Deep attention tracking via Reciprocative Learning
文章:Deep attention tracking via Reciprocative Learning
出自NIPS2018
文章链接:https://arxiv.org/pdf/1810.03851.pdf
代码链接:https://github.com/shipubupt/NIPS2018

背景:
这篇论文是NIPS2018的一篇目标跟踪的论文,是由北京邮电大学,腾讯AI实验室和上海交通大学共同合作写的。现在目标跟踪使用的算法有两种:一种是使用单阶段回归框架,另外一种是使用两阶段分类框架,因为这篇论文使用的是两阶段框架,所以简单介绍一下这个框架。两阶段的框架又叫Tracking-by-detection framework:第一步在上一帧预测的位置周围上画出一些样本,第二步使用分类器识别这个样本是目标还是背景。现有的很多方法都是额外使用attention模块生成特征权重,即进行特征选择。即进行特征选择。但是这种方法学习的特征权重无法使分类器在较长时间跨度内关注鲁棒特征,也就是说当目标发生比较大的外观变化时,跟踪会发生漂移。
主要贡献:
这篇论文提出一种交互性学习算法,这个算法的亮点就是不使用额外的attention模块就可以得到这个attention map,并且直接将attention map作为正则化项和原来的分类损失一起训练,使分类器更加关注目标对象对外观变化鲁棒的区域
网络结构及损失函数:
Attention Exploitation
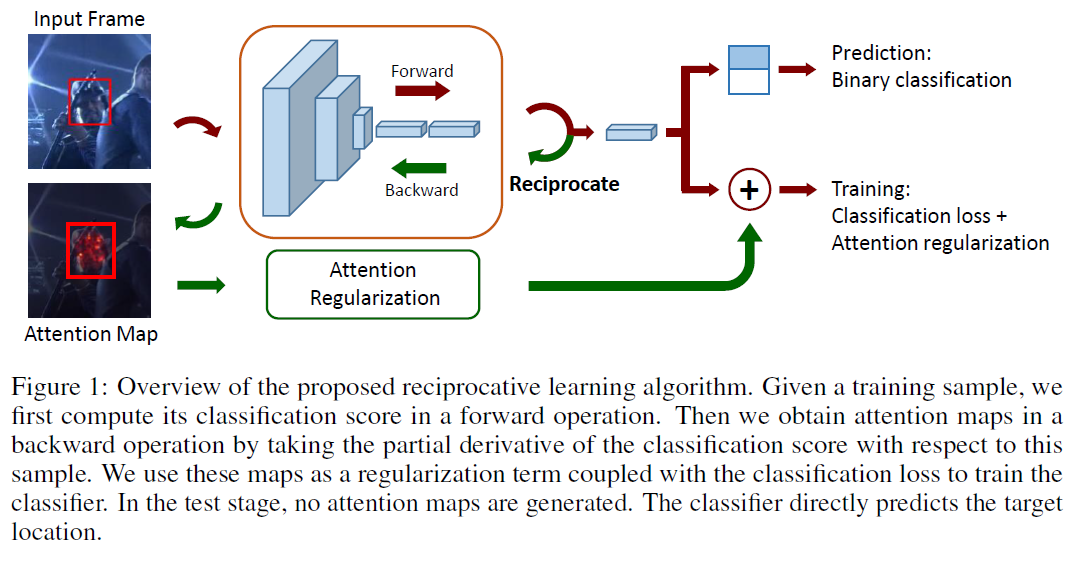
图1是整个网络结构。之前一些使用attention模型的网络,一般都是通过增加一个额外的模块来产生attention map,但是这篇文章是使用网络输入层的偏导作为attention map。


给定一个input sample I0,将网络从输入到输出分数看成一个函数fc(I),然后我们就可以使用一阶泰勒展开式进行展开,其中A是网络的一阶导数,B是余项,c是类别的意思,这个就是公式1的由来。
点z0(采集的样本)属于输入I0的epsilon领域,那么对于这个领域内的所有点公式(1)均成立。所以当这点z0和I0无限靠近时这两个的导数相等。公式1表明类别c的输出分数受Ac每个元素的影响。每个输入图片对应的Ac都是特殊的。
在后向传播中使用链式准则计算Ac。论文中只选择正值的作为梯度,因为他们对正值的类别分数有着明显的贡献。注意在后向传播中,网络参数是固定没有更新的。
Attention Regularization


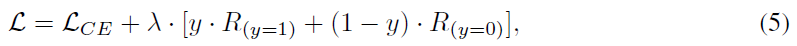
对于每一个输入I0,可以得到两个attention map,正样本的attention map Ap和负样本的attention map An。对于一个输入为正样本的I0,我们希望与目标相关的Ap的像素值尽量大,与目标相关的An像素尽量小。所以正样本的正则项如公式3所示。所以对于公式3,应该尽量增大第一项的均值,减小标准差,减小第二项的均值,增大标准差。同理对于公式4应该是Ap的像素值尽量小,An像素值尽量大。
Attention mp是如何减小损失。首先是公式3,通过增大第一项的均值,减小标准差从而减小第一项的值,为的就是增大像素的强度且这些值之间的差异小(标准差小),通过减小第二项的均值,增大标准差从而减小第二项的值,含义是第二项是正样本预测为背景的分数,减小像素的值
Reciprocative Learning
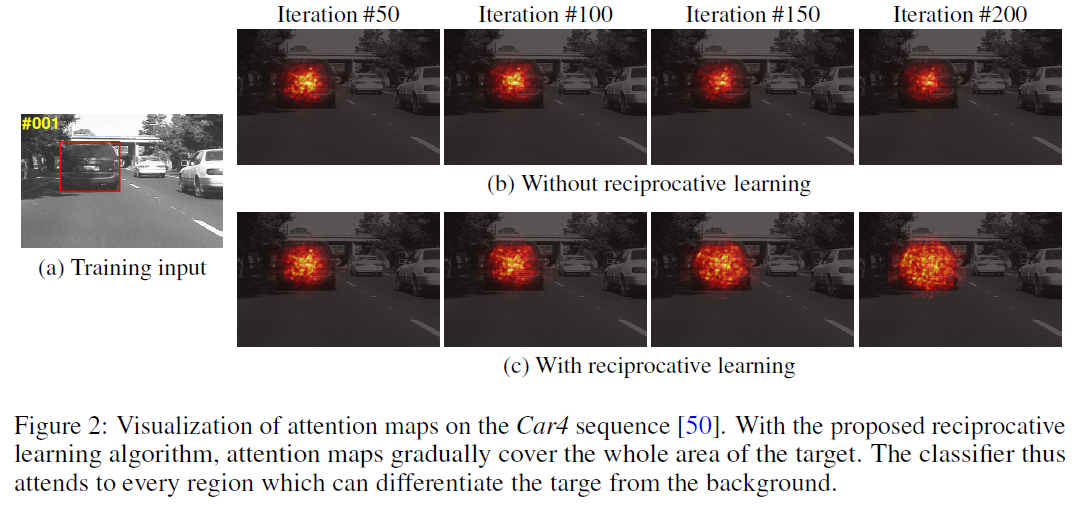
所谓的交互式学习就是使用标准的后向传播和链式准则,将正则化想结合到loss函数中,训练分类器选择性的关注目标区域,忽略背景区域
Tracking Process
模型初始化:第一帧,读入图片后训练模型前面三层卷积层,并固定前三层参数。在初始的目标区域周围随机生成N1个样本,这些样本根据和GT的IoU判断是正样本或者负样本。使用H1个迭代训练初始模型,对于每次迭代中的每个样本,使用公式5计算其损失,并相应地更新全连接层。
在线检测:给定上一帧的检测结果,我检测到的目标周围随机生成N2个样本,将这些样本送入网络,选择分数较高的propos,并对目标位置进行微调
模型更新:在线检测后若检测到的目标与上一帧目标Iou在规定范围内则检测成功,根据这一帧图片的更新模型的前三层特征。若不成功,则使用上一帧目标位置进行训练,迭代H2次更新模型的全连接层。

实验结果
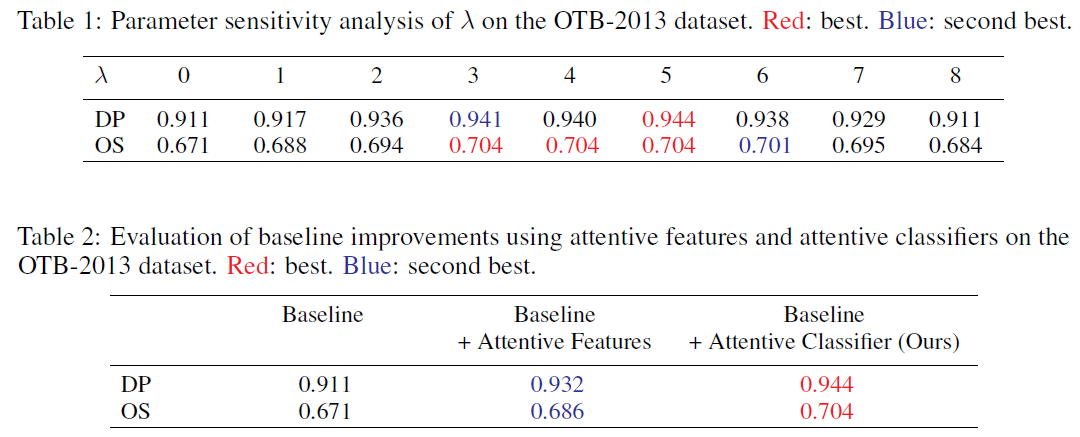


在overlap success rate方面,我们的跟踪器不如性能最好的跟踪器CCOT。这是因为我们的跟踪器随机抽取稀疏样本集进行尺度估计。但是CCOT在一个连续的空间中对样本进行收割
CCOT:传统的DCF模型(如SRDCF)采用handcrafted或CNN等特征,但这些特征都是单一分辨率的,即每个通道的特征图的分辨率都是相同的。为了能够将多种分辨率的特征(例如,卷积网络不同层的特征图,层数越深,特征图越小)整合在一起,C-COT提出将卷积过程转换到一个连续域。这个连续域指的是自变量t在[0,T)范围内。
Evaluation metrics
评估的具体讲解: https://blog.csdn.net/Dr_destiny/article/details/80108255
CLE(center location error):GT与估计中心位置的平均欧几里德距离
DP(distance precision):CLE(中心位置误差)小于特定阈值的帧数/所有帧
OS(overlap success):IoU大于阈值的帧数/所有帧
EAO(expected average overlap):(平均重叠期望是对每个跟踪器在一个短时图像序列上的非重置重叠(no-reset average overlap)的期望值) 把视频序列按照不同的长度分组,把相同长度的求平均准确度(只跑一次),然后把所有不同长度序列的准确率再统一求均值
Ar(accuracy rank):准确率(Accuracy)是指跟踪器在单个测试序列下的平均重叠率,将tracker在不同属性序列上的表现按照accuracy分别排名,再进行平均
Rr(robustness rank):鲁棒性(Robustness)是指单个测试序列下的跟踪器失败次数,当重叠率为0时即可判定为失败。将tracker在不同属性序列上的表现按照Robustnessy分别排名,再进行平均
Deep attention tracking via Reciprocative Learning的更多相关文章
- 论文阅读:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning 2018-11-14 13:30:36 Paper: https://arxiv.org/abs/ ...
- 论文笔记:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning NIPS18_tracking Type:Tracking-By-Detection 本篇论文地主 ...
- 论文笔记之:Deep Attention Recurrent Q-Network
Deep Attention Recurrent Q-Network 5vision groups 摘要:本文将 DQN 引入了 Attention 机制,使得学习更具有方向性和指导性.(前段时间做 ...
- Summary on Visual Tracking: Paper List, Benchmarks and Top Groups
Summary on Visual Tracking: Paper List, Benchmarks and Top Groups 2018-07-26 10:32:15 This blog is c ...
- (zhuan) Where can I start with Deep Learning?
Where can I start with Deep Learning? By Rotek Song, Deep Reinforcement Learning/Robotics/Computer V ...
- Use of Deep Learning in Modern Recommendation System: A Summary of Recent Works(笔记)
注意:论文中,很多的地方出现baseline,可以理解为参照物的意思,但是在论文中,我们还是直接将它称之为基线,也 就是对照物,参照物. 这片论文中,作者没有去做实际的实验,但是却做了一件很有意义的事 ...
- What are some good books/papers for learning deep learning?
What's the most effective way to get started with deep learning? 29 Answers Yoshua Bengio, ...
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
深度强化学习的18个关键问题 from: https://zhuanlan.zhihu.com/p/32153603 85 人赞了该文章 深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破? 这两 ...
- 深度学习阅读列表 Deep Learning Reading List
Reading List List of reading lists and survey papers: Books Deep Learning, Yoshua Bengio, Ian Goodfe ...
随机推荐
- Java初学者的学习路线推荐
Java学习这一部分其实也算是今天的重点,这一部分用来回答很多群里的朋友所问过的问题,那就是你是如何学习Java的,能不能给点建议?今天我是打算来点干货,因此咱们就不说一些学习方法和技巧了,直接来谈每 ...
- (day31) Event+协程+进程/线程池
目录 昨日回顾 GIL全局解释器锁 计算密集型和IO密集型 死锁现象 递归锁 信号量 线程队列 FOFI队列 LIFO队列 优先级队列 今日内容 Event事件 线程池与进程池 异步提交和回调函数 协 ...
- 函数基础(一)(day10整理)
目录 昨日内容 文件的基本应用 什么是文件 操作文件的流程 打开文件的三种模式 文件打开的两种方式 绝对路径和相对路径 绝对路径 相对路径 with管理文件上下文 文件的高级应用 新的打开文件的模式 ...
- 数据结构(四十)平衡二叉树(AVL树)
一.平衡二叉树的定义 平衡二叉树(Self-Balancing Binary Search Tree或Height-Balanced Binary Search Tree),是一种二叉排序树,其中每一 ...
- django-模板之静态文件加载(十四)
1.在templates同级目录下建static 2.index.css 3.index.html {% load static %} <!DOCTYPE html> <html l ...
- java script三大组成部分
JavaScript是一种属于网络的脚本语言,已经被广泛用于Web应用开发,常用来为网页添加各式各样的动态功能,为用户提供更流畅美观的浏览效果.通常JavaScript脚本是通过嵌入在HTML中来实现 ...
- PHP输出A到Z及相关
先看以下一段PHP的代码,想下输出结果是什么. <?php for($i='A'; $i<='Z'; $i++) { echo $i . '<br>'; } ?> 输出的 ...
- Codeforces 1178G. The Awesomest Vertex
传送门 首先通过dfs序把子树操作转化为区间操作,求最大值可以用斜率优化. 然后分个块,对每个块维护个凸包.修改时中间的打个标记,边角暴力重构:询问时中间的用斜率优化的方法求,边角的暴力求. 由于此题 ...
- 零基础Linux入门学习方法--如何做好笔记及长效知识复习记忆
“工欲善其事必先利其器”. 此次学习的0基础教材为刘遄(Liu Chuán)老师的<Linux就该这么学>.学习目的是通过RHCE认证.有关RHCE认证介绍会在认识Linux及红帽认证中记 ...
- Servlet相关学习
Servlet入门解析 概念 运行在服务器端的小程序 servlet就是一个接口,定义了Java类被浏览器访问到(tomcat识别)的规则 实现servlet接口.复写方法 快速入门 创建web项目 ...