python计算不规则图形面积算法
介绍:大三上做一个医学影像识别的项目,医生在原图上用红笔标记病灶点,通过记录红色的坐标位置可以得到病灶点的外接矩形,但是后续会涉及到红圈内的面积在外接矩形下的占比问题,有些外接矩形内有多个红色标记,在使用网上的opencv的fillPoly填充效果非常不理想,还有类似python计算任意多边形方法也不理想的情况下,自己探索出的一种效果还不错的计算多圈及不规则图形的面积的算法。
医生提供的病灶标记图和原图,大部分长这样
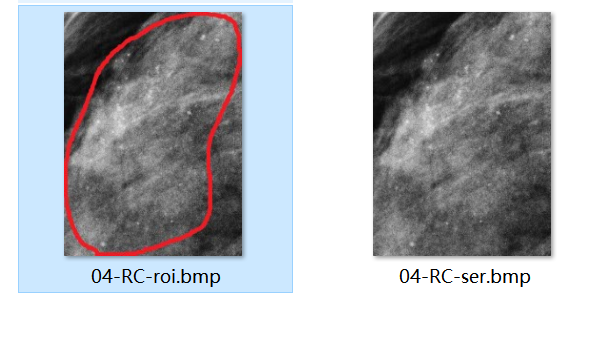
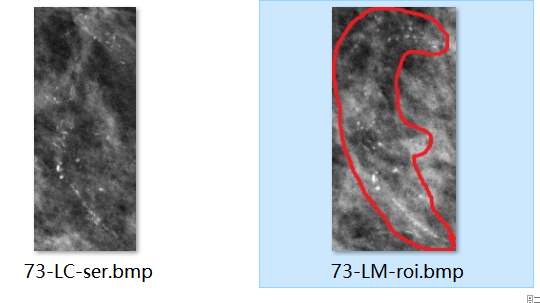
但也有一些多圈情况


很明显,这些图片都是非常需要计算面积占比的,对样本需要筛选
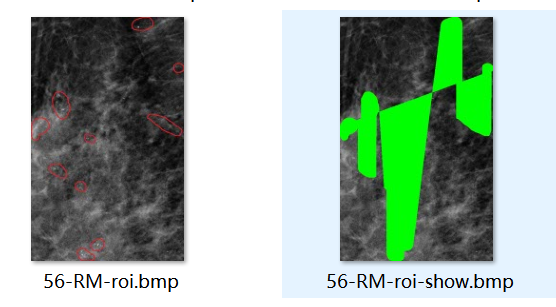
通过百度,用opencv的填充来计算面积,一部分效果很差,单圈画不全,多圈都是错(用将面积计算结果上色,方便观察)


通过此算法之后,无论单圈,多圈,面积计算准确度提高许多



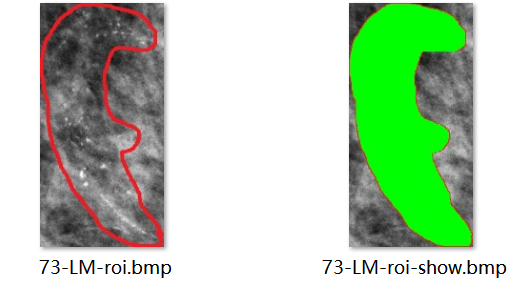
能较为准确的计算出不规则图形的面积
正文:算法的思想很简单,遍历图片每一列,通过色差判断是否遇到标记圈,将坐标全部记录,对每一列的坐标都进行最小行和最大行记录,确定每一列的最小和最大的坐标,然后上色(类似opencv的fillPoly的实现,但是细节有些区别),只是这样效果并不好,将图片旋转90度,再做一边,将两个图片的结果放在一起做与操作,得到结果就能很好的处理多圈的标记问题和多算面积的问题(比如上面的08-LM),
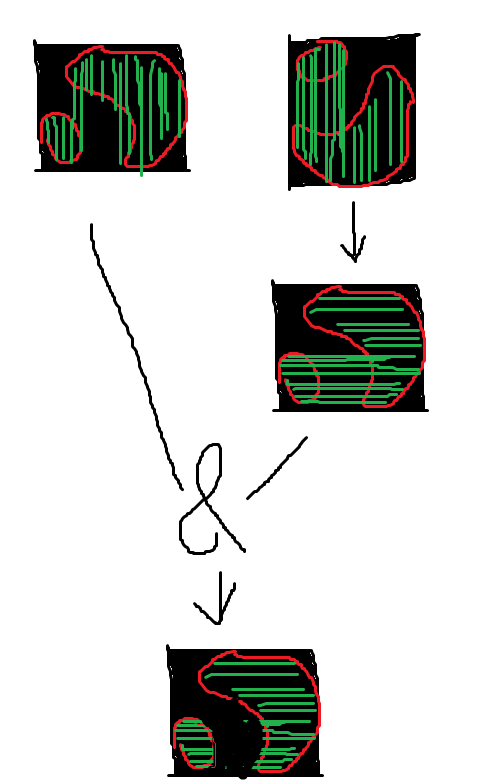
算法实现
全程只用pillow库
首先先用屏幕拾色器获取目标颜色的rgb值,我这种情况下就是(237,28,36),前期截取外接矩形也是要这一步的,颜色也一致
def pixel_wanted(pix):
return pix==(237,28, 36)
每一列都设定翻转位初始为False,如果上一个像素点不是目标色,当前是目标色则开始记录,一旦不是目标色,停止检测
top_Pixel都设定为黑色(0,0,0)因为有图片最上方就是目标色,导致判定出问题,直接让最上面的像素初始化是黑色
coordinate_List记录了所有符合的点坐标
coordinate_List = []
top_Pixel = (0,0,0)
for x in range(im.size[0]):
flag = False #初始化每一列翻转位为False
for y in range(im.size[1]):
current_pixel = im.getpixel((x,y))
last_pixel = im.getpixel((x,y-1)) if y>0 else top_Pixel
#翻转判定
if pixel_wanted(current_pixel) and \
not pixel_wanted(last_pixel):
flag = True
if flag and not pixel_wanted(current_pixel):
flag = False
if(flag):
coordinate_List.append((x,y))
coordinate_List中的点如下图

然后就是将上面获得coordinate列表进行处理
将coordinate列表中每一列的最小坐标和最大坐标进行记录
因为每一列记录的数量并不确定(应该可以在上一步改进一下),所以需要遍历多次
首先找到第一个列出现的坐标,将它的行信息记录(行信息最小确定),
然后遍历出全部的同列的坐标,比较行坐标,如果大的就将最大的代替(行信息最大确定),用一个新的列表记录数据
coordinate_Min_Max_List = []
#找最小最大
for i in range(im.size[0]):
min=-1
max=-1
for coordinate in coordinate_List:
if coordinate[0] == i:
min = coordinate[1]
max = coordinate[1]
break
for coordinate in coordinate_List:
if coordinate[0] == i:
if coordinate[1]>max:
max = coordinate[1]
coordinate_Min_Max_List.append(min)
coordinate_Min_Max_List.append(max)
其中要将min和max都初始化为一个坐标不存在的值比如-1,为了在下一步多圈且有空隙情况下,不会出现残影现象,如下图
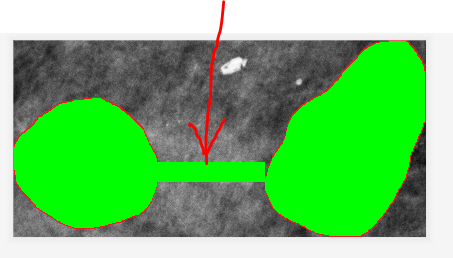

上一步的最后得到一个列表,第n列的最小行和最大行分别是第2n和2n+1元素,结果中的-1,为了让下一步不会画进去

然后就是绘制图片了,每一列将列表中对应的最小行到最大行涂满
#上色
for x in range(im.size[0]):
for y in range(im.size[1]):
min = coordinate_Min_Max_List[x*2]
max = coordinate_Min_Max_List[x*2+1]
if min<y<max:
im.putpixel((x,y),(0,255,0))
else:
#可以把非红圈的上掩膜遮住
pass
至此,就是类似opencv的算法实现,虽然还差翻转做与操作,但是已经比opencv生成的效果好,写成函数后续调用,
然后就是简单的翻转90度,再调用一次这个函数再做一遍
def Cal_S(im):
im_0 = im.rotate(0)
im_90 = im.rotate(90, expand=True) im_0 = fillPoly(im_0)
im_90 = fillPoly(im_90)
im_90 = im_90.rotate(-90, expand=True) i=0
for x in range(im.size[0]):
for y in range(im.size[1]):
if(im_0.getpixel((x,y))==(0,255,0) and
im_90.getpixel((x,y))==(0,255,0)):
im.putpixel((x,y),(0,255,0))
i+=1
return i/(im.size[0]*im.size[1])
做两遍的效果图


可以看到效果非常不错,但是依旧有个别图像有问题,比如十字分布的,
但现在的话误差已经降低非常多了,这些极其个别的十字现象可以手动把原图切割一下,或者干脆不处理了
所有代码,画出绿图片为了方便直观的查看,函数中可以把图片顺便保存一下,总体看一下效果
from PIL import Image def pixel_wanted(pix):
return pix==(237,28, 36) def fillPoly(im):
coordinate_List = [] top_Pixel = (0,0,0)
for x in range(im.size[0]):
flag = False #初始化每一列翻转位为False
for y in range(im.size[1]):
current_pixel = im.getpixel((x,y))
last_pixel = im.getpixel((x,y-1)) if y>0 else top_Pixel
#翻转判定
if pixel_wanted(current_pixel) and \
not pixel_wanted(last_pixel):
flag = True
if flag and not pixel_wanted(current_pixel):
flag = False
if(flag):
coordinate_List.append((x,y))
coordinate_Min_Max_List = []
#找最小最大
for i in range(im.size[0]):
min=-1
max=-1
for coordinate in coordinate_List:
if coordinate[0] == i:
min = coordinate[1]
max = coordinate[1]
break
for coordinate in coordinate_List:
if coordinate[0] == i:
if coordinate[1]>max:
max = coordinate[1]
coordinate_Min_Max_List.append(min)
coordinate_Min_Max_List.append(max)
#上色
for x in range(im.size[0]):
for y in range(im.size[1]):
min = coordinate_Min_Max_List[x*2]
max = coordinate_Min_Max_List[x*2+1]
if min<y<max:
im.putpixel((x,y),(0,255,0))
else:
#可以把非红圈的上掩膜遮住
pass
return im def Cal_S(im):
im_0 = im.rotate(0)
im_90 = im.rotate(90, expand=True) im_0 = fillPoly(im_0)
im_90 = fillPoly(im_90)
im_90 = im_90.rotate(-90, expand=True) i=0
for x in range(im.size[0]):
for y in range(im.size[1]):
if(im_0.getpixel((x,y))==(0,255,0) and
im_90.getpixel((x,y))==(0,255,0)):
im.putpixel((x,y),(0,255,0))
i+=1
return i/(im.size[0]*im.size[1])
python计算不规则图形面积算法的更多相关文章
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- python 计算校验和
校验和是经常使用的,这里简单的列了一个针对按字节计算累加和的代码片段.其实,这种累加和的计算,将字节翻译为无符号整数和带符号整数,结果是一样的. 使用python计算校验和时记住做截断就可以了. 这里 ...
- 用Python实现随机森林算法,深度学习
用Python实现随机森林算法,深度学习 拥有高方差使得决策树(secision tress)在处理特定训练数据集时其结果显得相对脆弱.bagging(bootstrap aggregating 的缩 ...
- Python实现 K_Means聚类算法
使用 Python实现 K_Means聚类算法: 问题定义 聚类问题是数据挖掘的基本问题,它的本质是将n个数据对象划分为 k个聚类,以便使得所获得的聚类满足以下条件: 同一聚类中的数据对象相似度较高 ...
- 如何用Python实现常见机器学习算法-1
最近在GitHub上学习了有关python实现常见机器学习算法 目录 一.线性回归 1.代价函数 2.梯度下降算法 3.均值归一化 4.最终运行结果 5.使用scikit-learn库中的线性模型实现 ...
- 使用python模拟实现KNN算法
一.KNN简介 1.KNN算法也称为K邻近算法,是数据挖掘分类技术之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表. 2.KNN算法的核心思想是如果一个样本 ...
- python 的常见排序算法实现
python 的常见排序算法实现 参考以下链接:https://www.cnblogs.com/shiluoliming/p/6740585.html 算法(Algorithm)是指解题方案的准确而完 ...
- [转载] python 计算字符串长度
本文转载自: http://www.sharejs.com/codes/python/4843 python 计算字符串长度,一个中文算两个字符,先转换成utf8,然后通过计算utf8的长度和len函 ...
- Python实现各种排序算法的代码示例总结
Python实现各种排序算法的代码示例总结 作者:Donald Knuth 字体:[增加 减小] 类型:转载 时间:2015-12-11我要评论 这篇文章主要介绍了Python实现各种排序算法的代码示 ...
随机推荐
- DesignPattern系列__08UML相关知识
前言 现在,很少有人和90年代一样,自己去实现一个软件的各个方面,也就是说,在工作中,和人沟通是必备的技能.那么,作为一枚码农,如何和他人沟通呢?这就要依靠本文的主题了--UML. 简介 UML--U ...
- 为Dynamics 365 USD设置使用Chrome进程来驻留Web应用程序
我是微软Dynamics 365 & Power Platform方面的工程师罗勇,也是2015年7月到2018年6月连续三年Dynamics CRM/Business Solutions方面 ...
- .net4.0使用Dapper操作MySql
准备使用Dapper操作MySql,由于电脑只有vs2010,所以需要Dapper和MySql组件支持.net 4.0.经过一番测试,终于弄出一个DEMO. 1.操作MySql需要用MySql.Dat ...
- 一文解读AIoT (转)
AIoT即AI+IoT,指的是人工智能技术与物联网在实际应用中的落地融合.目前,越来越多的行业及应用将AI与IoT结合到了一起,AIoT已经成为各大传统行业智能化升级的最佳通道,也是未来物联网发展的重 ...
- 有趣的bug——Java静态变量的循环依赖
背景 是的,标题没有错误,不是Spring Bean的循环依赖,而是静态变量之间的循环依赖. 近期的项目均是简单的Maven项目,通过K8S部署在阿里云上,其配置文件读取规则如下所示: (1) 优先读 ...
- express 将 Router 实例模块化
为了更好的组织代码,将 Router 实例进行模块化,将 get / post 等快捷方式放在Router上,而不是 App 上,然后将该 Router 作为中间件,use 到 server.js 上 ...
- (四)Amazon Lightsail 部署LAMP应用程序之扩展PHP前端
扩展PHP前端 既然PHP前端和数据库是分开的,您将为Web层添加可伸缩性和容错性: 在以下步骤,您将获取Web前端实例的快照,并从该快照部署另外2个Web层实例.最终,您将在三个Web实例前面添加一 ...
- centos7虚拟机端口命令
cat /etc/redhat-release # 查看centos 版本 Centos7端口常见命令 虚拟机新开了5005端口,系统内部是显示开了的,但是外部不能访问端口. 一些需要用到的命令: ...
- 题解:swj社会摇进阶第二课
题目链接 思路:按题目推一点点可以得出答案为 sigma (i-k)*n/i+d(n%i>=k) #include<bits/stdc++.h> using namespace st ...
- QTP10启动错误:Error creatingUnable to create configuration directory "C:UsersmR?ã? directory entry
安装完之后打开就一直: 百度也不知道为哈子(莫非是中文的用户名?反正我不想重装系统),真是很气人. 我就直接创建了一个临时账户,登陆进去,就可以运行了: