ElasticSearch高可用部署
简单说明
我们在部署ElasticSearch高可用集群时,要规划好集群的规模,每个节点的职责,规划好后续的水平扩展方案,再进行部署。
核心概念
- Cluster:集群,由一个或多个 Elasticsearch 节点组成。
- Node:节点,组成 Elasticsearch 集群的服务单元,同一个集群内节点的名字不能重复。通常在一个节点上分配一个或者多个分片。
- Shards:分片,当索引上的数据量太大的时候,我们通常会将一个索引上的数据进行水平拆分,拆分出来的每个数据库叫作一个分片。
在一个多分片的索引中写入数据时,通过路由来确定具体写入那一个分片中,所以在创建索引时需要指定分片的数量,并且分片的数量一旦确定就不能更改。
分片后的索引带来了规模上(数据水平切分)和性能上(并行执行)的提升。每个分片都是 Luence 中的一个索引文件,每个分片必须有一个主分片和零到多个副本分片。 - Replicas:备份也叫作副本,是指对主分片的备份。主分片和备份分片都可以对外提供查询服务,写操作时先在主分片上完成,然后分发到备份上。
当主分片不可用时,会在备份的分片中选举出一个作为主分片,所以备份不仅可以提升系统的高可用性能,还可以提升搜索时的并发性能。但是若副本太多的话,在写操作时会增加数据同步的负担。 - Index:索引,由一个和多个分片组成,通过索引的名字在集群内进行唯一标识。
- Type:类别,指索引内部的逻辑分区,通过 Type 的名字在索引内进行唯一标识。在查询时如果没有该值,则表示在整个索引中查询。
- Document:文档,索引中的每一条数据叫作一个文档,类似于关系型数据库中的一条数据通过 _id 在 Type 内进行唯一标识。
- Settings:对集群中索引的定义,比如一个索引默认的分片数、副本数等信息。
- Mapping:类似于关系型数据库中的表结构信息,用于定义索引中字段(Field)的存储类型、分词方式、是否存储等信息。Elasticsearch 中的 Mapping 是可以动态识别的。
如果没有特殊需求,则不需要手动创建 Mapping,因为 Elasticsearch 会自动根据数据格式识别它的类型,但是当需要对某些字段添加特殊属性(比如:定义使用其他分词器、是否分词、是否存储等)时,就需要手动设置 Mapping 了。一个索引的 Mapping 一旦创建,若已经存储了数据,就不可修改了。 - Analyzer:字段的分词方式的定义。一个 Analyzer 通常由一个 Tokenizer、零到多个 Filter 组成。
比如默认的标准 Analyzer 包含一个标准的 Tokenizer 和三个 Filter:Standard Token Filter、Lower Case Token Filter、Stop Token Filter。
集群节点
下面简单介绍下部署高可用的ES集群时,各个节点的职责:
master节点
也叫主节点,主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等工作。Elasticsearch 中的主节点的工作量相对较轻。
data节点
数据节点,负责数据的存储和相关具体操作,比如索引数据的创建、修改、删除、搜索、聚合。所以数据节点对机器配置要求比较高,首先需要有足够的磁盘空间来存储数据,其次数据操作对系统 CPU、Memory 和 I/O 的性能消耗都很大。
通常随着集群的扩大,需要增加更多的数据节点来提高可用性。通过在配置文件中设置 node.data=true 来设置该节点成为数据节点。
协调节点
协调节点,是一种角色,而不是真实的 Elasticsearch 的节点,我们没有办法通过配置项来配置哪个节点为协调节点。集群中的任何节点都可以充当协调节点的角色。
当一个节点 A 收到用户的查询请求后,会把查询语句分发到其他的节点,然后合并各个节点返回的查询结果,最好返回一个完整的数据集给用户。
在这个过程中,节点 A 扮演的就是协调节点的角色。由此可见,协调节点会对 CPU、Memory 和 I/O 要求比较高
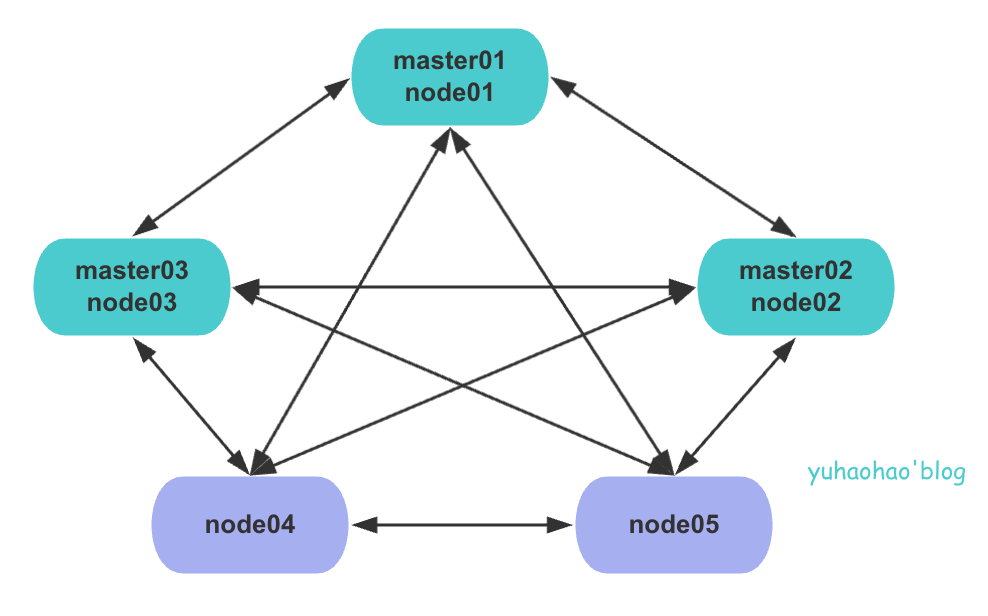
部署架构
这里,我们部署5节点集群时,规划部署架构图可以如下所示,协调节点可以配置为2个即可:
root@test:~# kubectl get pod -n es-test
NAME READY STATUS RESTARTS AGE
elasticsearch-test-coordinating-only-0 1/1 Running 0 47h
elasticsearch-test-coordinating-only-1 1/1 Running 0 47h
elasticsearch-test-data-0 1/1 Running 0 47h
elasticsearch-test-data-1 1/1 Running 0 47h
elasticsearch-test-data-2 1/1 Running 0 47h
elasticsearch-test-data-3 1/1 Running 0 47h
elasticsearch-test-data-4 1/1 Running 0 47h
elasticsearch-test-kibana-659847d54d-tk2n7 1/1 Running 0 47h
elasticsearch-test-master-0 1/1 Running 0 47h
elasticsearch-test-master-1 1/1 Running 0 47h
elasticsearch-test-master-2 1/1 Running 0 47h
elasticsearch-test-metrics-5b7cb7b9cf-7vd68 1/1 Running 0 47h
ElasticSearch高可用部署的更多相关文章
- kubernetes1.7.6 ha高可用部署
写在前面: 1. 该文章部署方式为二进制部署. 2. 版本信息 k8s 1.7.6,etcd 3.2.9 3. 高可用部分 etcd做高可用集群.kube-apiserver 为无状态服务使用hap ...
- NoSQL数据库Mongodb副本集架构(Replica Set)高可用部署
NoSQL数据库Mongodb副本集架构(Replica Set)高可用部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. MongoDB 是一个基于分布式文件存储的数据库.由 C ...
- LVS+Keepalived高可用部署
一.LVS+Keepalived高可用部署 一.keepalived节点部署 1.安装keepalived yum install keepalived ipvsadm -y mkdir -p /op ...
- Rancher Server HA的高可用部署实验-学习笔记
转载于https://blog.csdn.net/csdn_duomaomao/article/details/78771731 Rancher Server HA的高可用部署实验-学习笔记 一.机器 ...
- eql高可用部署方案
运行环境 服务器两台(后面的所有配置案例都是以10.96.0.64和10.96.0.66为例) 操作系统CentOS release 6.2 必须要有共同的局域网网段 两台服务器都要安装keepali ...
- MooseFS及其高可用部署
MooseFS的工作原理分析 MooseFS(下面统一称为MFS)由波兰公司Gemius SA于2008年5月30日正式推出的一款Linux下的开源存储系统,是OpenStack开源云计算项目的子项目 ...
- Redis高可用部署及监控
Redis高可用部署及监控 目录 一.Redis Sentinel简介 二.硬件需求 三.拓扑结构 .单M-S结构 .双M-S结构 .优劣对比 四.配置部 ...
- 006.SQLServer AlwaysOn可用性组高可用部署
一 数据库镜像部署准备 1.1 数据库镜像支持 有关对 SQL Server 2012 中的数据库镜像的支持的信息,请参考:https://docs.microsoft.com/zh-cn/previ ...
- kubernetes 1.15.1 高可用部署 -- 从零开始
这是一本书!!! 一本写我在容器生态圈的所学!!! 重点先知: 1. centos 7.6安装优化 2. k8s 1.15.1 高可用部署 3. 网络插件calico 4. dashboard 插件 ...
- Centos7.2 下DNS+NamedManager高可用部署方案完整记录
Centos7.2 下DNS+NamedManager高可用部署方案完整记录 之前说到了NamedManager单机版的配置,下面说下DNS+NamedManager双机高可用的配置方案: 1)机器环 ...
随机推荐
- idea src/main/webapp无法识别为web文件夹
整理项目的时候发现,在项目是src/main/webapp没有被自动识别为web文件夹. 1.确认你的项目已经转换为maven项目了. 2.确认你的项目的pom.xml文件有配置(只有配置了包类型,才 ...
- stat() "/root/xxx/index.html" failed (13: Permission denied)
前言 在 nginx 上部署静态网页报502,于是查看 nginx 错误日志 error_log /var/log/nginx/error.log;,却没有看到任何错误信息:访问 nginx活动日志 ...
- GBJ 97-1987 水泥混凝土路面施工及验收规范(电子版)PDF 版本 下载
本规范适用于新建和改建的公路 城市道路 厂矿道路和民航机场道面等就地浇筑的水泥混凝土路面的施工及验收 链接:https://pan.baidu.com/s/17t88jnEU6IrptmEWsyuN3 ...
- jupyter -- 数据分析可视化开发工具
博客地址:https://www.cnblogs.com/zylyehuo/ jupyter介绍 jupyter就是anaconda提供的一个基于浏览器的可视化开发工具 jupyter的基本使用 启动 ...
- 选择排序(LOW)
博客地址:https://www.cnblogs.com/zylyehuo/ # _*_coding:utf-8_*_ def select_sort(li): for i in range(len( ...
- Audio DSP 链接脚本文件解析
上篇文章(智能手表音乐播放功耗的优化)讲了怎么优化音乐场景下的功耗,其中第二点是优化memory的布局.那么在哪里优化memory的布局呢?就是在本文要讲的链接脚本(ld)文件里.作为audio DS ...
- 【Python】PDF文档导出指定章节为TXT
PDF文档导出指定章节为TXT 需求 要导出3000多个pdf文档的特定章节内容为txt格式(pdf文字可复制). 解决 导出PDF 查了一下Python操作PDF文档的方法,主要是通过3个库,PyP ...
- Linux下时区/系统时间/硬件时间的设置
涨姿势,顺带笔记,留爪. 先简述下时区/系统时间/硬件时间的3个主要命令吧 tzselect tzselect命令主要针对时区设置和查看 tz=timezone的缩写,直译=时区 date date命 ...
- SpringCloud——网关过滤工厂GatewayFilterFactory
目录 GatewayFilter 工厂 AddRequestHeader AddRequestHeadersIfNotPresent AddRequestParameter AddResponseHe ...
- Java编程--可变参数、foreach循环
/** * 可变参数与foreach循环 * 可变参数:方法可以接受任意多个参数 * 方法格式(参数类型...变量) * 使用方法传入的该变量时当作数组对待 * foreach循环:快速对数组进行操作 ...