图解I/O的五种模型
1.1 五种I/O模型
1)阻塞I/O
2)非阻塞I/O
3)I/O复用
4)事件(信号)驱动I/O
5)异步I/O
1.2 为什么要发起系统调用?
因为进程想要获取磁盘中的数据,而能和磁盘打交道的只能是内核, 进程通知内核,说要磁盘中的数据
此过程就是系统调用
1.3 一次I/O完成的步骤
当进程发起系统调用时候,这个系统调用就进入内核模式, 然后开始I/O操作
I/O操作分为俩个步骤:
1) 磁盘把数据装载进内核的内存空间
2) 内核的内存空间的数据copy到用户的内存空间中(此过程才是真正I/O发生的地方)
注意: io调用大多数都是阻塞的
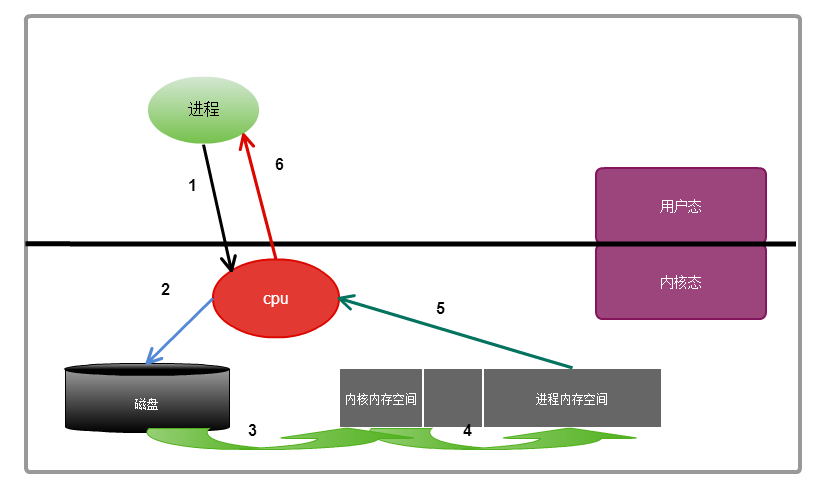
过程分析
整个过程:此进程需要对磁盘中的数据进行操作,则会向内核发起一个系统调用,然后此进程,将会被切换出去,
此进程会被挂起或者进入睡眠状态,也叫不可中 断的睡眠,因为数据还没有得到,只有等到系统调用的结果完成后,
则进程会被唤醒,继续接下来的操作,从系统调用的开始到系统调用结束经过的步骤:
①进程向内核发起一个系统调用,
②内核接收到系统调用,知道是对文件的请求,于是告诉磁盘,把文件读取出来
③磁盘接收到来着内核的命令后,把文件载入到内核的内存空间里面
④内核的内存空间接收到数据之后,把数据copy到用户进程的内存空间(此过程是I/O发生的地方)
⑤进程内存空间得到数据后,给内核发送通知
⑥内核把接收到的通知回复给进程,此过程为唤醒进程,然后进程得到数据,进行下一步操作
2.1 阻塞
是指调用结果返回之前,当前线程会被挂起(线程进入睡眠状态) 函数只有在得到结果之后,才会返回,才能继续执行
阻塞I/O系统怎么通知进程?
I/O 完成后, 系统直接通知进程, 则进程被唤醒
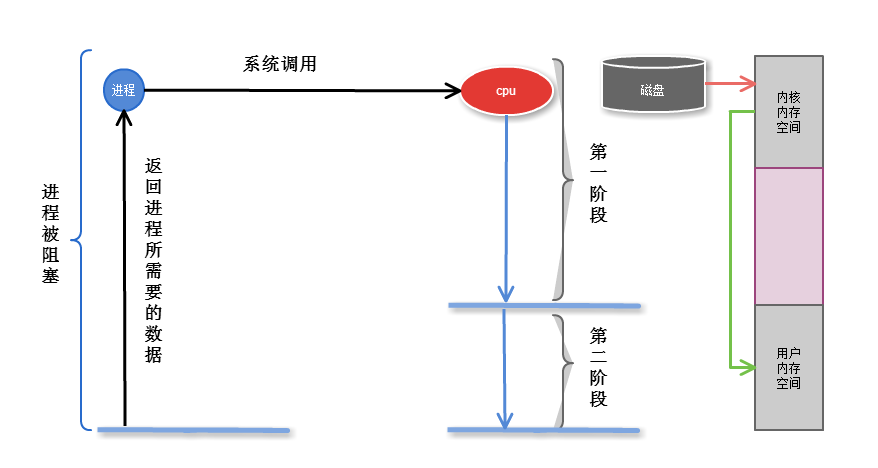
第一阶段是指磁盘把数据装载到内核的内存中空间中
第二阶段是指内核的内存空间的数据copy到用户的内存空间 (这个才是真实I/O操作)
2.2 非阻塞
非阻塞:进程发起I/O调用,I/O自己知道需过一段时间完成,就立即通知进程进行别的操作,则为非阻塞I/O
非阻塞I/O,系统怎么通知进程?
每隔一段时间,问内核数据是否准备完成,系统完成后,则进程获取数据,继续执行(此过程也称盲等待)
缺点: 无法处理多个I/O,比如用户打开文件,ctrl+C想终止这个操作,是无法停掉的
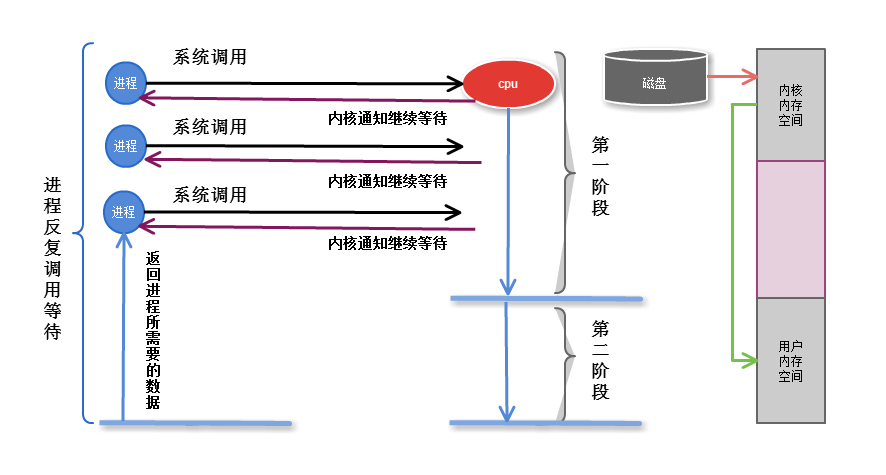
第一阶段是指磁盘把数据装载到内核的内存中空间中
第二阶段是指内核的内存空间的数据copy到用户的内存空间 (这个才是真实I/O操作)
2.3 I/O多路复用 select
为什么要用I/O多路复用
某个进程阻塞多个io上 ,一个进程即要等待从键盘输入信息, 另一个准备从硬盘装入信息
比如通过read这样的命令, 调用了来个io操作,一个io完成了,一个io没有完成, 阻塞着键盘io,磁盘io完成了 ,
这个进程也是不能响应, 因为键盘io还没有完成,还在阻塞着 , 这个进程还在睡眠状态 ,这个时候怎么办 ?
由此需要I/O多路复用。
执行过程
以后进程在调用io的时候, 不是直接调用io的功能,在系统内核中, 新增了一个系统调用, 帮助进程监控多个io,
一旦一个进程需要系统调用的时候, 向内核的一个特殊的系统调用,发起申请时,这个进程会被阻塞在这个复用器的调用上,
所以复用这个功能会监控这些io操作,任何一个io完成了,它都会告诉进程,其中某个io完成,如果进程依赖某个io操作,
那么这个时候,进程就可以继续后面的操作. 能够帮组进程监控这些io的工具叫做io复用器
Linux中 I/O 复用器
select: 就是一种实现,进程需要调用的时候,把请求发送给select ,可以发起多个,但是最多只能支持1024个,先天性的限制
poll: 没有限制,但是多余1024个性能会下降
所以早期的apache 本身prefork mpm模型,主进程在接受多个用户请求的时候,在线请求数超过1024个,就不工作了.
那么io复用会比前俩种好吗?
本来进程和系统内核直接沟通的 ,在中间加一个i/o复用select, 如果是传话,找人传话,那么这个传话最后会是什么样的呢?
虽然解决了多个系统调用的问题,多路io复用本身的后半段依然是阻塞的,阻塞在select 上, 而不是阻塞在系统调用上,
但是他第二段仍然是阻塞的,由于要扫描所有多个io操作, 多了一个处理机制,性能未必上升, 性能上也许不会有太大的改观
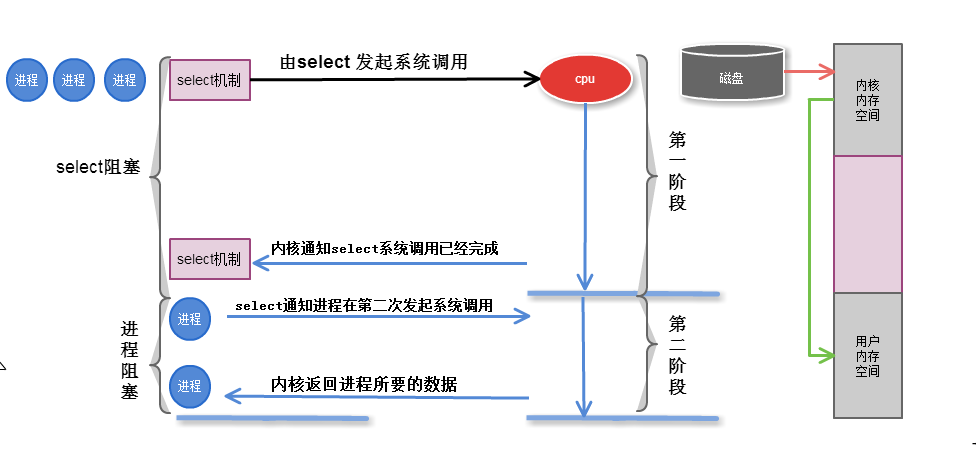
第一阶段是指磁盘把数据装载到内核的内存中空间中
第二阶段是指内核的内存空间的数据copy到用户的内存空间 (这个才是真实I/O操作)
2.4 事件驱动
进程发起调用,通过回调函数, 内核会记住是那个进程申请的,一旦第一段完成了,就可以向这个进程发起通知,
这样第一段就是非阻塞的,进程不需要盲等了, 但是第二段依然是阻塞的
事件驱动机制(event-driven)
正是由于事件驱动机制 ,才能同时相应多个请求的
比如: 一个web服务器. 一个进程响应多个用户请求
缺陷: 第二段仍然是阻塞的
俩种机制
如果一个事件通知一个进程,进程正在忙, 进程没有听见, 这个怎么办?
水平触发机制: 内核通知进程来读取数据,进程没来读取数据,内核需要一次一次的通知进程
边缘触发机制: 内核只通知一次让进程来取数据,进程在超时时间内,随时可以来取数据, 把这个事件信息状态发给进程,好比发个短息给进程,
nginx
nginx默认采用了边缘触发驱动机制
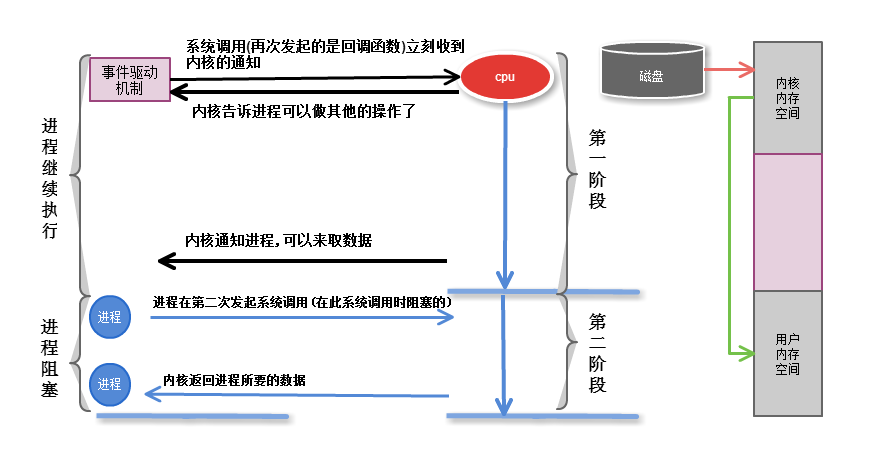
第一阶段是指磁盘把数据装载到内核的内存中空间中
第二阶段是指内核的内存空间的数据copy到用户的内存空间 (这个才是真实I/O操作)
2.5 异步AIO
无论第一第二段, 不再向系统调用提出任何反馈, 只有数据完全复制到服务进程内存中后, 才向服务进程返回ok的信息,其它时间,
进程可以随意做自己的事情,直到内核通知ok信息
注意: 只在文件中可以实现AIO, 网络异步IO 不可能实现
nginx:
nginxfile IO 文件异步请求的
一个进程响应N个请求
静态文件界别: 支持sendfile
避免浪费复制时间: mmap 支持内存映射,内核内存复制到进程内存这个过程, 不需要复制了, 直接映射到进程内存中
支持边缘触发
支持异步io
解决了c10k的问题
c10k : 有一万个同时的并发连接
c100k: 你懂得
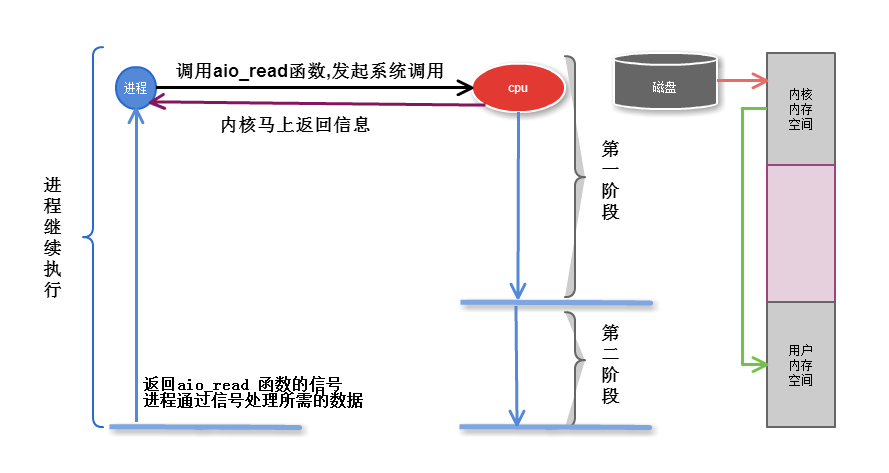
第一阶段是指磁盘把数据装载到内核的内存中空间中
第二阶段是指内核的内存空间的数据copy到用户的内存空间 (这个才是真实I/O操作)
前四种I/O模型属于同步操作,最后一个AIO则属于异步操作
2.6 五种模型比较
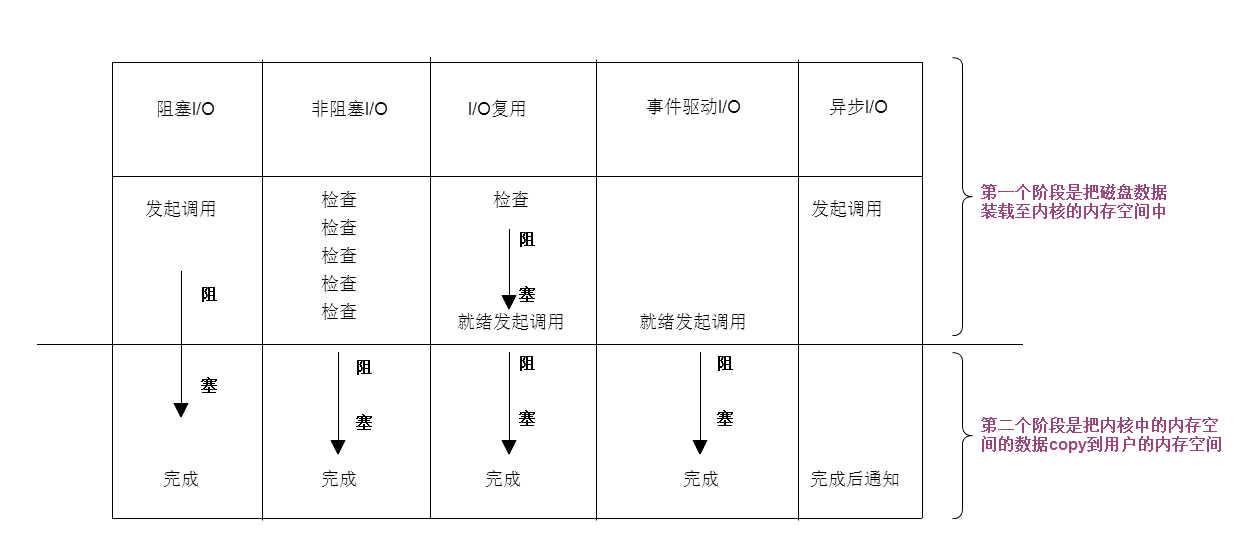

同步阻塞
俩段都是阻塞的,所有数据准备完成后,才响应
同步非阻塞
磁盘从磁盘复制到内核内存中的时候, 不停询问内核数据是否准备完成. 盲等
性能有可能更差 ,看上去他可以做别的事情了, 但是其实他在不停的循环.
但还是有一定的灵活性的
缺点: 无法处理多个I/O,比如用户打开文件,ctrl+C想终止这个操作,是无法停掉的
同步IO
如果第二段是阻塞的 ,代表是同步的
第一种,第二种,io复用,事件驱动,都是同步的.
异步IO
内核后台自己处理 ,把大量时间拿来处理用户请求
图解I/O的五种模型的更多相关文章
- IO的五种模型
为了区分IO的五种模型,下面先来看看同步与异步.阻塞与非阻塞的概念差别. 同步:所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回.按照这个定义,其实绝大多数函数都是同步调用(例如 ...
- 2. 彤哥说netty系列之IO的五种模型
你好,我是彤哥,本篇是netty系列的第二篇. 欢迎来我的公从号彤哥读源码系统地学习源码&架构的知识. 简介 本文将介绍linux中的五种IO模型,同时也会介绍阻塞/非阻塞与同步/异步的区别. ...
- IO 的五种模型是什么
目录 前言 用户空间和内核空间 IO 五种模型 阻塞型 IO 非阻塞 IO IO 多路复用 信号驱动 IO 异步 IO 总结 阻塞和非阻塞 同步与异步 前言 我们经常看到阻塞/非阻塞,同步/异步这两组 ...
- 【网络IO系列】IO的五种模型,BIO、NIO、AIO、IO多路复用、 信号驱动IO
前言 在上一篇文章中,我们了解了操作系统中内核程序和用户程序之间的区别和联系,还提到了内核空间和用户空间,当我们需要读取一条数据的时候,首先需要发请求告诉内核,我需要什么数据,等内核准备好数据之后 , ...
- socket编程五种模型
客户端:创建套接字,连接服务器,然后不停的发送和接收数据. 比较容易想到的一种服务器模型就是采用一个主线程,负责监听客户端的连接请求,当接收到某个客户端的连接请求后,创建一个专门用于和该客户端通信的套 ...
- Linux-I/O五种模型
一. 概念说明 在进行解释之前,首先要说明几个概念: 用户空间和内核空间 进程切换 进程的阻塞 文件描述符 缓存 I/O 同步(Sync)/异步(Async) 阻塞(Block)/非阻塞(Unbloc ...
- linux第7天 I/O的五种模型, select
服务器端避免僵尸进程的方法: 1)通过忽略SIGCHLD信号,解决僵尸进程 signal(SIGCHLD, SIG_IGN) 2)通过wait方法,解决僵尸进程 signal(SIGCHLD, han ...
- Linux IO的五种模型 ongoing
服务器端编程经常需要构造高性能的IO模型,常见的IO模型: 阻塞I/O模型 (Blocking IO) ------------(同步)(阻塞) 非阻塞I/O模型 (Non-Blocking IO) ...
- 浅谈Linux下的五种I/O模型
一.关于I/O模型的引出 我们都知道,为了OS的安全性等的考虑,进程是无法直接操作I/O设备的,其必须通过系统调用请求内核来协助完成I/O动作,而内核会为每个I/O设备维护一个buffer.如下图所 ...
随机推荐
- Hibernate java.lang.NoSuchFieldError: INSTANCE
在使用hibernate3.6.2是我遇到了一个有趣的错误java.lang.NoSuchFieldError: INSTANCEat org.hibernate.type.BasicTypeRegi ...
- 免安装oracle驱动访问数据库
try { string connStr = "Data Source=(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=192.168.110.110)( ...
- 【转】Mac QQ截图保存在哪里?
原文网址:http://www.pc6.com/edu/67677.html QQ Mac版的截屏图片保存在哪儿呢?可不可以像Windows版本一样设定保存路径呢?当然是可定的.Mac QQ截图保存你 ...
- 延期(deferred)的承诺(promise) — jq异步编程浅析
引子 相信各位developers对js中的异步概念不会陌生,异步操作后的逻辑由回调函数来执行,回调函数(callback function)顾名思义就是“回头调用的函数”,函数体事先已定义好,在未来 ...
- 万科北京区域V-learn发布 系V-LINK产品系中首批产品
继今年4月发布了V-LINK万科社区服务商2.0升级版本后,万科北京区域再次迎来了品牌大动作.近日,北京万科正式发布“V-LINK”产品系中的首批产品“V-learn”相关战略. 全品类教育模式 据介 ...
- [liu yanling]软件测试的过程
测试过程按4个步骤进行,即单元测试.组装测试.确认测试和系统测试.
- 【原】Comparator和Comparable的联系与区别
1.知识点了解 Comparator和Comparable都是用用来实现集合中元素的比较.排序的,所以,经常在集合外定义Comparator接口的方法和集合内实现Comparable接口的方法中实现排 ...
- oracle之spool详细使用总结
今天实际项目中用到了spool,发现网上好多内容不是很全,自己摸索了好半天,现在总结一下. 一.通过spool 命令,可以将select 数据库的内容写到文件中,通过在sqlplus设置一些参数,使得 ...
- TCA9546A
The TCA9546A is a 4-channel, bidirectional translating switch for I 2 C buses that supports Standard ...
- linux 密码安全脚本
#!/bin/bash #by:osx1260@.com DIESO=/etc/pam.d PAMSO=$(ls $DIESO/* |awk -F'/' '{print $4}') NEPAMUN=' ...