SQL Serve里DBA要去改变的3个配置选项
用安装向导安装了全新的SQL Server,最后你点击了完成按钮。哇噢~~~现在我们可以把我们的服务器进入生产了!
抱歉,那并不是真的,因为你的全新SQL Server默认配置是未优化的,一个合格的DBA一定会对默认安装中配置进行修改。
当然,如果你只是学习用途,默认配置微软确实已经做得很好。
但服务器进入生产,为了更快的性能,在SQL Server安装完成后3个你需要立即修改的配置选项。
1. 最大服务器内存(Max Server Memory)
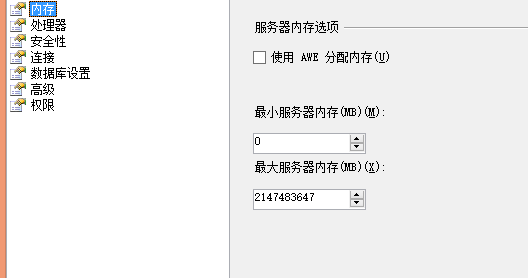
这是一个很不好的默认配置。SQL Server默认可以吃光你整个物理内存!
你总应该改变这个配置选项,这样的话你可以给系统一些内存,让它可以活着喘气。一般来说(在服务器上没有其它程序/进程)你应该留给操作系统至少10%的物理内存。
这就是说你需要调低最大服务器内存设置。有64GB的物理内存我会配置最大服务器内存为56GB,这样的话系统可以用剩下的8G来消耗和工作。
2.并行开销阈值(Cost Threshold for Parallelism)
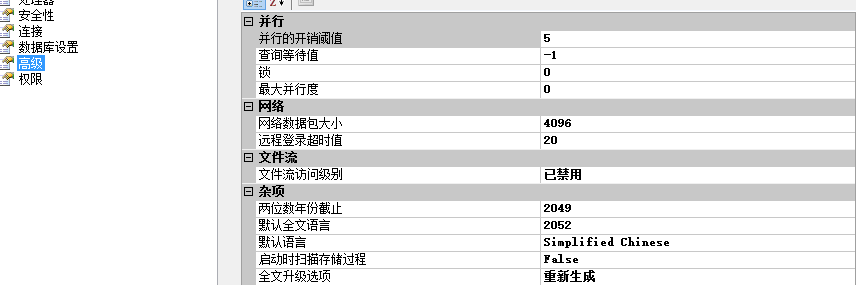
这里你配置的数字定义查询成本,查询优化器用它来找更便宜的并行执行计划。如果找到的并行计划更便宜,这个计划会被执行,不然串行计划会被执行。从刚才的图你可以看到,
SQL Server默认配置使用5的成本阈值。当你的串行计划查询成本大于5,然后查询优化器再次运行查询优化来找更便宜并行执行计划的可能。
遗憾的是,5的成本值当下来说是个很小的数字。因此SQL Server太快尝试并行你的执行计划。当你处理更大的查询并行才有意义——例如报表或数据仓库情形。
在纯OLTP情形下,并行计划象征着糟糕的索引设计,因为当你有缺失索引时,SQL Server需要扫描你的整个聚集索引(在与过滤(Filter)和剩余谓语(residual predicate)组合里),
因此你的查询成本越来越大,它们穿过成本阈值,最后查询优化器给你并行计划。当人们看到并行计划时,总会担心!但问题根源是缺失非聚集索引。
对于并行的成本阈值,我总推荐至少20,甚至50。那样的话,你确保SQL Server只为你对更大的查询进行并行。即使在你面前有个并行计划,
你也应该考虑下可否通过增加一个支持的非聚集索引来是这个查询成本更低。另外,CXPACKET并不象征着在你的系统里你有并行问题!
3.最大并行度(Max Degree of Parallelism (MAXDOP))
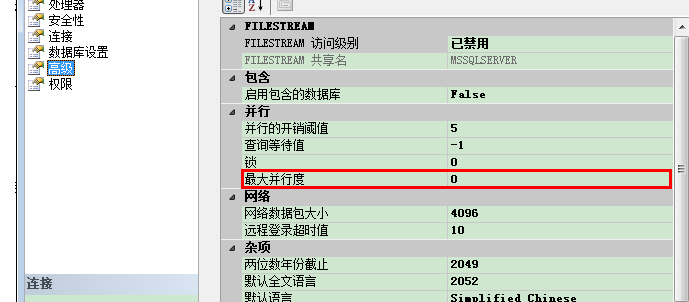
如你所见,SQL Server使用默认值0。这个值意味着SQL Server尝试并行化你的执行计划穿过分配给SQL Server的所有CPU内核(默认情况所有内核都分配给SQL Server!)。
你应该能看出这样的设置没有意义,尤其当你有大量CPU内核的系统。并行化本身带来负担,一旦你使用越多的工作线程,这个负担越大。
一个建议是设置最大并行度为在一个NUMA结点里拥有的内核数。因此在查询执行时,SQL Server会尝试在一个NUMA结点里保持并行计划,这也会提高性能。
有时你也会看到建议去设置最大并行度为1。这个是不好的建议,因为这个使你的“整个”SQL Server 单线程!即使维护操作(例如索引重建)已单线程执行,这会严重伤及性能!
SQL Serve里DBA要去改变的3个配置选项的更多相关文章
- SQL Serve里你总要去改变的3个配置选项
你用安装向导安装了全新的SQL Server,最后你点击了完成按钮.哇噢~~~现在我们可以把我们的服务器进入生产了!抱歉,那并不是真的,因为你的全新SQL Server默认配置是错误的. 是的,你没看 ...
- 在SQL Serve里停用行和页层级锁
今天我想谈下SQL Server里另一个非常有趣的话题:在SQL Server里停用行和页层级锁.在SQL Server里,每次你重建一个索引,你可以使用ALLOW_ROW_LOCKS 和ALLOW_ ...
- SQL Server里的自旋锁介绍
在上一篇文章里我讨论了SQL Server里的闩锁.在文章的最后我给你简单介绍了下自旋锁(Spinlock).基于那个基础,今天我会继续讨论SQL Server中的自旋锁,还有给你展示下如何对它们进行 ...
- 在SQL Server里如何处理死锁
在今天的文章里,我想谈下SQL Server里如何处理死锁.当2个查询彼此等待时会发生死锁,没有一个查询可以继续它们的操作.首先我想给你大致讲下SQL Server如何处理死锁.最后我会展示下SQL ...
- SQL Server里如何处理死锁
在今天的文章里,我想谈下SQL Server里如何处理死锁.当2个查询彼此等待时会发生死锁,没有一个查询可以继续它们的操作.首先我想给你大致讲下SQL Server如何处理死锁.最后我会展示下SQL ...
- SQL Server里如何处理死锁 (转)
http://www.cnblogs.com/woodytu/p/6437049.html 在今天的文章里,我想谈下SQL Server里如何处理死锁.当2个查询彼此等待时会发生死锁,没有一个查询可以 ...
- SQL Server里的闩锁介绍
在今天的文章里我想谈下SQL Server使用的更高级的,轻量级的同步对象:闩锁(Latch).闩锁是SQL Server存储引擎使用轻量级同步对象,用来保护多线程访问内存内结构.文章的第1部分我会介 ...
- 在SQL Server里如何进行页级别的恢复
在今天的文章里我想谈下每个DBA应该知道的一个重要话题:在SQL Server里如何进行页级别还原操作.假设在SQL Server里你有一个损坏的页,你要从最近的数据库备份只还原有问题的页,而不是还原 ...
- 在SQL Server里如何进行数据页级别的恢复
在SQL Server里如何进行页级别的恢复 关键词:数据页修复 在今天的文章里我想谈下每个DBA应该知道的一个重要话题:在SQL Server里如何进行页级别还原操作.假设在SQL Server里你 ...
随机推荐
- zip,rar及linux下常用的压缩格式
日常操作中我们经常使用到文件压缩操作,其使用一些特定的算法来减小文件的大小,可以提高传输数据时的速率和减少数据在一些存储机制上占有的空间大小,实现空间利用最大化. 比如:如果你想通过邮箱发送一个文件夹 ...
- CodeForces - 5C(思维+括号匹配)
题意 https://vjudge.net/problem/CodeForces-5C 给出一个括号序列,求出最长合法子串和它的数量. 合法的定义:这个序列中左右括号匹配. 思路 这个题和普通的括号匹 ...
- React每隔0.2s颜色变淡 之生命周期 ,componentDidMount表示组件已经挂载
05案例 每隔0.2s颜色变淡 componentDidMount表示组件已经挂载,可以进行DOM操作 import React, { Component } from "react&quo ...
- C#/.Net开发入门篇(3)——console类的输入输出
相信看了我上一篇文章的小伙伴们都知道console这个类的最基本的2个方法了吧,下去练习过的小伙伴应该能知道4个方法. 那么下面我们就来介绍一下上期没有介绍完的另外2个方法Console.WriteL ...
- C# copy folder and files from source path to target path
static void Main(string[] args) { string sourceDir = @"E:\SourcePath"; string destDir = @& ...
- P1356 数列的整除性
dp百题进度条[2/100] 题目链接 题目描述 对于任意一个整数数列,我们可以在每两个整数中间任意放一个符号'+'或'-',这样就可以构成一个表达式,也就可以计算出表达式的值.比如,现在有一个整数数 ...
- Create a Report at Runtime 在运行时创建报表
In this lesson, you will learn how to create reports at runtime. A report showing a list of Tasks wi ...
- Android 网络交互之移动端与服务端的加密处理
在开发项目的网络模块时,我们为了保证客户端(Client)和服务端(Server)之间的通信安全,我们会对数据进行加密. 谈到网络通信加密,我们可以说出:对称加密,非对称加密,md5单向加密,也能提到 ...
- 4、netty第三个例子,建立一个tcp的聊天的程序
代码基于第二个例子,支持多客户端的连接,在线聊天. 主要思路: 连接建立时,在服务器端,保存channel 对象,当有新的客户端加入时,遍历保存的channel集合,向其他客户端发送加入消息. 当一个 ...
- R-6 线性回归模型流程
本节内容: 0:小知识 1:新数据要如何进行分析 2:第二步骤:理解数据 3:第三步骤:相关分析 4:特殊点 0:小知识 0.1:我们说对分析一个数据一般是分步骤的:那么我们可以对其中的步骤进行打标签 ...