laravel开发大型电商网站之异常设计思路分析
令人讨厌的异常
提起异常,大家都很反感,当信心满满的写完一段代码,刷新页面发现上面写着大大的 Exception 是最心烦的时候了。模块给领导演示的时候,如果报了异常,也是最让人崩溃的时候了。
在一般的大型网站中,如果拥有异常处理的机制,那么将会帮助我们节省很多不需要的工作,具体如下:
什么是异常
异常是运行中超出了你程序预期的一个东西。
场景
例如京东有个 轻松购 的功能,当点击的时候会将该商品自动添加到购物车并生成订单,然后进行支付,这是一个网络请求,但是在后端实际执行了一系列的事情(以下操作是简单举例子便于说明问题,和真实步骤有差异)
- 验证用户是否登录
- 验证用户状态(如果被拉入系统黑名单就不能登录)
- 查看订单中物品是否实时有货
- 锁定货物(库存减少,支付中的货物数量 + 1)
- 生成订单
问题
步骤很多,如果任何一个环节出现问题,就要做响应的处理
- 用户没有登录就要保存购买信息,并跳转到登录页面
- 用户状态有问题则直接提示禁止继续购买
- 如果没有货物则跳转商品页面
- 同时购买人太多,自己购买时无货
处理思路
- 写到一个
controller里面,顺序执行,哪一步出错直接return? 这个controller该有多长,代码完全不可读,这是典型面向过程了。 - 封装几个业务方法返回
truefalse判断?比第一个好,但是就像编辑器多了折叠功能,其实还是面向过程的思路。
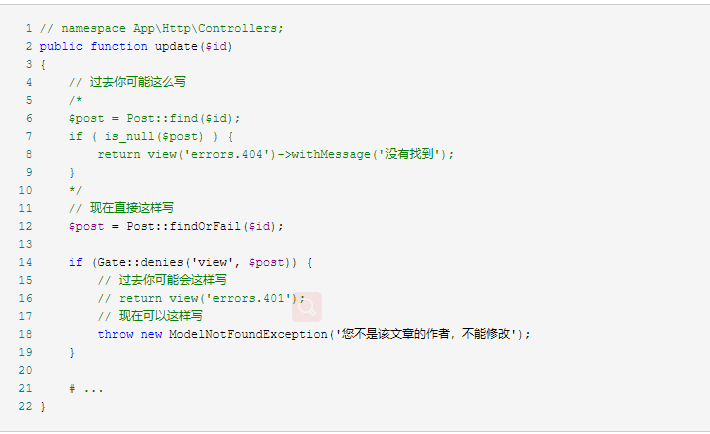
其实我们可以定义一个 购买流程的类 和一些异常了。下面是每个步骤的分析
- 需要在中间件验证用户是否登录,直接跳转。
- 可以写个中间件,命名为
BlacklistMiddleware专门处理黑名单,也是直接跳转到禁止界面。 - 此时其实已经到我们的业务处理类里面了,如果无货,你还会写跳转到无货页面吗?显然这里不合适了,因为你不知道什么时候需求变更(可以继续购买,只不过等待到货而已),如果真的跟需求变更来回改核心代码,累死也写不完程序了。建一个
NoGoodsException异常,当你业务处理类发现没有货,直接抛出该异常。然后在控制器中try catch捕获该异常进行后续处理,或者使用App\Exceptions\Handler进行统一处理。 - 如果你定义了上面的异常,那么你就尽情的抛出异常吧,已经有异常程序帮你处理后面的事情。
这样的好处就是,你的逻辑完全分离,不要再在业务逻辑代码里面考虑如何返回什么页面,要跳转到哪里,只考虑抛出合适的异常即可,简单的可以直接在 App\Exceptions\Handler 定义通用的捕获异常处理方式,这样的表现就非常统一了。如果需求高了,可以 try catch 后再根据情况再抛更详细的异常。
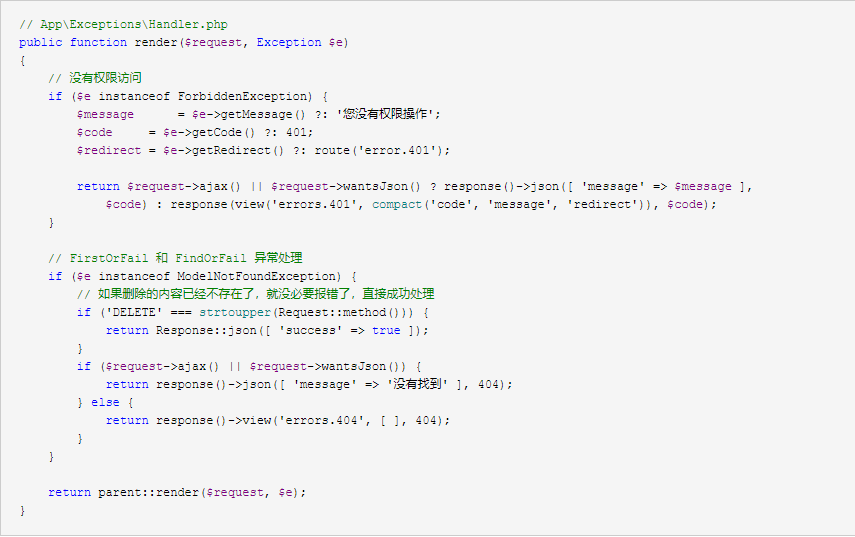
记录异常
对于某些异常,我们可能需要记录下来,以便方便发现问题,在 App\Exceptions\Handler 我们可以不去记录一些异常

最后针对不同的异常错误,可以做到相关信息记录,而我们只需要根据对应的分类找到对应的类库就可以
如果有实现疑问或者需要代码笔记,可以加入qq群交流与获取源码笔记:647617935
laravel开发大型电商网站之异常设计思路分析的更多相关文章
- [刘阳Java]_大型电商网站架构技术演化历程
今年的双十一已经过去一段,作为技术小咖啡,我们先说一下大型电商网站的特点:高并发,大流量,高可用,海量数据.下面就说说大型网站的架构演化过程,它的技术架构是如何一步步的演化的 1. 早期的网站架构 初 ...
- 小白学 Python 爬虫(29):Selenium 获取某大型电商网站商品信息
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫:Selenium 获取某大型电商网站商品信息
目标 先介绍下我们本篇文章的目标,如图: 本篇文章计划获取商品的一些基本信息,如名称.商店.价格.是否自营.图片路径等等. 准备 首先要确认自己本地已经安装好了 Selenium 包括 Chrome ...
- PHP大型电商网站秒杀思路
秒杀/抢购 技术:高可用,高并发 市场:用户体验,曝光度,促销 秒杀放单独服务器,这样即使崩溃不影响网站其他功能. 高可用:双活. 高并发:负载均衡,安全过滤. 阿里云:云监控 分流,CDN加速 业务 ...
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- 吴裕雄--天生自然PYTHON爬虫:爬取某一大型电商网站的商品数据(效率优化以及代码容错处理)
这篇博文主要是对我的这篇https://www.cnblogs.com/tszr/p/12198054.html爬虫效率的优化,目的是为了提高爬虫效率. 可以根据出发地同时调用多个CPU,每个CPU运 ...
- Spark大型电商项目实战-及其改良(3) 分析sparkSQL语句的性能影响
之前的运行数据被清除了,只能再运行一次,对比一下sparkSQL语句的影响 纯SQL的时间 对应时间表 th:first-child,.table-bordered tbody:first-child ...
- MVC 6 电商网站开发实战
[原创] ASP.NET 5系列教程 (六): 在 MVC6 中创建 Web API 标签: Web API MVC6 创建web API | 博主:powertoolsteam ASP.NE ...
- PHP实现日志处理类库 - 【微信开发之微电商网站】技术笔记之二
继上篇文章[微信开发之微电商网站]技术笔记之一,昨日做了日志处理的功能. 对于现在的应用程序来说,日志的重要性是不言而喻的.很难想象没有任何日志记录功能的应用程序运行在生产环境中.日志所能提供的功能是 ...
随机推荐
- react-native StatusBar透明
目录 一 react-native 自定义AppStatusBar 二 配置 android 一 react-native 自定义AppStatusBar 透明 StatusBar字体黑色, 否则是白 ...
- THML第一天学习!
又迎来了新一轮的周末,学习的耗时光呀!这周呢学了一点点数据库,暂时还不想写下自己的感受(这学期在 学习数据库,等学期末的时候在总结一下数据库的相关学习). 目前呢,我是打算跟着sunck学习观pyth ...
- leaflet图斑历史时空播放(附源码下载)
前言 leaflet 入门开发系列环境知识点了解: leaflet api文档介绍,详细介绍 leaflet 每个类的函数以及属性等等 leaflet 在线例子 leaflet 插件,leaflet ...
- vuex简单使用。
项目结构: 1:首先在项目中新建store.js文件,.js文件内容如下: import Vue from 'vue' import Vuex from 'vuex' Vue.use(Vuex) ex ...
- CodeForces-Round524 A~D
A. Petya and Origami time limit per test 1 second memory limit per test 256 megabytes input stan ...
- 矩阵解压,网络流UESTC-1962天才钱vs学霸周2
天才钱vs学霸周2 Time Limit: 500 MS Memory Limit: 128 MB Submit Status 由于上次的游戏中学霸周输了,因此学霸周想出个问题为难天才钱,问题 ...
- MySQL面试总结
MySQL面试总结 # MySQL的存储引擎 `MyISAM`(默认表类型):非事务的存储引擎,基于传统的`ISAM`(有索引的顺序访问方法)类型,是存储记录和文件的标准方法,不是事务安全,不支持外键 ...
- ARTS-S EN0001-In tech race with China, US universities may lose a vital edge
原文 The U.S. is still out in front of global rivals when it comes to innovation, but American univers ...
- ARTS-S ansible-playbook
文件a.yml --- - hosts: cluster remote_user: ksotest gather_facts: false tasks: - name: delete dir if e ...
- Java实现数列的排列组合
定义: 排列:从给定个数的元素中取出指定个数的元素,进行排序 组合:从给定个数的元素中仅取出指定个数的元素,不考虑排序 公式: 从n个元素中取出m个元素进行排序的个数: A(m,n)=n(n-1)(n ...