Java集合中List、Set以及Map
概述:
- List , Set, Map都是接口;List , Set继承至Collection接口,Map为独立接口
- Set下有HashSet,LinkedHashSet,TreeSet
- List下有ArrayList,Vector,LinkedList
- Map下有Hashtable,LinkedHashMap,HashMap,TreeMap
- Collection接口下还有个Queue接口,有PriorityQueue类

注意:
- Queue接口与List、Set同一级别,都是继承了Collection接口。
- 看图你会发现,LinkedList既可以实现Queue接口,也可以实现List接口.只不过呢, LinkedList实现了Queue接口。Queue接口窄化了对LinkedList的方法的访问权限(即在方法中的参数类型如果是Queue时,就完全只能访问Queue接口所定义的方法 了,而不能直接访问 LinkedList的非Queue的方法),以使得只有恰当的方法才可以使用。
- SortedSet是个接口,它里面的(只有TreeSet这一个实现可用)中的元素一定是有序的。
总结:
Connection接口:
— List 有序,可重复
- ArrayList
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高 - Vector
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低 - LinkedList
优点: 底层数据结构是链表,查询慢,增删快。
缺点: 线程不安全,效率高
—Set 无序,唯一
HashSet
底层数据结构是哈希表。(无序,唯一)
如何来保证元素唯一性?
1.依赖两个方法:hashCode()和equals()
LinkedHashSet
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一
TreeSet
底层数据结构是红黑树。(唯一,有序)
1. 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
针对Collection集合我们到底使用谁呢?(掌握)
唯一吗? 是:Set 排序吗? 是:TreeSet或LinkedHashSet
否:HashSet
如果你知道是Set,但是不知道是哪个Set,就用HashSet。
否:List 要安全吗? 是:Vector
否:ArrayList或者LinkedList 查询多:ArrayList
增删多:LinkedList
如果你知道是List,但是不知道是哪个List,就用ArrayList。
如果你知道是Collection集合,但是不知道使用谁,就用ArrayList。
如果你知道用集合,就用ArrayList。
说完了Collection,来简单说一下Map.
Map接口:
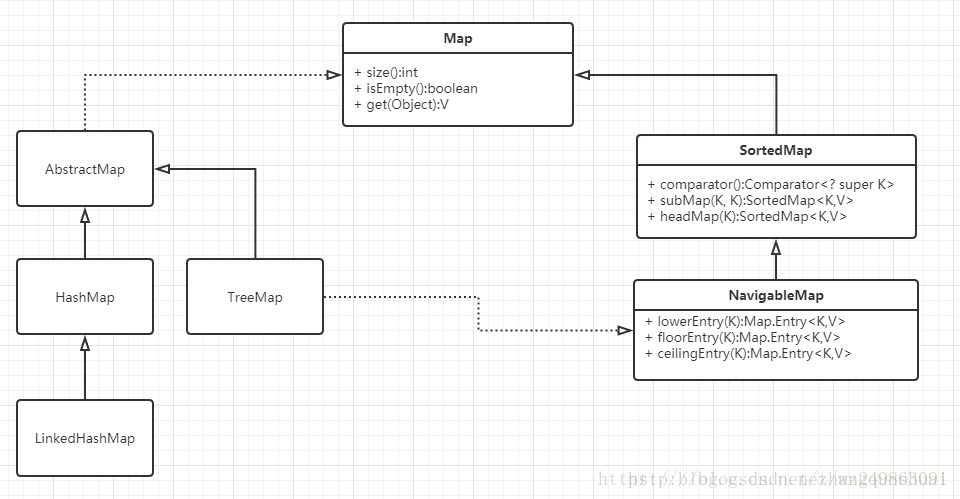
Map接口有三个比较重要的实现类,分别是HashMap、TreeMap和HashTable。
- TreeMap是有序的,HashMap和HashTable是无序的。
- Hashtable的方法是同步的,HashMap的方法不是同步的。这是两者最主要的区别。
这就意味着:
- Hashtable是线程安全的,HashMap不是线程安全的。
- HashMap效率较高,Hashtable效率较低。如果对同步性或与遗留代码的兼容性没有任何要求,建议使用HashMap。 查看Hashtable的源代码就可以发现,除构造函数外,Hashtable的所有 public 方法声明中都有 synchronized关键字,而HashMap的源码中则没有。
- Hashtable不允许null值,HashMap允许null值(key和value都允许)
- 父类不同:Hashtable的父类是Dictionary,HashMap的父类是AbstractMap
重点问题重点分析:
(一).TreeSet, LinkedHashSet and HashSet 的区别
1. 介绍
TreeSet, LinkedHashSet and HashSet 在java中都是实现Set的数据结构
- TreeSet的主要功能用于排序
- LinkedHashSet的主要功能用于保证FIFO即有序的集合(先进先出)
- HashSet只是通用的存储数据的集合
2. 相同点
- Duplicates elements: 因为三者都实现Set interface,所以三者都不包含duplicate elements
- Thread safety: 三者都不是线程安全的,如果要使用线程安全可以Collections.synchronizedSet()
3. 不同点
- Performance and Speed: HashSet插入数据最快,其次LinkHashSet,最慢的是TreeSet因为内部实现排序
- Ordering: HashSet不保证有序,LinkHashSet保证FIFO即按插入顺序排序,TreeSet安装内部实现排序,也可以自定义排序规则
- null:HashSet和LinkHashSet允许存在null数据,但是TreeSet中插入null数据时会报NullPointerException
4. 代码比较
public static void main(String args[]) {
HashSet<String> hashSet = new HashSet<>();
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
TreeSet<String> treeSet = new TreeSet<>();
for (String data : Arrays.asList("B", "E", "D", "C", "A")) {
hashSet.add(data);
linkedHashSet.add(data);
treeSet.add(data);
}
//不保证有序
System.out.println("Ordering in HashSet :" + hashSet);
//FIFO保证安装插入顺序排序
System.out.println("Order of element in LinkedHashSet :" + linkedHashSet);
//内部实现排序
System.out.println("Order of objects in TreeSet :" + treeSet);
}
运行结果:
Ordering in HashSet :[A, B, C, D, E] (无顺序)
Order of element in LinkedHashSet :[B, E, D, C, A] (FIFO插入有序)
Order of objects in TreeSet :[A, B, C, D, E] (排序)
(二).TreeSet的两种排序方式比
1.排序的引入(以基本数据类型的排序为例)
由于TreeSet可以实现对元素按照某种规则进行排序,例如下面的例子
public class MyClass {
public static void main(String[] args) {
// 创建集合对象
// 自然顺序进行排序
TreeSet<Integer> ts = new TreeSet<Integer>();
// 创建元素并添加
// 20,18,23,22,17,24,19,18,24
ts.add();
ts.add();
ts.add();
ts.add();
ts.add();
ts.add();
ts.add();
ts.add();
ts.add();
// 遍历
for (Integer i : ts) {
System.out.println(i);
}
}
}
运行结果:
17
18
19
20
22
23
24
2.如果是引用数据类型呢,比如自定义对象,又该如何排序呢?
测试类:
public class MyClass {
public static void main(String[] args) {
TreeSet<Student> ts=new TreeSet<Student>();
//创建元素对象
Student s1=new Student("zhangsan",);
Student s2=new Student("lis",);
Student s3=new Student("wangwu",);
Student s4=new Student("chenliu",);
Student s5=new Student("zhangsan",);
Student s6=new Student("qianqi",);
//将元素对象添加到集合对象中
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
//遍历
for(Student s:ts){
System.out.println(s.getName()+"-----------"+s.getAge());
}
}
}
Student.java:
public class Student {
private String name;
private int age;
public Student() {
super();
// TODO Auto-generated constructor stub
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
结果报错:

原因分析:
由于不知道该安照那一中排序方式排序,所以会报错。
解决方法:
1.自然排序
2.比较器排序
(1).自然排序
自然排序要进行一下操作:
1.Student类中实现 Comparable接口
2.重写Comparable接口中的Compareto方法
compareTo(To) 比较此对象与指定对象的顺序。
public class Student implements Comparable<Student>{
private String name;
private int age;
public Student() {
super();
// TODO Auto-generated constructor stub
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Student s) {
//return -1; //-1表示放在红黑树的左边,即逆序输出
//return 1; //1表示放在红黑树的右边,即顺序输出
//return o; //表示元素相同,仅存放第一个元素
//主要条件 姓名的长度,如果姓名长度小的就放在左子树,否则放在右子树
int num=this.name.length()-s.name.length();
//姓名的长度相同,不代表内容相同,如果按字典顺序此 String 对象位于参数字符串之前,则比较结果为一个负整数。
//如果按字典顺序此 String 对象位于参数字符串之后,则比较结果为一个正整数。
//如果这两个字符串相等,则结果为 0
int num1=num==?this.name.compareTo(s.name):num;
//姓名的长度和内容相同,不代表年龄相同,所以还要判断年龄
int num2=num1==?this.age-s.age:num1;
return num2;
}
}
运行结果:
lis-----------22
qianqi-----------24
wangwu-----------24
chenliu-----------26
zhangsan-----------20
zhangsan-----------22
(2).比较器排序
比较器排序步骤:
1.单独创建一个比较类,这里以MyComparator为例,并且要让其继承Comparator接口
2.重写Comparator接口中的Compare方法
compare(T o1,T o2) 比较用来排序的两个参数。
3.在主类中使用下面的 构造方法
TreeSet(Comparator<? superE> comparator) 构造一个新的空 TreeSet,它根据指定比较器进行排序。
测试类:
public class MyClass {
public static void main(String[] args) {
//创建集合对象
//TreeSet(Comparator<? super E> comparator) 构造一个新的空 TreeSet,它根据指定比较器进行排序。
TreeSet<Student> ts=new TreeSet<Student>(new MyComparator());
//创建元素对象
Student s1=new Student("zhangsan",);
Student s2=new Student("lis",);
Student s3=new Student("wangwu",);
Student s4=new Student("chenliu",);
Student s5=new Student("zhangsan",);
Student s6=new Student("qianqi",);
//将元素对象添加到集合对象中
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
//遍历
for(Student s:ts){
System.out.println(s.getName()+"-----------"+s.getAge());
}
}
}
Student.java:
public class Student {
private String name;
private int age;
public Student() {
super();
// TODO Auto-generated constructor stub
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
MyComparator类:
public class MyComparator implements Comparator<Student> {
@Override
public int compare(Student s1,Student s2) {
// 姓名长度
int num = s1.getName().length() - s2.getName().length();
// 姓名内容
int num2 = num == ? s1.getName().compareTo(s2.getName()) : num;
// 年龄
int num3 = num2 == ? s1.getAge() - s2.getAge() : num2;
return num3;
}
}
运行结果:
lis-----------22
qianqi-----------24
wangwu-----------24
chenliu-----------26
zhangsan-----------20
zhangsan-----------22
(三). 性能测试
对象类:
class Dog implements Comparable<Dog> {
int size;
public Dog(int s) {
size = s;
}
public String toString() {
return size + "";
}
@Override
public int compareTo(Dog o) {
//数值大小比较
return size - o.size;
}
}
主类:
public class MyClass {
public static void main(String[] args) {
Random r = new Random();
HashSet<Dog> hashSet = new HashSet<Dog>();
TreeSet<Dog> treeSet = new TreeSet<Dog>();
LinkedHashSet<Dog> linkedSet = new LinkedHashSet<Dog>();
// start time
long startTime = System.nanoTime();
for (int i = ; i < ; i++) {
int x = r.nextInt( - ) + ;
hashSet.add(new Dog(x));
}
// end time
long endTime = System.nanoTime();
long duration = endTime - startTime;
System.out.println("HashSet: " + duration);
// start time
startTime = System.nanoTime();
for (int i = ; i < ; i++) {
int x = r.nextInt( - ) + ;
treeSet.add(new Dog(x));
}
// end time
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("TreeSet: " + duration);
// start time
startTime = System.nanoTime();
for (int i = ; i < ; i++) {
int x = r.nextInt( - ) + ;
linkedSet.add(new Dog(x));
}
// end time
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("LinkedHashSet: " + duration);
}
}
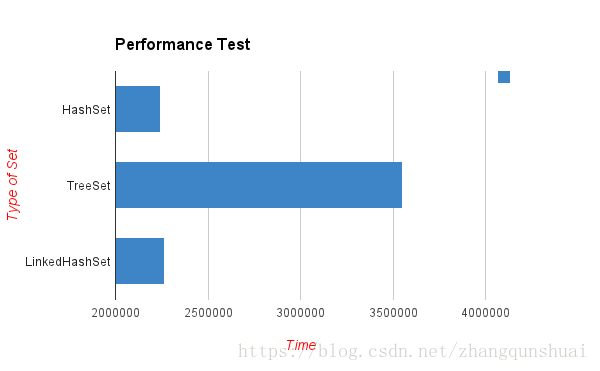
运行结果:
HashSet: 1544313
TreeSet: 2066049
LinkedHashSet: 629826
虽然测试不够准确,但能反映得出,TreeSet要慢得多,因为它是有序的。
转载请注明出处:Java集合中List,Set以及Map等集合体系详解
Java集合中List、Set以及Map的更多相关文章
- Java集合中List,Set以及Map等集合体系详解
转载请注明出处:Java集合中List,Set以及Map等集合体系详解(史上最全) 概述: List , Set, Map都是接口,前两个继承至collection接口,Map为独立接口 Set下有H ...
- 史上最全Java集合中List,Set以及Map等集合体系详解
一.概述 List , Set, Map都是接口,前两个继承至collection接口,Map为独立接口 Set下有HashSet,LinkedHashSet,TreeSet List下有ArrayL ...
- Java集合中List,Set以及Map等集合体系详解(史上最全)
https://blog.csdn.net/zhangqunshuai/article/details/80660974
- Java集合中的LinkedHashMap类
jdk1.8.0_144 本文阅读最好先了解HashMap底层,可前往<Java集合中的HashMap类>. LinkedHashMap由于它的插入有序特性,也是一种比较常用的Map集合. ...
- Java集合(十)实现Map接口的HashMap
Java集合(十)继承Map接口的HashMap 一.HashMap简介(基于JDK1.8) HashMap是基于哈希表(散列表),实现Map接口的双列集合,数据结构是“链表散列”,也就是数组+链表 ...
- java集合中List与set的区别
java集合中List与set的区别. List可以存储元素为有序性并且元素可以相同. set存储元素为无序性并且元素不可以相同. 下面贴几段代码感受一下: ArrayL ...
- Java集合中Comparator和Comparable接口的使用
在Java集合中,如果要比较引用类型泛型的List,我们使用Comparator和Comparable两个接口. Comparable接口 -- 默认比较规则,可比较的 实现该接口表示:这个类的实例可 ...
- Java集合中Set的常见问题及用法
在这里演示的案例是衔接Java集合中的List(点击查看)那篇博文的,本节我们学习的Set的用法. Set是Collection的一个重要的子接口,Set中的元素是无序排列的,并且元素不可以重复,被称 ...
- Java集合中迭代器的常用用法
该例子展示了一个Java集合中迭代器的常用用法public class LinkedListTest { public static void main(String[] args) { List&l ...
随机推荐
- 用jquery实现放大镜效果
----css代码--- *{margin:0;padding:0;} .showimg{position:relative;width:450px;height:420px;border:1px s ...
- 【0806 | Day 9】异常处理/基本的文件操作
一.异常处理 异常即报错,可分为语法异常和逻辑异常 1. 语法异常 举个栗子 if #报错 syntaxerror 0 = 1 #报错 syntaxerror ... 正经地举个栗子 print(1) ...
- JavaFx应用 星之小说下载器
星之小说下载器 说明: 需要jdk环境 目前只支持铅笔小说网,后续添加更多书源,还有安卓版,敬请期待. 喜欢的话,不妨打赏一波! 软件交流QQ群:690380139 断点下载暂未实现,小说下载途中,一 ...
- java高并发系列 - 第24天:ThreadLocal、InheritableThreadLocal(通俗易懂)
java高并发系列第24篇文章. 环境:jdk1.8. 本文内容 需要解决的问题 介绍ThreadLocal 介绍InheritableThreadLocal 需要解决的问题 我们还是以解决问题的方式 ...
- Java连载16-++传参&关系运算符
一.++再举例 int a = 10; System.out.print(a++);//这里会打印出10,因为他们内部这个print函数有参数相当于参数x=a++ System.out.println ...
- Mybatis学习笔记之---多表查询(1)
Mybatis多表查询(1) (一)举例(用户和账户) 一个用户可以有多个账户 一个账户只能属于一个用户(多个账户也可以属于同一个用户) (二)步骤 1.建立两张表:用户表,账户表,让用户表和账户表之 ...
- cs231n---卷积网络可视化,deepdream和风格迁移
本课介绍了近年来人们对理解卷积网络这个“黑盒子”所做的一些可视化工作,以及deepdream和风格迁移. 1 卷积网络可视化 1.1 可视化第一层的滤波器 我们把卷积网络的第一层滤波器权重进行可视化( ...
- 从IDEA角度来看懂UML图
前言 我们目前已经学习了设计模式的7种设计原则.下面本该是直接进入具体的设计模式系列文章. 但是呢在我们学习设计模式之前我们还是有必要了解一下uml图.因为后续的设计模式文章不出意外应该会很多地方使用 ...
- K8S搭建-1 Master 2 Workers(dashboard+ingress)
本文讲述k8s最新版的搭建(v1.15.2) 分如下几个topic步骤: 各个节点的基本配置 master节点的构建 worker节点的构建 安装dashboard 安装ingress 常见命令 do ...
- tensorflow学习笔记——多线程输入数据处理框架
之前我们学习使用TensorFlow对图像数据进行预处理的方法.虽然使用这些图像数据预处理的方法可以减少无关因素对图像识别模型效果的影响,但这些复杂的预处理过程也会减慢整个训练过程.为了避免图像预处理 ...