linux awk(gawk)
awk的前世今生:
awk名字的由来:分别取三个创始人Ah,Weiberger,Kernighan三个人的首字母。
awk是一个报告生成器可以格式化输出文本内容。模式扫描和处理语言(pattern scarming and processing language)
awk工作流程图
第一步:读取被匹配到的行数据。
第二步:按照输入分隔符将整行数据分成n段。
第三步:将每一段保存到awk的内置变量,依次为$1~$n。
第四部:格式化输出。全部输出使用$0。
对段的操作:
如:判断第二个字段是否>2
如:循环$1~$n,对其进行统一操作

awk 的用法:
- awk [POSIX or GNU style options ] -f program-file [-] file......
- awk [POSIX or GNU style options ] [-] program-text file....
上边的两个语法有点难看懂,我们可以这么用
awk [options] 'program' file
options:
-F:指定输入数据是的字段分割符。
-v:自定义变量;格式为 variable=value。
'program':awk的程序语句段
标准形式:'PATTERN {'ACTION STATEMENTS'}'
注意:program必须使用''引起来,以防止被shell解释
PATTERN为匹配模式。
ACTION STATEMENTS为操作语句。
注意:ACTION 是由系统的awk语句组成,各语句之间用;分隔。
ACTION STATEMENTS:
输出命令:print
print item1,item2,item3……
要点1:各item之间用逗号分隔,若不适用逗号则awk会默认连接两个item的内容。
首先取出文件中的后五行,然后使用awk取出其第二和第四个段(默认空格为分隔符)

$2和$4之间没有逗号,则默认拼接$2$4

要点2:print输出的item可以是数值,$n,变量,或awk表达式。
要想引用$n的值,不能把其放入“”内。
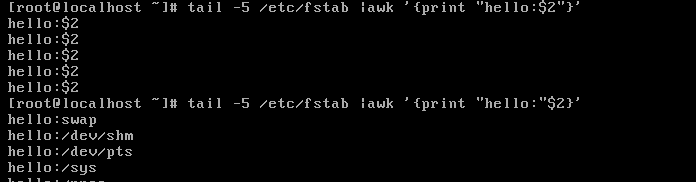
要点3:若省略item,则默认输出$0。

变量:分为内置变量和自定义变量
内置变量:
FS:input field seperator。输入字段分隔符
可以使用-v来指定分隔符,也可以直接使用-F直接指名。


OFS:outpu field seperator。输出字段分隔符
可以看到上图的输出内容,字段之间以空格分隔。使用OFS指定以:分隔。

RS:input record seperator 。输入时的换行符
ORS:output record seperator。输出时的换行符
NF:number of field。每一行的字段数量。
没有指定输入分隔符(FS),默认以空格来分隔。

指定以:为分隔符后 ,输出每一行字段数量。

$NF代表的是$7即最后一行。所以输出文件的每一行的最后一个字段。

NR:numbe of record 。显示文件的行数。每处理一行就会输出一次行数

合并多个文件的行数。

NFR单独计算每个文件的行数。

END只输出最后的行数

FILENAME:正在被awk编辑的文件名。
每处理一行数据都会打印一次文件名,test2文件有两行数据,所以输出两行。

ARGC:命令行参数个数 program不算参数。此处参数分别是 awk和两个文件

ARGV:是一个数组,保存了命令行参数。

ARGV[index]:取出ARGV中的参数从0开始。

自定义变量:-v variable=value或在program中直接定义。
注意:变量名区分大小写
下边是两种变量定义方法。


格式化输出命令:printf
语法:printf FORMAT, item1,item2,……
格式符:
%s:显示字符串
%c:显示字符对应的ASCII码
%d,%i:显示十进制整数
%e,%E:显示科学计数法数值
%f:显示浮点数
%g,%G:以科学计数法或者浮点形式显示数值
%u:显示无符号整数
%%:显示%
要点一:FORMAT必须给出
要点二:printf输出是不会自动换行,若需要换行可以使用换行控制符——\n
可以看到输出的是一堆连续的字符

手动控制换行

要点三:FORMAT中给出的格式符需要与item一一对应
要点四:在printf中可以加入提示性字符


修饰符:用来修饰格式符。
#[.#]:第一个#用来控制字符宽度,第二个用来控制小数位数。

-:左对齐。注意默认为右对齐。

+:显示数值的符号。
操作符:
算数运算:+ - * / % ^ -x +x
比较运算:> >= = < <= != ==
赋值运算:++,--,+=,-=,*=,%=
字符串操作:默认为字符串拼接
模式匹配:
~:是否匹配:左侧字符是否被右侧模式匹配
如果$NF的内容能匹配行末是bash ,这输出$1,$NF

!~:是否不匹配,:左侧字符是否不被右侧模式匹配
逻辑操作符:
&&:与
||:或
!:非
函数调用:function_name(argu1,argu2……)
条件表达式:selector?if_true_expression:if_false_expression
如果用户ID大于1000,则usertype=common user 否则等于sysadmin user .然后输出$1和usertype

PATTER:模式
empty:空模式(默认),此模式会匹配文件的每一行
/regular expression/:处理被pattern匹配的每一行
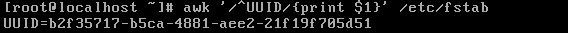
relational expression :关系表达式,如果是一个布尔值。若为真则会被处理,为假被过滤
真:非0只,非空字符
假:0,空字符
第三个字段值大于1000,输出$1,$3

如果最后一个字段为/bin/bash,则输出$1,$NF


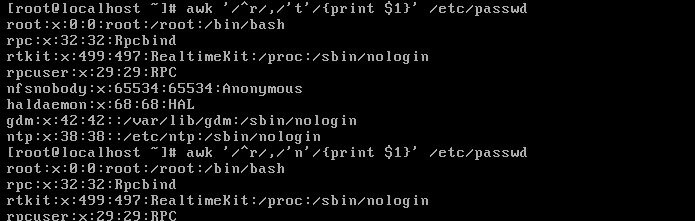
line ranges:行范围
/pattern1/,/pattern2/:处理 pattern1 到 pattern2 之间(不包含pattern2)。从pattern1匹配的行开始,到pattern2匹配的行结束。
匹配第一个以r开头的行到第一个以t开头的行。但是我们会发现并没有输出t开头的行,结合第二个命令的输出。
我们会发现匹配的范围为t开头的前一行
BEGIN和END模式:是给程序赋予初始状态和在程序结束之后执行一些扫尾的工作。
BEGIN{}:任何在BEGIN之后列出的操作(在{}内)将在awk开始扫描输入之前执行一次。
END{}:END之后列出的操作将在扫描完全部的输入之后执行一次。
第一步:利用BEGIN{}输出一个表头。

第二步:格式化输出内容

第三步:利用END{}输出表尾

awk的基本应用到此结束
linux awk(gawk)的更多相关文章
- awk(gawk)文本报告生成器
awk是gawk的链接文件,是一种优良的文本处理工具,实现格式化文本输出,是Linux和Unix现有环境中功能最强大的数据处理引擎之一.这种编程及数据操作语言的最大功能取决于一个人拥有的知识量,使用& ...
- Linux 基础(5)
Linux 基础 (五) 一.shell相关知识 shell一般代表两个层面的意思,一个是命令解释器,比如BASH,另外一个就是shell脚本.通过解释器的角度来理解shel 命令分为: ==> ...
- Java开发人员必须掌握的Linux命令(三)
做一个积极的人 编码.改bug.提升自己 我有一个乐园,面向编程,春暖花开! 学习应该是快乐的,在这个乐园中我努力让自己能用简洁易懂(搞笑有趣)的表达来讲解知识或者技术,让学习之旅充满乐趣,这就是写博 ...
- Linux学习(2)- 正则表达式基础
Linux学习(2)- 正则表达式基础 一.基础正则表达式介绍与练习 学习内容 正则表达式特殊符号 [:alnum:]代表英文大小写字母及数字 [:alpha:]代表英文大小写字母 [:blank:] ...
- Linux设备管理(四)_从sysfs回到ktype
sysfs是一个基于ramfs的文件系统,在2.6内核开始引入,用来导出内核对象(kernel object)的数据.属性到用户空间.与同样用于查看内核数据的proc不同,sysfs只关心具有层次结构 ...
- Linux设备管理(三)_总线设备的挂接
扒完了字符设备,我们来看看平台总线设备,平台总线是Linux中的一种虚拟总线,我们知道,总线+设备+驱动是Linux驱动模型的三大组件,设计这样的模型就是将驱动代码和设备信息相分离,对于稍微复杂一点的 ...
- Linux设备管理(二)_从cdev_add说起
我在Linux字符设备驱动框架一文中已经简单的介绍了字符设备驱动的基本的编程框架,这里我们来探讨一下Linux内核(以4.8.5内核为例)是怎么管理字符设备的,即当我们获得了设备号,分配了cdev结构 ...
- 每天一个 Linux 命令(21):find命令之xargs
在使用 find命令的-exec选项处理匹配到的文件时, find命令将所有匹配到的文件一起传递给exec执行.但有些系统对能够传递给exec的命令长度有限制,这样在find命令运行几分钟之后,就会出 ...
- 每天一个linux命令(46):vmstat命令
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存.进程.CPU活动进行监控.他是对系统的整体情况进行统计,不足之处是无法对某个进程进行深 ...
随机推荐
- JdbcTemplate增删改
(1)Accountsdao层 //删除单个账户 int delaccount(Integer accountid); //添加单个用户 int addaccount(Accounts account ...
- LeetCode刷题笔记(6)按照索引计算int[] 数组中的和([Time Limit Exceeded]问题)
Easy303 Easy633 package easy; public class e303 { private int[] sums; public e303(int[] nums) { sums ...
- SpringBoot与MybatisPlus整合之公用字段填充(十一)
在实际开发中,适合用于记录创建人修改人 pom.xml <dependencies> <dependency> <groupId>org.springframewo ...
- Spring Boot 2.X(十四):日志功能 Logback
Logback 简介 Logback 是由 SLF4J 作者开发的新一代日志框架,用于替代 log4j. 主要特点是效率更高,架构设计够通用,适用于不同的环境. Logback 分为三个模块:logb ...
- Pycharm 专业版激活码(转) 有效期到2020/06月
亲测有效!!! 有效期截止为2020年06月,多谢大家支持与讨论! K6IXATEF43-eyJsaWNlbnNlSWQiOiJLNklYQVRFRjQzIiwibGljZW5zZWVOYW1lIjo ...
- SAP SOAMANAGER报错原因与故障排除方法
一些刚刚接触到SAP Webservice的开发者由于对SAP Netweaver组件的不熟悉,往往在使用事物码SOAMANAGER进行webservice配置的时候,发现无法正常启动SOAMANAG ...
- 《Effective Java》 读书笔记(八)避免使用Finalizer和Cleaner机制
Finalizer和Cleaner并不等同于C++中的析构函数,是不确定多久会被调用的,甚至有时候可能不会被调用,因此除了作为一个安全网或者终止非关键的本地资源,不应该在Finalizer或Clean ...
- 学习笔记05一般处理程序ashx
1.获取由表单传过来的参数var value1 = HttpContext.Request["健"]; 2.使得网站目录下的相对路径转化为绝对路径:(用于文件操作)var file ...
- 读书笔记——《MySQL DBA 工作笔记》
关于前言 作者在前言中提出的一些观点很具有参考价值, 梳理完整的知识体系 这是每一个技术流都应该追逐的,完整的知识体系能够使我们对知识的掌握更加全面,而不仅仅局限于点 建立技术连接的思维,面对需求,永 ...
- Vue组件间通信方式到底有几种
1. 前言 Vue的一个核心思想就是组件化.所谓组件化,就是把页面拆分成多个组件 (component),每个组件依赖的 CSS.JavaScript.模板.图片等资源放在一起开发和维护.组件是资源独 ...