-connector-java 开源组件来实现MySQL 的binlog监听,关于binlog的相关知 ...
- js 数组对象深拷贝
js 数组对象深拷贝 结论:对象的拷贝不能采用直接赋值的方式. 背景 踩过的坑如下: formData本来是父组件传过来的,但是我不想直接用,于是我直接赋值给一个formDataCopy的对象. 但是 ...
- 渐进式web应用开发---使用indexedDB实现ajax本地数据存储(四)
在前几篇文章中,我们使用service worker一步步优化了我们的页面,现在我们学习使用我们之前的indexedDB, 来缓存我们的ajax请求,第一次访问页面的时候,我们请求ajax,当我们继续 ...
- Python装饰器完全解读
1 引言 装饰器(Decorators)可能是Python中最难掌握的概念之一了,也是最具Pythonic特色的技巧,深入理解并应用装饰器,你会更加感慨——人生苦短,我用Python. 2 初步理解装 ...
- oracle 正则表达的使用
最近遇到有个项目,需要根据文件存储的根目录地址来判断是在云端获取,还是本地获取, 先看下具体有几个不同的根目录: , , 'i') from pmc.designmaterial d 去重关键字:di ...
- Spring参数的自解析--还在自己转换?你out了!
背景前段时间开发一个接口,因为调用我接口的同事脾气特别好,我也就不客气,我就直接把源代码发给他当接口定义了. 没想到同事看到我的代码问:要么 get a,b,c 要么 post [a,b,c]. ...
- mongo常用语法
首先要能进入控制台,进不去自己解决. 基本操作: show users:显示用户 show dbs:显示数据库列表 use <db name> 切换/创建数据库 show collecti ...
- JD面试 || 移除教室人数
在昨天参加了东哥的笔试,选择题做的还算可以,但是还有道编程题和关于jdk8的Stream特性难住了.鉴于此用博客总结一下这道编程题,并结合Stream特性来简化代码,熟悉Api. 题目描述 某校在积极 ...
- Hive的安装及配置
title: Hive的安装及配置 summary: 关键词:Hive ubuntu 安装和配置 Derby MySQL PostgreSQL 数据库连接 date: 2019-5-19 13:25 ...
- Liunx软件安装之Zabbix监控软件
Zabbix 是什么 zabbix(音同 za:bix)是一个基于 WEB 界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案. zabbix 能监视各种网络参数,保证服务器系统的安全运营 ...