偏差和方差以及偏差方差权衡(Bias Variance Trade off)
当我们在机器学习领域进行模型训练时,出现的误差是如何分类的?
我们首先来看一下,什么叫偏差(Bias),什么叫方差(Variance):
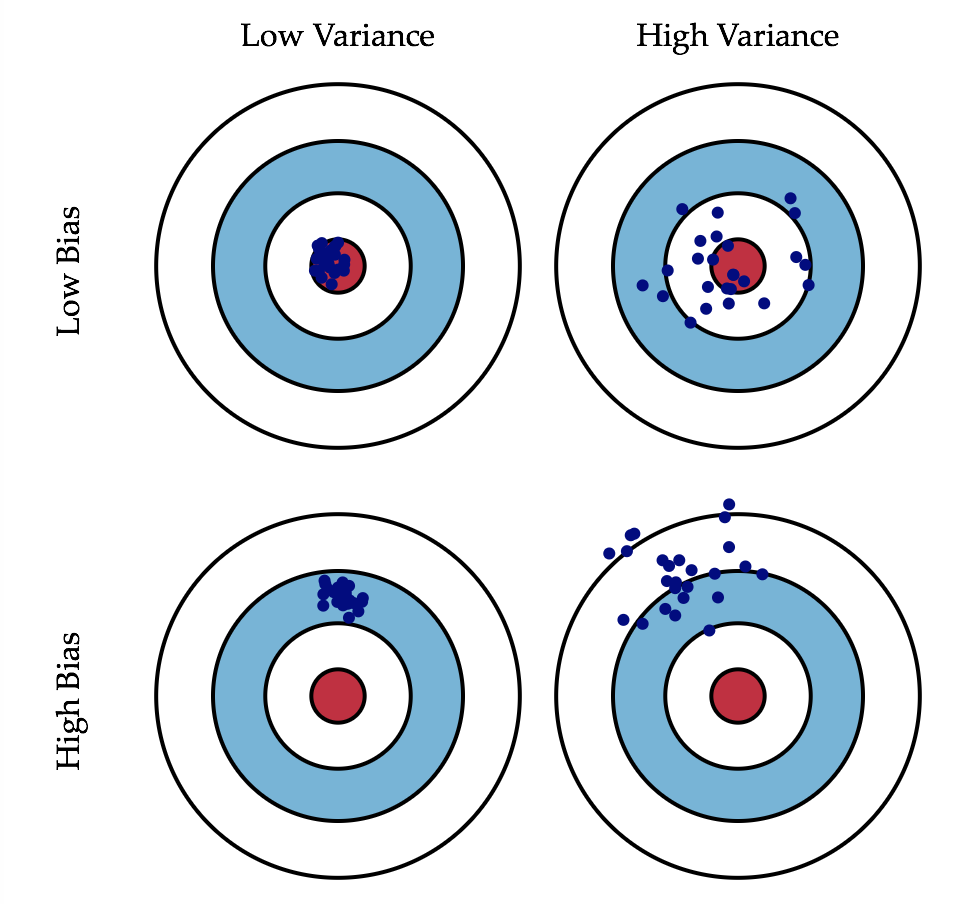
这是一张常见的靶心图
可以看左下角的这一张图,如果我们的目标是打靶子的话,我们所有的点全都完全的偏离了这个中心的位置,那么这种情况就叫做偏差
再看右上角这张图片,我么们的目标是右上角这张图片中心的红色位置,我们射击的点都围绕在这个红色的点的周围,没有大的偏差,但是各个点间过于分散不集中,就是有非常高的方差
模型误差 = 偏差(Bias) + 方差(Variance) + 不可避免的误差
不可避免的误差: 客观存在的误差,例如采集的数据的噪音等,是我们无法避免的
- 有一些算法天生是高方差的算法。如kNN,决策树等
- 非参数学习通常都是高方差算法。因为不对数据进行任何假设
- 有一些算法天生是高偏差算法。如线性回归
- 参数学习通常都是高偏差算法。因为堆数据具有极强的假设
大多数算法具有相应的参数,可以调整偏差和方差, 比如kNN中的k和线性回归中使用多项式回归。
偏差和方差通常是矛盾的,我们要在两者之间找到一个平衡
在机器学习领域,主要的挑战来自方差,当然主要是在算法方面,实际问题中原因不尽相同
解决高方差的通常手段:
1.降低模型复杂度
2.减少数据维度;降噪
3.增加样本数
4.使用验证集
5.模型正则化
偏差和方差以及偏差方差权衡(Bias Variance Trade off)的更多相关文章
- 【笔记】偏差方差权衡 Bias Variance Trade off
偏差方差权衡 Bias Variance Trade off 什么叫偏差,什么叫方差 根据下图来说 偏差可以看作为左下角的图片,意思就是目标为红点,但是没有一个命中,所有的点都偏离了 方差可以看作为右 ...
- 机器学习:偏差方差权衡(Bias Variance Trade off)
一.什么是偏差和方差 偏差(Bias):结果偏离目标位置: 方差(Variance):数据的分布状态,数据分布越集中方差越低,越分散方差越高: 在机器学习中,实际要训练模型用来解决一个问题,问题本身可 ...
- [转]理解 Bias 与 Variance 之间的权衡----------bias variance tradeoff
有监督学习中,预测误差的来源主要有两部分,分别为 bias 与 variance,模型的性能取决于 bias 与 variance 的 tradeoff ,理解 bias 与 variance 有助于 ...
- 斯坦福大学公开课机器学习: advice for applying machine learning | regularization and bais/variance(机器学习中方差和偏差如何相互影响、以及和算法的正则化之间的相互关系)
算法正则化可以有效地防止过拟合, 但正则化跟算法的偏差和方差又有什么关系呢?下面主要讨论一下方差和偏差两者之间是如何相互影响的.以及和算法的正则化之间的相互关系 假如我们要对高阶的多项式进行拟合,为了 ...
- Error=Bias+Variance
首先 Error = Bias + Variance Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输 ...
- Bias, Variance and the Trade-off
偏差,方差以及两者权衡 偏差是由模型简化的假设,使目标函数更容易学习. 一般来说,参数化算法有很高的偏差,使它们学习起来更快,更容易理解,但通常不那么灵活.反过来,它们在复杂问题上的预测性能更低,无法 ...
- 机器学习总结-bias–variance tradeoff
bias–variance tradeoff 通过机器学习,我们可以从历史数据学到一个\(f\),使得对新的数据\(x\),可以利用学到的\(f\)得到输出值\(f(x)\).设我们不知道的真实的\( ...
- 2.9 Model Selection and the Bias–Variance Tradeoff
结论 模型复杂度↑Bias↓Variance↓ 例子 $y_i=f(x_i)+\epsilon_i,E(\epsilon_i)=0,Var(\epsilon_i)=\sigma^2$ 使用knn做预测 ...
- 训练/验证/测试集设置;偏差/方差;high bias/variance;正则化;为什么正则化可以减小过拟合
1. 训练.验证.测试集 对于一个需要解决的问题的样本数据,在建立模型的过程中,我们会将问题的data划分为以下几个部分: 训练集(train set):用训练集对算法或模型进行训练过程: 验证集(d ...
随机推荐
- 齐治运维堡垒机后台存在命令执行漏洞(CNVD-2019-17294)分析
基本信息 引用:https://www.cnvd.org.cn/flaw/show/CNVD-2019-17294 补丁信息:该漏洞的修复补丁已于2019年6月25日发布.如果客户尚未修复该补丁,可联 ...
- 《ElasticSearch6.x实战教程》正式推出(附图书抽奖)
经过接近1个月的时间,ElasticSearch6.x实战教程终于成册.这本实战教程小册有很多不足(甚至可能有错误),也是第一次完整推出一个系列的教程. 1年前,我开始真正接触ES,在此之前仅停留在知 ...
- spark 源码分析之十六 -- Spark内存存储剖析
上篇spark 源码分析之十五 -- Spark内存管理剖析 讲解了Spark的内存管理机制,主要是MemoryManager的内容.跟Spark的内存管理机制最密切相关的就是内存存储,本篇文章主要介 ...
- RabbitMQ(一):RabbitMQ快速入门
RabbitMQ是目前非常热门的一款消息中间件,不管是互联网大厂还是中小企业都在大量使用.作为一名合格的开发者,有必要对RabbitMQ有所了解,本文是RabbitMQ快速入门文章. RabbitMQ ...
- 小白开学Asp.Net Core《三》
小白开学Asp.Net Core<三> ——界面 我胡汉三再次又回来了(距离上篇时间有点长),今天抽时间将最近对框架采用的后台界面做个记录 1.先上图 (图一) (图二) 2.界面说明 后 ...
- 【Java中级】(三)IO
1. 流分为字节流和字符流 2. 字节流下面常用的又有数据流和对象流 3. 字符流下面常用的又有缓存流 文件对象 文件和文件夹都用File表示 //file path : 文件的绝对路径或相对路径Fi ...
- Linux系统安装jdk——rpm版
这里简单地阐述一下rpm.deb.tar.gz的区别. rpm格式的软件包适用于基于Red Hat发行版的系统,如Red Hat Linux.SUSE.Fedora. deb格式的软件包则是适用于基于 ...
- VMWare虚拟机:三台虚拟机互通且连网
虚拟机:三台虚拟机互通且连网 目录 一.虚拟机 相关软件 虚拟机安装 Linux系统安装 1) 使用三个Linux虚拟机 多台虚拟机互通且上网 1) 多台配置注意事项 2) 虚拟机软件的配置 3) W ...
- spring使用thymeleaf
一.spring使用thymeleaf做解析器其实很简单,这是基于xml配置的方式 <?xml version="1.0" encoding="UTF-8" ...
- win10虚拟机搭建Hadoop集群(已完结)
1 在虚拟机安装 Ubuntu 2 安装网络工具 Ubuntu最小化安装没有 ifconfig命令 sudo apt-get install net-tools 3 Ubuntu修改网卡名字 修改网卡 ...