使用scrapy-redis搭建分布式爬虫环境
scrapy-redis简介
scrapy-redis是scrapy框架基于redis数据库的组件,用于scrapy项目的分布式开发和部署。
有如下特征:
分布式爬取
您可以启动多个spider工程,相互之间共享单个redis的requests队列。最适合广泛的多个域名网站的内容爬取。
分布式数据处理
爬取到的scrapy的item数据可以推入到redis队列中,这意味着你可以根据需求启动尽可能多的处理程序来共享item的队列,进行item数据持久化处理
Scrapy即插即用组件
Scheduler调度器 + Duplication复制 过滤器,Item Pipeline,基本spider
scrapy-redis架构
scrapy-redis整体运行流程如下:
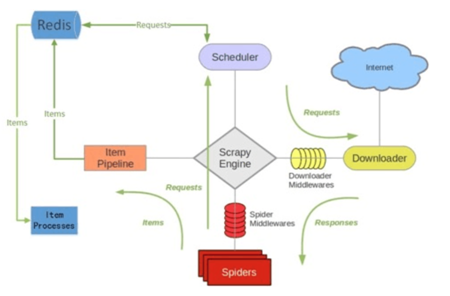
1. 首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
2. Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),
可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
scrapy-redis安装
通过pip安装即可:pip install scrapy-redis
一般需要python、redis、scrapy这三个安装包
官方文档:https://scrapy-redis.readthedocs.io/en/stable/
源码位置:https://github.com/rmax/scrapy-redis
参考博客:https://www.cnblogs.com/kylinlin/p/5198233.html
scrapy-redis常用配置
一般在配置文件中添加如下几个常用配置选项:
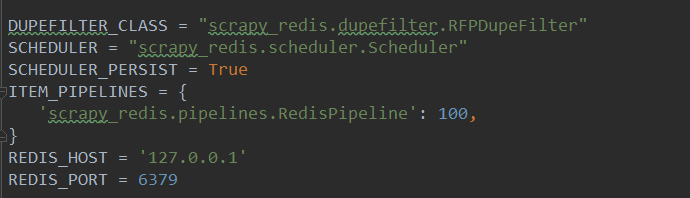
1(必须). 使用了scrapy_redis的去重组件,在redis数据库里做去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
2(必须). 使用了scrapy_redis的调度器,在redis里分配请求
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
3(可选). 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True
4(必须). 通过配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分布式处理item 这个已经由 scrapy-redis 实现,不需要我们写代码,直接使用即可
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 100 ,
}
5(必须). 指定redis数据库的连接参数
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
scrapy-redis键名介绍
scrapy-redis中都是用key-value形式存储数据,其中有几个常见的key-value形式:
1、 “项目名:items” -->list 类型,保存爬虫获取到的数据item 内容是 json 字符串
2、 “项目名:dupefilter” -->set类型,用于爬虫访问的URL去重 内容是 40个字符的 url 的hash字符串
3、 “项目名: start_urls” -->List 类型,用于获取spider启动时爬取的第一个url
4、 “项目名:requests” -->zset类型,用于scheduler调度处理 requests 内容是 request 对象的序列化 字符串
scrapy-redis简单实例
在原来非分布式爬虫的基础上,使用scrapy-redis简单搭建一个分布式爬虫,过程只需要修改一下spider的继承类和配置文件即可,很简单。
原非分布式爬虫项目,参见:https://www.cnblogs.com/pythoner6833/p/9018782.html
首先修改配置文件,在settings.py文件中添加代码:
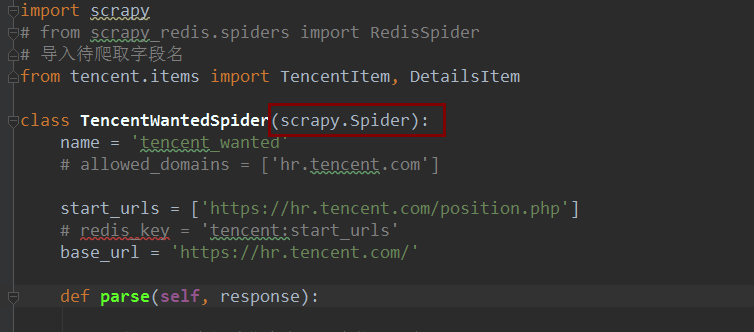
然后需要修改的文件,是spider文件,原文件代码为:
修改为:
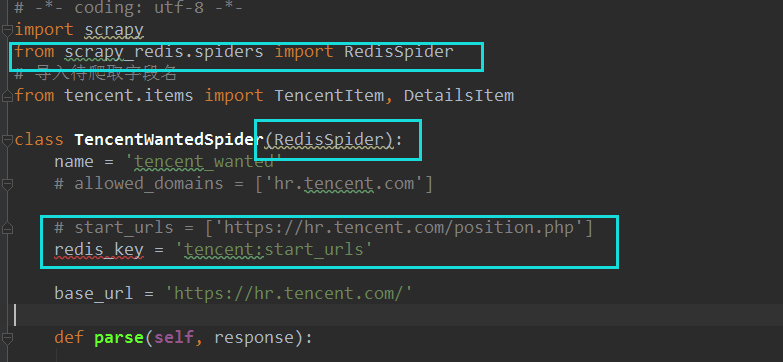
只修改了两个地方,一个是继承类:由scrapy.Spider修改为RedisSpider
然后start_url已经不需要了,修改为:redis_key = "xxxxx",其中,这个键的值暂时是自己取的名字,
一般用项目名:start_urls来代替初始爬取的url。由于分布式scrapy-redis中每个请求都是从redis中取出来的,因此,在redis数据库中,设置一个redis_key的值,作为初始的url,scrapy就会自动在redis中取出redis_key的值,作为初始url,实现自动爬取。
因此:来到redis中,添加代码:

即:在redis中设置一个键值对,键为tencent2:start_urls , 值为:初始化url。即可将传入的url作为初始爬取的url。
如此一来,分布式已经搭建完毕。
使用scrapy-redis搭建分布式爬虫环境的更多相关文章
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- Scrapy+redis实现分布式爬虫
概述 什么是分布式爬虫 需要搭建一个由n台电脑组成的机群,然后在每一台电脑中执行同一组程序,让其对同一网络资源进行联合且分布的数据爬取. 原生Scrapy无法实现分布式的原因 原生Scrapy中调度器 ...
- 使用scrapy-redis 搭建分布式爬虫环境
scrapy-redis 简介 scrapy-redis 是 scrapy 框架基于 redis 数据库的组件,用于 scraoy 项目的分布式开发和部署. 有如下特征: 分布式爬取: 你可以启动多个 ...
- 使用Docker Swarm搭建分布式爬虫集群
https://mp.weixin.qq.com/s?__biz=MzIxMjE5MTE1Nw==&mid=2653195618&idx=2&sn=b7e992da6bd1b2 ...
- scrapy——7 scrapy-redis分布式爬虫,用药助手实战,Boss直聘实战,阿布云代理设置
scrapy——7 什么是scrapy-redis 怎么安装scrapy-redis scrapy-redis常用配置文件 scrapy-redis键名介绍 实战-利用scrapy-redis分布式爬 ...
- 基于scrapy框架的分布式爬虫
分布式 概念:可以使用多台电脑组件一个分布式机群,让其执行同一组程序,对同一组网络资源进行联合爬取. 原生的scrapy是无法实现分布式 调度器无法被共享 管道无法被共享 基于 scrapy+redi ...
- scrapy如何实现分布式爬虫
使用scrapy爬虫的时候,记录一下如何分布式爬虫问题: 关键在于多台主机协作的关键:共享爬虫队列 主机:维护爬取队列从机:负责数据抓取,数据处理,数据存储 队列如何维护:Redis队列Redis 非 ...
- 阿里云Centos7.6上面部署基于redis的分布式爬虫scrapy-redis将任务队列push进redis
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的时候,单个服务器的处理能力就不能满足我们的需求了(无论是处理速度还是网络请 ...
- 在阿里云Centos7.6上面部署基于Redis的分布式爬虫Scrapy-Redis
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_83 Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的 ...
随机推荐
- 如何判断float值有效
// 一个浮点数是否有效,首先要看其是否是一个数字(_isnan为0),其次还要看其是否超出了表示范围(_finite为0) // 注意_finite是有限的意思 #include <float ...
- C#开发命令执行驱动程序 之 控制标志的命令行参数
/// <summary> /// 在cmd窗体内执行如下: /// CtrlOrderDrierApp.exe -f -t /// 返回: /// FOO /// Show Table ...
- 机器学习 AI 谷歌ML Kit 与苹果Core ML
概述 移动端所说的AI,通常是指"机器学习". 定义:机器学习其实就是研究计算机怎样模拟人类的学习行为,以获取新的知识或技能,并重新组织已有的知识结构使之不断改善自身.从实践的意义 ...
- SpringBoot自定义starter及自动配置
SpringBoot的核心就是自动配置,而支持自动配置的是一个个starter项目.除了官方已有的starter,用户自己也可以根据规则自定义自己的starter项目. 自定义starter条件 自动 ...
- 使用XPath
XPath----XML路径语言 XPath概览 XPath是一门在XML文档中查找信息的语言,它提供了非常简洁明了的路径选择表达式. XPath常用规则 表达式 描 述 nodename 选取此节 ...
- netcat的使用
1,端口扫描 端口扫描经常被系统管理员和黑客用来发现在一些机器上开放的端口,帮助他们识别系统中的漏洞. $nc -z -v -n 172.31.100.7 21-25 可以运行在TCP或者UDP模式, ...
- MVC5用户控件
1. 添加一个model,用于给用户控件传递数据: 2.添加一个部分视图 . 3. 部分视图中,引入model,用于传递数据 4. 在要插入用户控件的地方,这样写 @Html.Partial(&quo ...
- 使用ASP.NET Core 3.x 构建 RESTful API - 2. 什么是RESTful API
1. 使用ASP.NET Core 3.x 构建 RESTful API - 1.准备工作 什么是REST REST一词最早是在2000年,由Roy Fielding在他的博士论文<Archit ...
- [BZOJ] DZY Loves Math 系列 I && II
为了让自己看起来有点事干 ,做个套题吧..不然老是东翻翻西翻翻也不知道在干嘛... \(\bf 3309: DZY \ Loves \ Math\) 令 \(h=f*\mu\) 很明显题目要求的就是\ ...
- Java加密、解密Word文档
对一些重要文档,我们为保证其文档内容不被泄露,常需要对文件进行加密,查看文件时,需要正确输入密码才能打开文件.下面介绍了一种比较简单的方法给Word文件添加密码保护以及如何给已加密的Word文件取消密 ...