伪共享FalseShare
伪共享FalseShare
什么是共享
下图是计算的基本结构。L1、L2、L3分别表示一级缓存、二级缓存、三级缓存,越靠近CPU的缓存,速度越快,容量也越小。所以L1缓存很小但很快,并且紧靠着在使用它的CPU内核;L2大一些,也慢一些,并且仍然只能被一个单独的CPU核使用;L3更大、更慢,并且被单个插槽上的所有CPU核共享;最后是主存,由全部插槽上的所有CPU核共享。
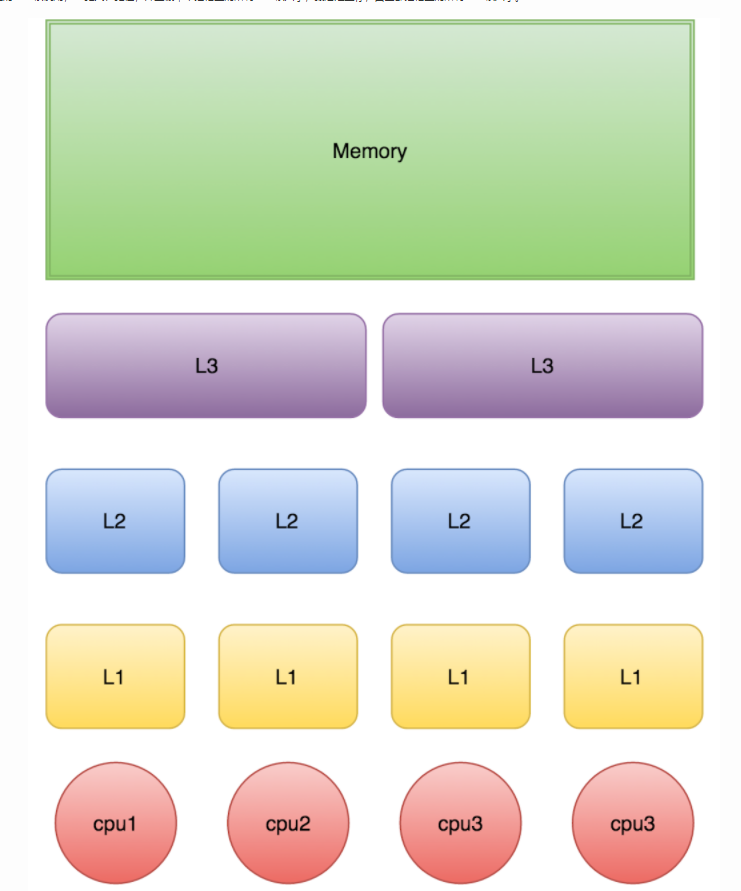
当CPU执行运算的时候,它先去L1查找所需的数据、再去L2、然后是L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要尽量确保数据在L1缓存中。
另外,线程之间共享一份数据的时候,需要一个线程把数据写回主存,而另一个线程访问主存中相应的数据。
下面是从CPU访问不同层级数据的时间概念:

可见CPU读取主存中的数据会比从L1中读取慢了近2个数量级。
缓存行
Cache是由很多个cache line组成的。在程序运行的过程中,缓存每次更新都从主内存中加载连续的64个字节。因此,如果访问一个long类型的数组时,当数组中的一个值被加载到缓存中时,另外7个元素也会被加载到缓存中。但是,如果使用的数据结构中的项在内存中不是彼此相邻的,比如链表,那么将得不到免费缓存加载带来的好处。不过,这种免费加载也有一个坏处。设想如果我们有个long类型的变量a,它不是数组的一部分,而是一个单独的变量,并且还有另外一个long类型的变量b紧挨着它,那么当加载a的时候将免费加载b。看起来似乎没有什么问题,但是如果一个cpu核心的线程在对a进行修改,另一个cpu核心的线程却在对b进行读取。当前者修改a时,会把a和b同时加载到前者核心的缓存行中,更新完a后其它所有包含a的缓存行都将失效,因为其它缓存中的a不是最新值了。而当后者读取b时,发现这个缓存行已经失效了,需要从主内存中重新加载。缓存都是以缓存行作为一个单位来处理的,所以失效a的缓存的同时,也会把b失效,反之亦然。
下面的例子是测试利用cache line的特性和不利用cache line的特性的效果对比。输出结果为:
Loop times:11ms
Loop times:46ms
public class Test {
static long[][] arr;
public static void main(String[] args) {
arr = new long[1024 * 1024][];
for (int i = 0; i < 1024 * 1024; i++) {
arr[i] = new long[8];
for (int j = 0; j < 8; j++) {
arr[i][j] = 0L;
}
}
long sum = 0L;
long marked = System.currentTimeMillis();
for (int i = 0; i < 1024 * 1024; i+=1) {
for(int j =0; j< 8;j++){
sum = arr[i][j];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
marked = System.currentTimeMillis();
for (int i = 0; i < 8; i+=1) {
for(int j =0; j< 1024 * 1024;j++){
sum = arr[j][i];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
}
}
如何避免伪共享
以以下代码为例:
不做处理的情况:用时2519ms
public class FalseSharingTest {
public static void main(String[] args) throws InterruptedException {
testPointer(new Pointer());
}
private static void testPointer(Pointer pointer) throws InterruptedException {
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
pointer.x++;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(System.currentTimeMillis() - start);
System.out.println(pointer);
}
}
class Pointer {
volatile long x;
volatile long y;
}
1)让不同线程操作的对象处于不同的缓存行
可以进行缓存行填充(Padding) 。例如,如果一条缓存行有 64 字节,而 Java 程序的对象头固定占 8 字节(32位系统)或 12 字节( 64 位系统默认开启压缩, 不开压缩为 16 字节),所以我们只需要填 6 个无用的长整型补上6*8=48字节,让不同的 VolatileLong 对象处于不同的缓存行,就避免了伪共享( 64 位系统超过缓存行的 64 字节也无所谓,只要保证不同线程不操作同一缓存行就可以)。
用时599ms
class Pointer {
volatile long x;
long p1, p2, p3, p4, p5, p6, p7;
volatile long y;
}
2)使用@sun.misc.Contended注解(java8)
@sun.misc.Contended 是 Java 8 新增的一个注解,对某字段加上该注解则表示该字段会单独占用一个缓存行(Cache Line)。
这里的缓存行是指 CPU 缓存(L1、L2、L3)的存储单元,常见的缓存行大小为 64 字节。
(注:JVM 添加 -XX:-RestrictContended 参数后 @sun.misc.Contended 注解才有效)
用时613ms,这种方式不加-XX:-RestrictContended也可以使用,没有搞明白为什么。
@sun.misc.Contended
class Pointer {
volatile long x;
volatile long y;
}
或者:(用时613ms)
class Pointer {
@sun.misc.Contended
volatile long x;
@sun.misc.Contended
volatile long y;
}
伪共享并不是一定要解决
解决伪共享主要适用于频繁写的共享数据上。如果不是频繁写的数据,那么 CPU 缓存行被锁的几率就不多,所以没必要使用了,否则不仅占空间还会浪费 CPU 访问操作数据的时间。
伪共享FalseShare的更多相关文章
- 伪共享(false sharing),并发编程无声的性能杀手
在并发编程过程中,我们大部分的焦点都放在如何控制共享变量的访问控制上(代码层面),但是很少人会关注系统硬件及 JVM 底层相关的影响因素.前段时间学习了一个牛X的高性能异步处理框架 Disruptor ...
- 多线程中的volatile和伪共享
伪共享 false sharing,顾名思义,“伪共享”就是“其实不是共享”.那什么是“共享”?多CPU同时访问同一块内存区域就是“共享”,就会产生冲突,需要控制协议来协调访问.会引起“共享”的最 ...
- Java8的伪共享和缓存行填充--@Contended注释
在我的前一篇文章<伪共享和缓存行填充,从Java 6, Java 7 到Java 8>中, 我们演示了在Java 8中,可以采用@Contended在类级别上的注释,来进行缓存行填充.这样 ...
- 伪共享和缓存行填充,从Java 6, Java 7 到Java 8
关于伪共享的文章已经很多了,对于多线程编程来说,特别是多线程处理列表和数组的时候,要非常注意伪共享的问题.否则不仅无法发挥多线程的优势,还可能比单线程性能还差.随着JAVA版本的更新,再各个版本上减少 ...
- java 伪共享
MESI协议及RFO请求典型的CPU微架构有3级缓存, 每个核都有自己私有的L1, L2缓存. 那么多线程编程时, 另外一个核的线程想要访问当前核内L1, L2 缓存行的数据, 该怎么办呢?有人说可以 ...
- java中伪共享问题
伪共享(False Sharing) 原文地址:http://ifeve.com/false-sharing/ 作者:Martin Thompson 译者:丁一 缓存系统中是以缓存行(cache l ...
- 并发性能的隐形杀手之伪共享(false sharing)
在并发编程过程中,我们大部分的焦点都放在如何控制共享变量的访问控制上(代码层面),但是很少人会关注系统硬件及 JVM 底层相关的影响因素.前段时间学习了一个牛X的高性能异步处理框架 Disruptor ...
- 关于java中的伪共享的认识和解决
在并发编程过程中,我们大部分的焦点都放在如何控制共享变量的访问控制上(代码层面),但是很少人会关注系统硬件及 JVM 底层相关的影响因素: CPU缓存 网页浏览器为了加快速度,会在本机存缓存以前浏览过 ...
- 线程基础:多任务处理——MESI协议以及带来的问题:伪共享
1.概述 本文和后续文章将着眼CPU的工作原理阐述伪共享的解决方法和volatile关键字的应用. 2.复习CPU工作原理2.1.CPU工作原理要清楚理解本文后续内容,就需要首先重新概述一下JVM的内 ...
- Java 中的伪共享详解及解决方案
1. 什么是伪共享 CPU 缓存系统中是以缓存行(cache line)为单位存储的.目前主流的 CPU Cache 的 Cache Line 大小都是 64 Bytes.在多线程情况下,如果需要修改 ...
随机推荐
- mac ping IP+端口的方法
nc -vz -w 2 192.168.1.104 3306
- mac brew 安装
Homebrew国内源 知乎文章地址:https://zhuanlan.zhihu.com/p/111014448 苹果电脑安装脚本: /bin/zsh -c "$(curl -fsSL h ...
- 在 Go 中恰到好处的内存对齐
问题 type Part1 struct { a bool b int32 c int8 d int64 e byte } 在开始之前,希望你计算一下 Part1 共占用的大小是多少呢? func m ...
- 如何设置家用威联通 NAS UPS 断电后自动关机并通知其他设备?
场景 备注: 求轻喷, 求放过. 我真的是个理线方面的白痴. 这已经是我的极限了. 我的家庭实验室 Homelab 服务器集群配置如下. 上半部分之前已经介绍过了, 这里就不再赘述了. 今天重点介绍介 ...
- 可视化|MapBoxGL
注册Proton Mail 用户名 密码 人机验证 昵称 设置恢复方法-选择稍后再说-确定 注册MapBoxGL 填写后 Finish creating your account 一开始之前记得选择U ...
- 【Python】使用PyInstaller把代码打包成exe可执行文件
使用PyInstaller打包自己写好的代码 零.需求 最近接到一个小单,需要批量修改文档内容,用Python做好后要打包成exe程序给客户的Win7电脑使用,此时需要用到PyInstaller打包自 ...
- arthas安装和简单使用
介绍 Arthas 是一款线上监控诊断产品,通过全局视角实时查看应用 load.内存.gc.线程的状态信息,并能在不修改应用代码的情况下,对业务问题进行诊断,包括查看方法调用的出入参.异常,监测方法执 ...
- 使用Python对理想气体进行建模
引言 在日常生活中,我们常常听到"气体",但你是否知道气体的行为是如何被科学家们用数学模型描述的呢?今天,我们就来聊聊如何用 Python 对理想气体进行建模,帮助大家更好地理解气 ...
- 关于:win远程桌面连接命令怎么用
远程桌面连接命令怎么用? 事实上,远程桌面连接命令很简单,一个mstsc命令就搞定: 也可以直接使用第三方远程桌面管理软件,比如 IIS7远程桌面管理 这些,但是想要真正连接上远程桌面是有前提的,下面 ...
- Kali安装JDK8以及JDK11、JDK17切换
声明:本文分享的安全工具和项目均来源于网络,仅供安全研究与学习之用, 如用于其他用途,由使用者承担全部法律及连带责任,与工具作者和本公众号无关. 瓜神学习网络安全 公众号 背景 很久之前更新了一次ka ...