Kafka为什么吞吐量大,速度快?
前言
根据个人的经历,无论在工作中,还是即将要经历的面试,MQ这部分是肯定要了解的,虽然之前工作中一直使用Kafka但是一些详细的细节知识还是了解的不深,所以这次总结一波。
Kafka为什么吞吐量这么大还能这么快(高吞吐&低延迟)?
顺序写
Kafka是会将消息持久化到本地磁盘的,但是一般我们认为对磁盘的操作性能都不会太高,实际上不管是内存还是磁盘,读写快或慢关键在于寻址的方式,磁盘和内存都有顺序写与随机写,基于磁盘的随机写却是很慢,但是基于磁盘的顺序写性能是很高的,一般高于随机写3个数量级,某些情况下磁盘的顺序写性能甚至高于内存的随机写。
顺序写的快的主要原因在于:减少了磁盘寻道时间,顺序写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机写。
页缓存(page cache)+异步刷盘机制
即便是顺序写入磁盘,磁盘的访问速度还是不可能跟内存相比的,所以kafka充分利用了现代操作系统分页存储来利用内存提高I/O效率。
**当kafka接收到生产者发送的一条消息时,并不会直接将消息写入到磁盘,而是写入到操作系统的页缓存中,然后通过定时操作,批量将页缓存中的数据刷到磁盘中,当然如果达到页缓存数据量阈值也是会提前触发刷盘操作。
**
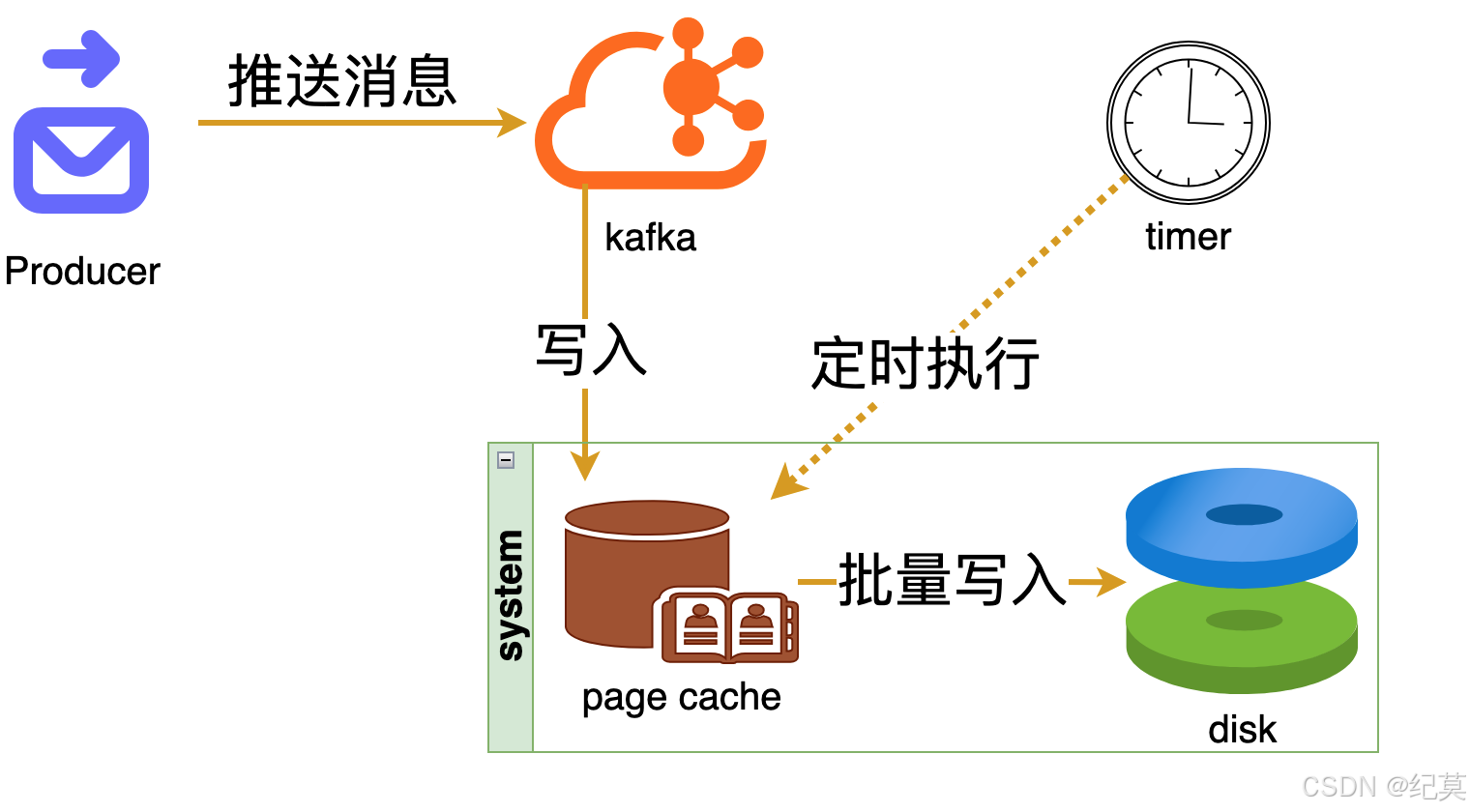
页缓存是操作系统预留的一部分内存区域,以固定大小的页为单位(4K或8K)来缓存磁盘数据。
同步副本机制(ISR)
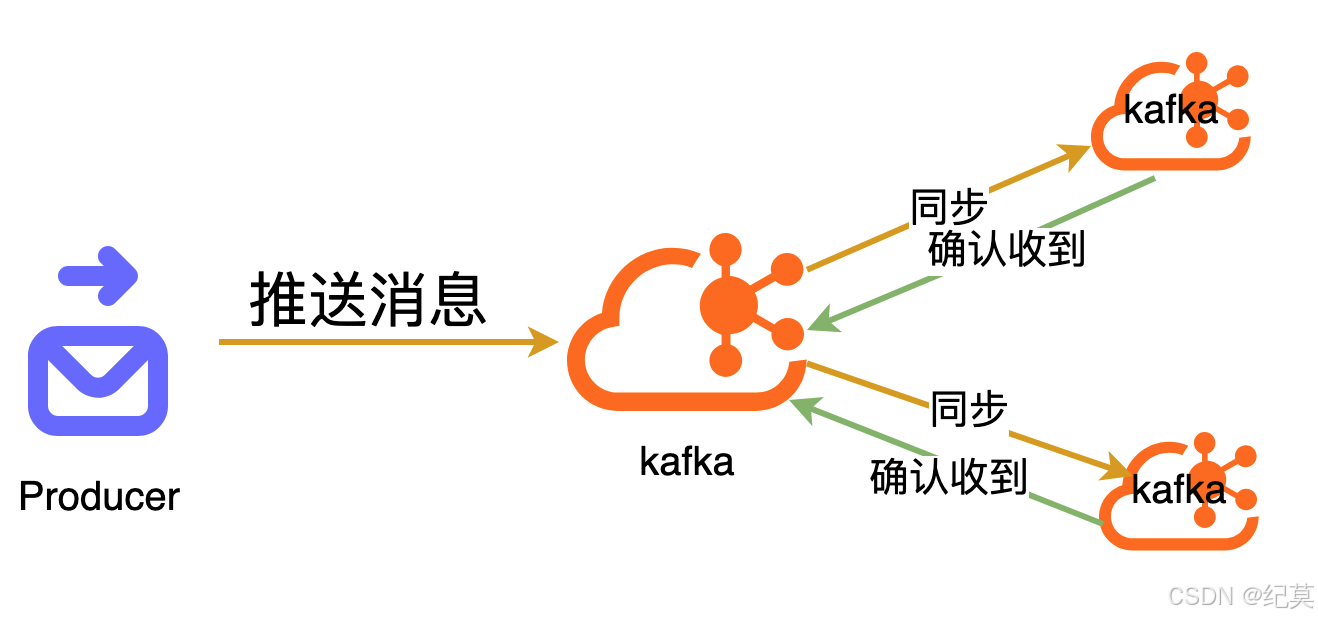
通过使用页缓存,让kafka的写入操作在明面上都是与内存交互的,速度肯定就很快了,但是因为是先写入到缓存中,然后再刷盘,所以就有可能存在还没来得及从缓存刷到磁盘,服务节点就宕机了,这样消息就丢了。
所以,kafka引入了同步副本节点,即一个 Kafka 节点可有多个同步副本节点。生产者发送消息后,Kafka 需等同步副本节点也接收到消息,才向生产者返回成功,这样主节点挂掉后,可从同步副本节点重新选举新主节点。
日志分段与索引机制
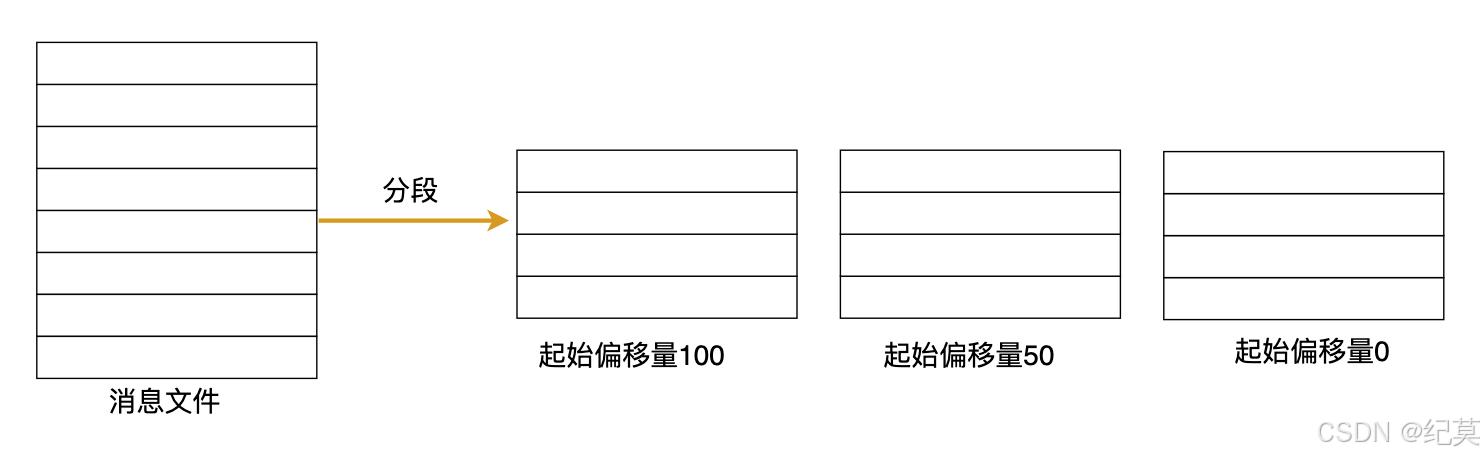
上面都是在说kafka如何提高写的速度了,那么写的再快,读的很慢,kafka还是快不起来,所以为了提升读的速度,kafka将文件按段分成多个小文件,一是为了方便删除老数据,二是可以通过偏移量基于二分法快速定位到具体的小文件。同时加入了索引机制,用小文件粗颗粒度记录偏移量和物理地址的关系,还增加时间索引,支持通过时间戳快速定位消息,以此加快读取速度。
零拷贝技术
我们知道操作系统分为内核态和用户态,而我们正常情况下想从磁盘中读取一条数据并通过网络发送给消费者,需要先通过 DMA 将数据从磁盘拷贝到内核态的页缓存,然后再通过 CPU 把数据从内核态拷贝到用户态的 kafka,把数据拷贝到内核态的网络缓冲区,最后 DMA 把数据拷贝给网卡。
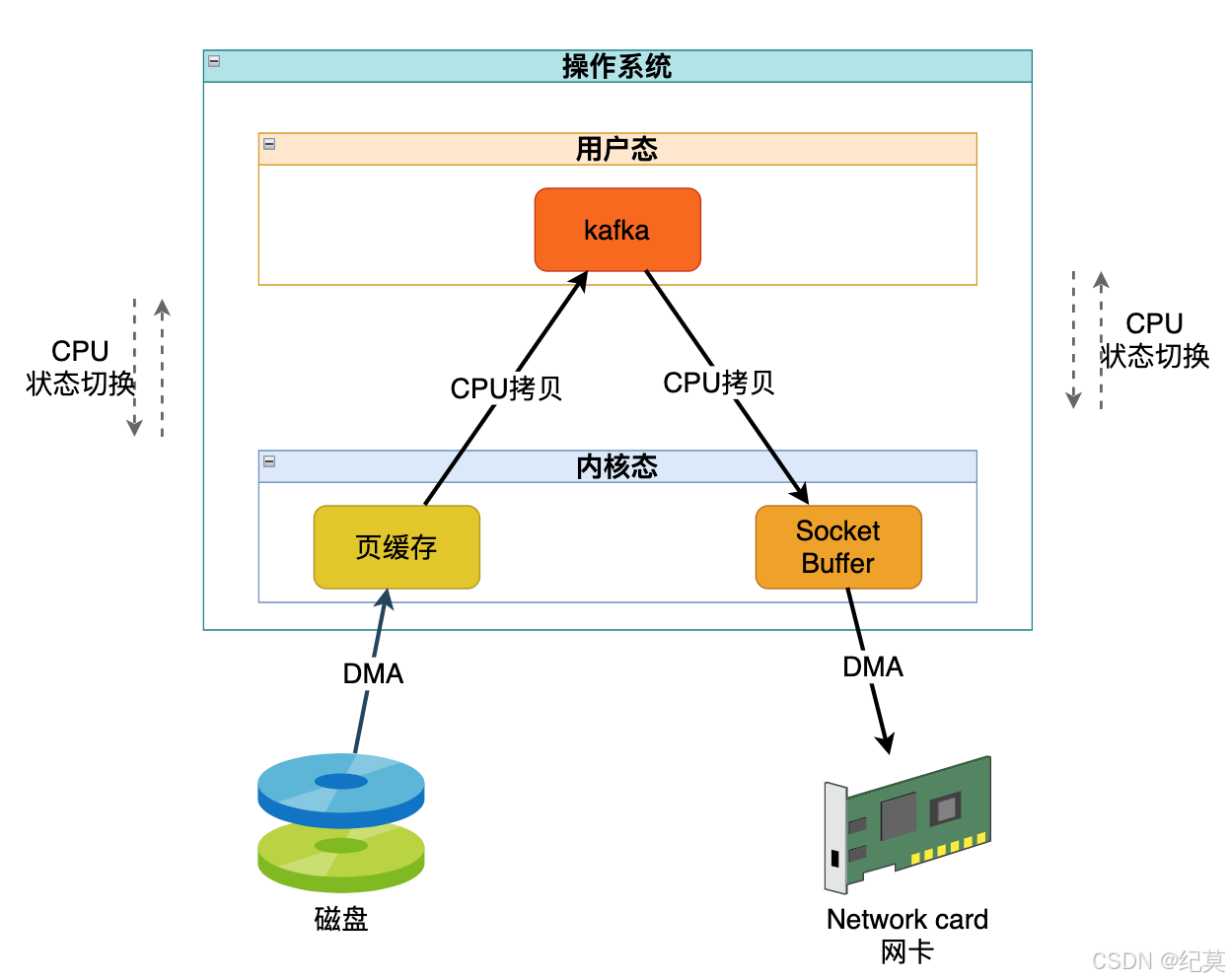
这拷贝来拷贝去的 CPU 还需要在内核态和用户态之间来回切换,看着就很麻烦。
那有没有更好的方法?
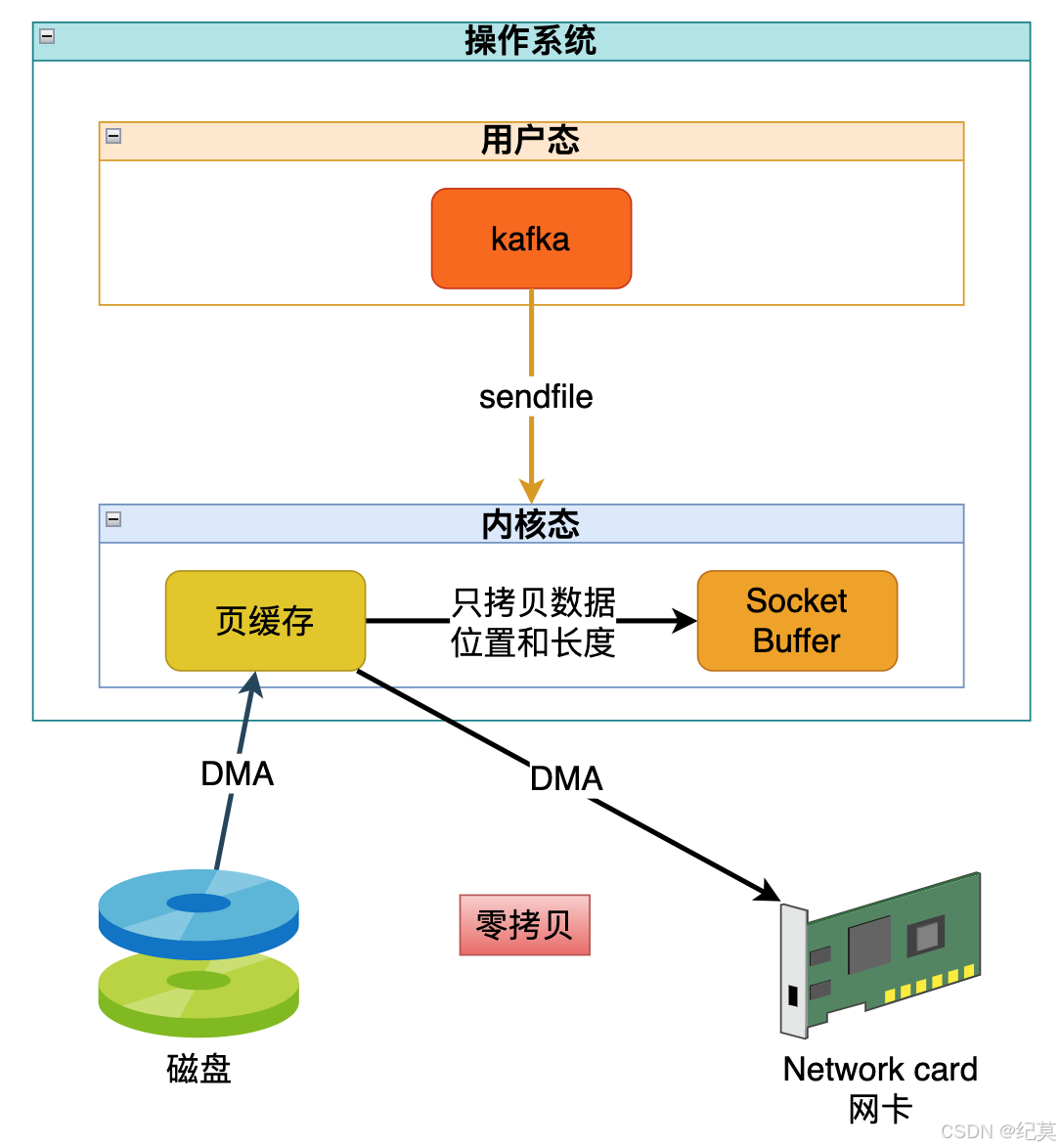
LINUX2.1 便提供了一个 sendfile 的系统函数,它可以直接把数据从页缓存拷贝到网络缓冲区,然后发送给网卡。
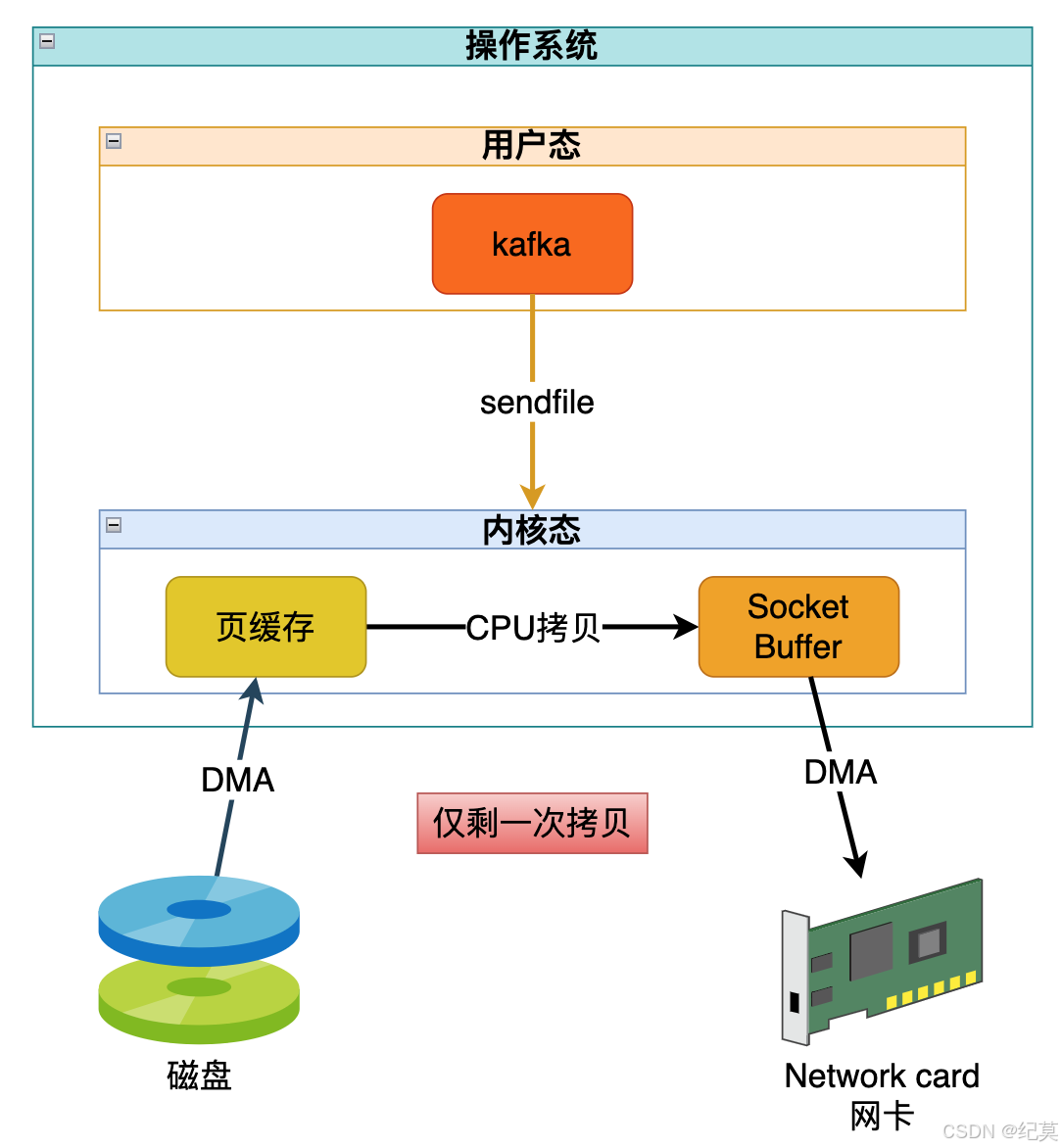
后来到了 LINUX2.4 时代,如果有带收集功能的 DMA 可以更进一步直接将数据从页缓存拷贝到网卡,实现了真正的零拷贝。
分区并行
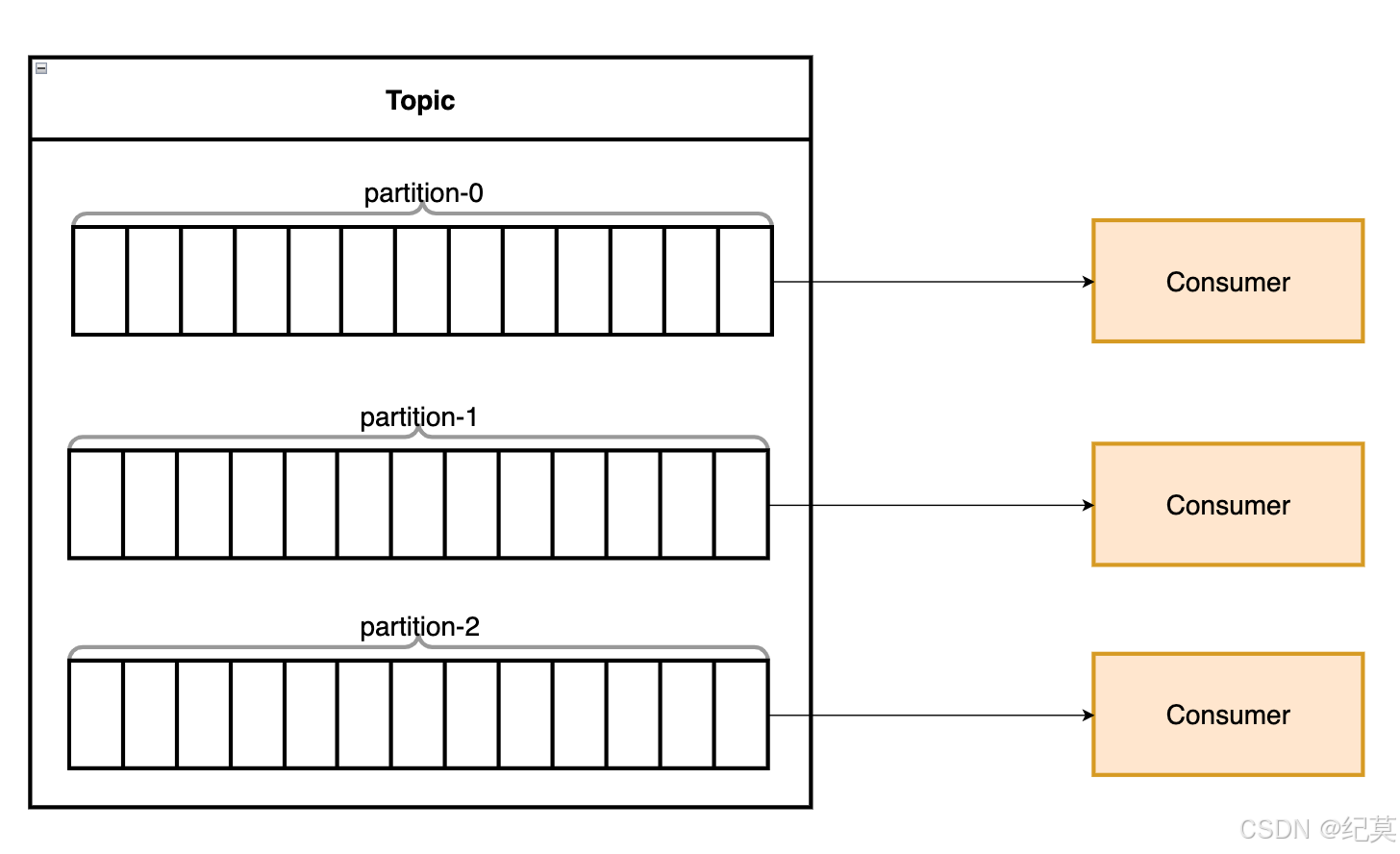
无论 kafka 速度有多快,如果消费者速度跟不上怎么办?
我们知道一个消息队列只能消费者一个一个消费,就算我多加几个消费者也只会增加锁争抢的压力。
所以 kafka 便将消息队列分成多个区,每个区可以有单独的消费者。
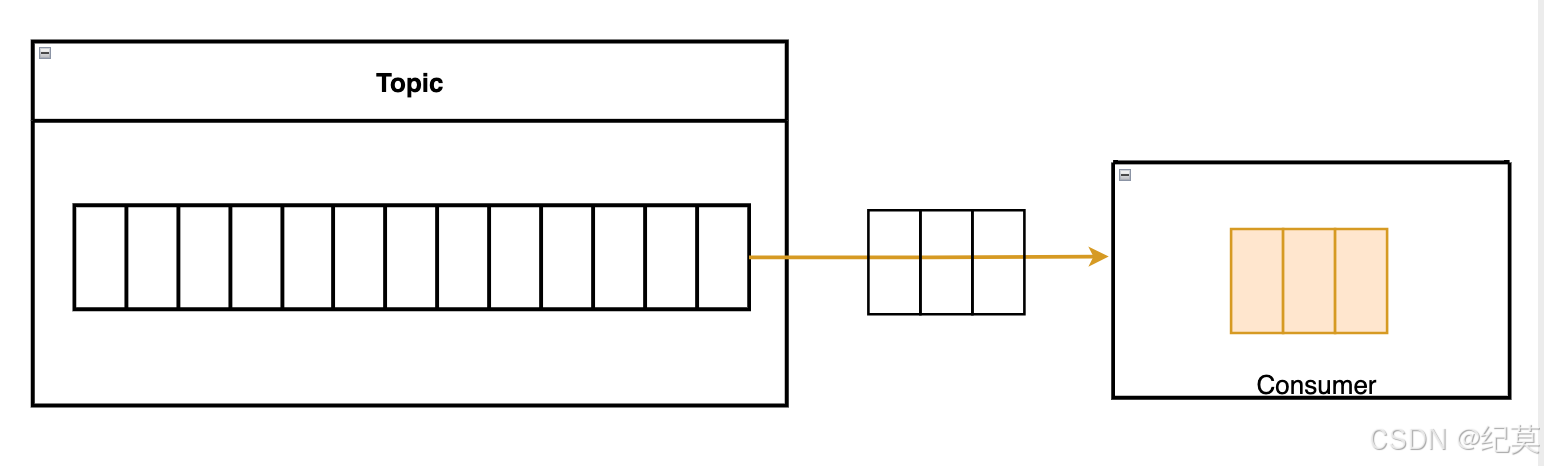
批量处理
kafka的一个消费者可一次性从消息队列中获取多个消息进行批量处理,同样生产者也可以批量处理。
生产者发送消息后会先暂存在本地,然后再异步批量向消息队列投递消息。不过这个就不推荐了,容易导致丢消息。
reactor 线程模型
请看IO模型解释:https://www.cnblogs.com/jimoer/p/11462457.html#autoid-2-4-0
数据压缩
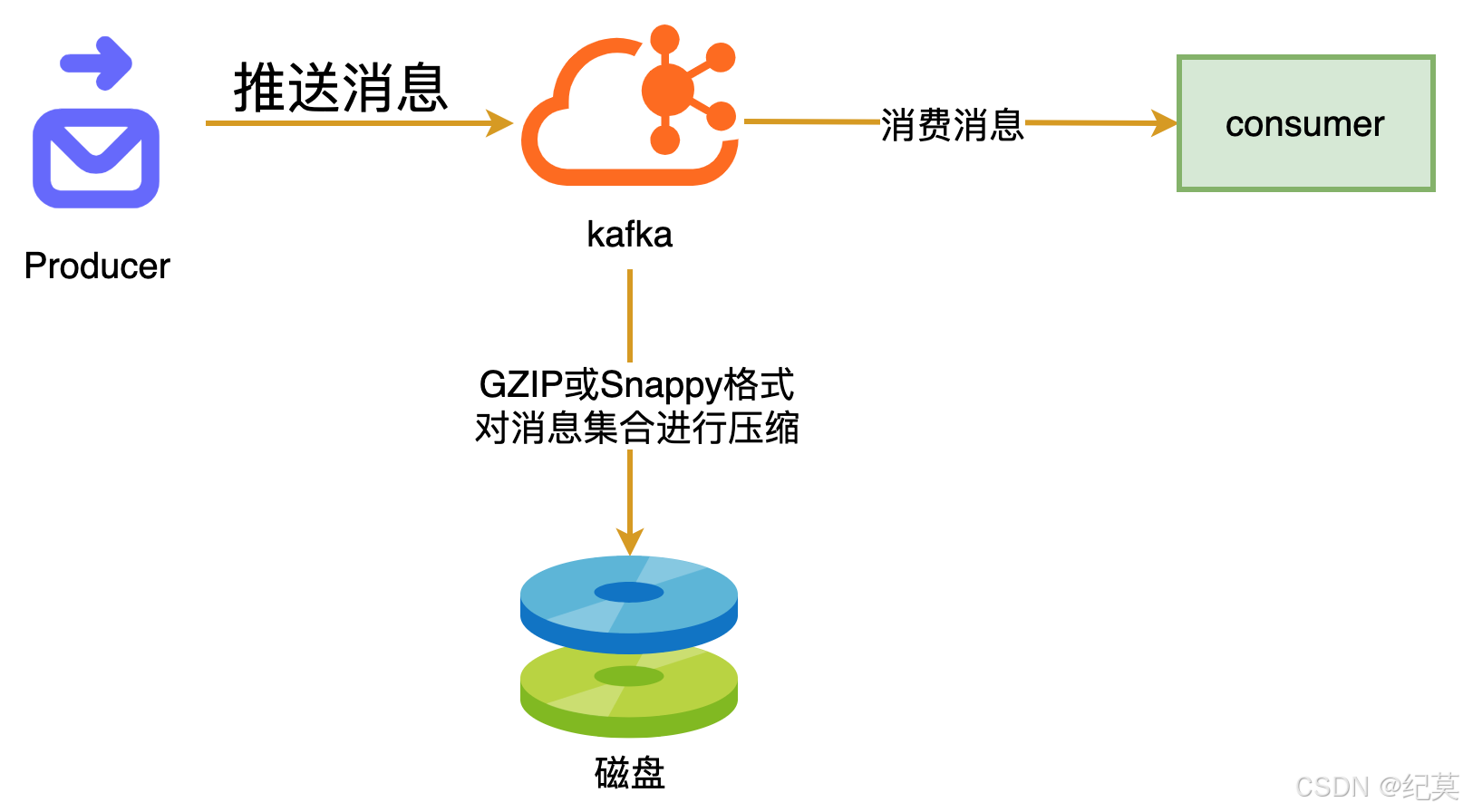
卡夫卡会通过压缩算法将消息压缩后进行传输和持久化,这个也能一定程度上提高网络传输和磁盘存储的速度。
Kafka 还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩,压缩的好处就是减少传输的数据量,减轻对网络传输的压力,Producer压缩之后,在Consumer需进行解压,虽然增加了CPU的工作,但在对大数据处理上,瓶颈在网络上而不是CPU,所以这个成本很值得。
Kafka为什么吞吐量大,速度快?的更多相关文章
- Kafka consumer处理大消息数据问题
案例分析 处理kafka consumer的程序的时候,发现如下错误: ERROR [2016-07-22 07:16:02,466] com.flow.kafka.consumer.main.Kaf ...
- kafka为什么吞吐量高,怎样保证高可用
1:kafka可以通过多个broker形成集群,来存储大量数据:而且便于横向扩展. 2:kafka信息存储核心的broker,通过partition的segment只关心信息的存储,而生产者只负责向l ...
- kafka高吞吐量之消息压缩
背景 保证kafka高吞吐量的另外一大利器就是消息压缩.就像上图中的压缩饼干. 压缩即空间换时间,通过空间的压缩带来速度的提升,即通过少量的cpu消耗来减少磁盘和网络传输的io. 消息压缩模型 消息格 ...
- Kafka — 高吞吐量的分布式发布订阅消息系统【转】
1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic.发送消息.消费消息?3.如何书写Kafka程序?4.数据传输的事务定义有哪三种?5.Kafka判断一个节点是否活着有哪两个条件 ...
- kafka高吞吐量的分布式发布订阅的消息队列系统
一:kafka介绍kafka(官网地址:http://kafka.apache.org)是一种高吞吐量的分布式发布订阅的消息队列系统,具有高性能和高吞吐率. 1.1 术语介绍BrokerKafka集群 ...
- 关于使用kafka时对于大数据消息体是遇到的问题
kafka对于消息体的大小默认为单条最大值是1M. 但是在我们应用场景中, 常常会出现一条消息大于1M, 如果不对kafka进行配置. 则会出现生产者无法将消息推送到kafka或消费者无法去消费kaf ...
- Flume+Kafka+Storm+Redis 大数据在线实时分析
1.实时处理框架 即从上面的架构中我们可以看出,其由下面的几部分构成: Flume集群 Kafka集群 Storm集群 从构建实时处理系统的角度出发,我们需要做的是,如何让数据在各个不同的集群系统之间 ...
- kafka 高吞吐量的因素
1.顺序的方式存储数据: 2.批量发送: 3.零拷贝: 来源:咕泡学院
- 第1节 kafka消息队列:11、kafka的数据不丢失机制,以及kafka-manager监控工具的使用;12、课程总结
12.kafka如何保证数据的不丢失 12.1生产者如何保证数据的不丢失 kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到 如果是同步模 ...
- 大数据之Kafka史上最详细原理总结
Kafka Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实 ...
随机推荐
- 1.3K star!像拿快递一样传送文件,这么酷!
嗨,大家好,我是小华同学,关注我们获得 "最新.最全.最优质" 开源项目和高效工作学习方法 trzsz 是一款革命性的文件传输工具,专为终端用户设计.它完美兼容传统 rz/sz 协 ...
- DialogHub上线OpenHarmony开源社区,高效开发鸿蒙应用弹窗
作为鸿蒙应用开发者,在使用ArkUI现有能力进行弹窗开发时,总会遇到一些让人纠结的交互问题:应用内进行消息提示时,既要求消息内容支持图文混排,又要求弹窗本身不能打断用户交互(页面滑动.页面点击.键盘输 ...
- 【翻译】Processing系列|(一)简介及使用方法
下一篇:[翻译]Processing系列|(二)安卓模式的安装使用及打包发布 下下篇:[翻译] Processing系列|(三)安卓项目构建 考虑到,学习啥都肯定要先读人家的官方文档,笔者把这个系列的 ...
- 若依ruoyi项目学习(一)项目跑起来!
开个坑,记录自己学习若依的心得,感兴趣的小伙伴可以关注一波. 因为自己也比较菜,可能能为大家提供一个较低的视角去分析,希望大家能一起学习. 当然,即时视角很低,也不适合0基础的朋友~ 项目地址: 前置 ...
- 腾讯IMA VS 飞书知识问答:谁才是2025最强AI知识库?
AI创业失败,可私聊经验教训分享... 前几天小伙伴在讨论我开发的一套社群运营AI分身,其本质其实是一套个人知识库的AI产品,其依赖的就是我过往发布的文章. 这类AI聊天分身,最简单.不考虑" ...
- Spring Boot MyBatis使用type-aliases-package自定义类别名
摘要:介绍MyBatis 中 type-aliases-package 属性的作用.在Spring Boot项目中,使用属性type-aliases-package为MyBatis引用的实体类自定义别 ...
- IDEA 设置类文件注释模板
在写代码的时候,经常需要在类上编写注释,以标明这个类是谁写的和有什么作用,其实每次写都是那么几个相同的属性,比如作者.创建时间和功能描述等.在idea中,我们可以设置在创建类时自动加载注释,本文介 ...
- 阿里微服务解决方案-Alibaba Cloud之集成Nacos(服务注册与发现)(三)
一.集成 Nacos(服务注册与发现) 1.1 下载 Nacos Nacos下载地址 1.2 下载后解压到本地 1.3 启动 Nacos 启动成功界面 输入 http://127.0.0.1:8848 ...
- Coze工作流实战:一键生成治愈风格视频
导航 前言 工作流生成治愈系视频的效果 操作步骤 调试 结语 参考 前言 最近治愈系短视频的热度非常高. 在快节奏的工作和生活中,我们总是感觉焦虑.迷茫,在内耗和内卷的夹缝中生存. 治愈系视频带给我们 ...
- 几分钟了解下java虚拟机--02
几分钟应该看不完,私密马赛, 俺是标题党 既然来了, 看看吧, 球球你了 Java类加载器 类的生命周期和加载过程 加载 加载所有的.class文件/jar文件/网络流 →字节流 (JVM 与java ...