snowflake算法的workerId问题
snowflake做为一个轻量级的分布式id生成算法,已经被广泛使用,大致原理如下:
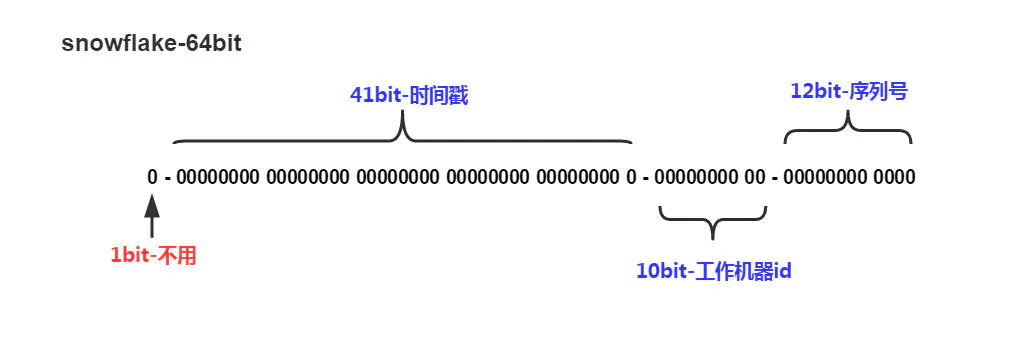
中间10位工作机器id(即:workerId),从图上可以知道,最多2^10次方,即1024台机器
最右侧12位序列号,2^12次方,即:4096
理论上,如果部署1024台机器,1ms内最多可生成1024*4096 = 4194304(约400万) 个id ,大多数应用场景中已经足够了。
根据这个思路,有很多语言版本的实现,下面是java版本:
public class SnowFlake {
/**
* 起始的时间戳
*/
private final static long START_STMP = 1480166465631L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 10; //机器标识占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long TIMESTMP_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastStmp = -1L;//上一次时间戳
public SnowFlake(long machineId) {
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.machineId = machineId;
}
/**
* 产生下一个ID
*
* @return
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake(0);
for (int i = 0; i < (1 << 12); i++) {
System.out.println(snowFlake.nextId());
}
}
}
结合前面提到的原理可知,集群部署环境下每台机器的应用启动时,初始化SnowFlake应该指定集群内唯一的workerId,否则如果每个机器上的workerId都一样,就有可能生成重复的id(即:相当于集群中,只有一个workerId,这样同1ms内,最多也就生成4096个id,这在高并发业务系统中,是很容易达到的)。
很多朋友都知道,机器上的ip可以转换成int数据,很容易想到,由于每台机器的ip不同(至少同1集群中不会重复),将ip转换出来的数字,对worker上限总数取模(注:worker总数只要小于1024即可,比如假设集群部署的机器,不会超过512台,就可以指定worker总数为 512),用这个取模的结果做为workerId似乎是一个不错的选择(事实上有的项目就是这么干的),上线后,大概率也能平稳运行。
但是!现在很多项目都是跑在云上(或k8s集群中),分布式环境中容器出现问题被重启是不可避免的,而且机器重启后通常ip也会变化。可能有一天会突然发现,snowflake生成的id出现了重复,但是代码并没有做过任何变更!
隐患就在于上面提到的ip取模算法,先给出ip转换成int的方法(网上copy来的):
public class IpUtils {
// 将127.0.0.1形式的IP地址转换成十进制整数,这里没有进行任何错误处理
public static long ipToLong(String strIp) {
long[] ip = new long[4];
// 先找到IP地址字符串中.的位置
int position1 = strIp.indexOf(".");
int position2 = strIp.indexOf(".", position1 + 1);
int position3 = strIp.indexOf(".", position2 + 1);
// 将每个.之间的字符串转换成整型
ip[0] = Long.parseLong(strIp.substring(0, position1));
ip[1] = Long.parseLong(strIp.substring(position1 + 1, position2));
ip[2] = Long.parseLong(strIp.substring(position2 + 1, position3));
ip[3] = Long.parseLong(strIp.substring(position3 + 1));
return (ip[0] << 24) + (ip[1] << 16) + (ip[2] << 8) + ip[3];
}
// 将十进制整数形式转换成127.0.0.1形式的ip地址
public static String longToIP(long longIp) {
StringBuffer sb = new StringBuffer("");
// 直接右移24位
sb.append(String.valueOf((longIp >>> 24)));
sb.append(".");
// 将高8位置0,然后右移16位
sb.append(String.valueOf((longIp & 0x00FFFFFF) >>> 16));
sb.append(".");
// 将高16位置0,然后右移8位
sb.append(String.valueOf((longIp & 0x0000FFFF) >>> 8));
sb.append(".");
// 将高24位置0
sb.append(String.valueOf((longIp & 0x000000FF)));
return sb.toString();
}
}
如果worker总数最大为512,看看下面2个ip,按前面的思路,取模后的结果如何:
long p1 = IpUtils.ipToLong("10.47.130.37");
long p2 = IpUtils.ipToLong("10.96.184.37");
int workerCount = 512;
System.out.println(p1 % workerCount);
System.out.println(p2 % workerCount);
将得到2个37,也就是这2台机器生成相同的workerId,所以它俩在并发高的情况下,有就较大概率生成相同的id,而且这个bug还挺难查的,可能机器一重启,又正常了(因为ip变了),如果只是偶尔出现,还会让人误以为是“时钟回拨”问题。
那么,合理的做法应该如何设置workerId呢?可以借助redis,对集群内的机器在应用启动时做一个workerId的全局登记,流程图如下:
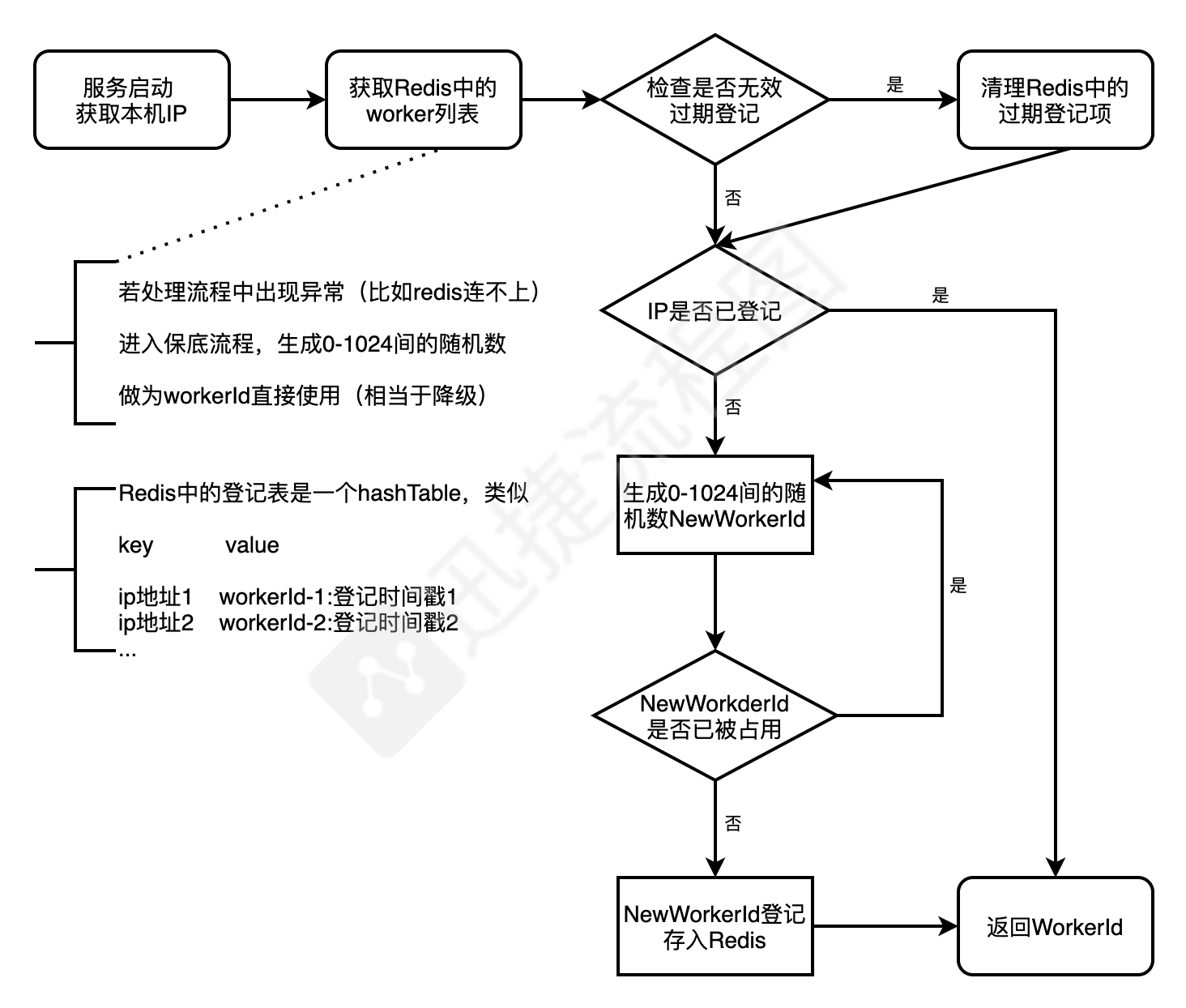
注1:因为容器随时可能被销毁,如果机器没了,登记表里的记录就没用了,相当于成了脏数据,所以检查过程中,有一步清理过期记录就是用来干这个的(判断是否过期记录,可借助“登记时间戳”来判断,比如3个月前登记的认为是无效的)
注2:意外情况下,比如启动时正好redis发生故障连不上,可以考虑降级为随机生成1个workerId先用着(视业务场景酌情而定)
最后,顺便提一句,如果考虑到时钟回拨问题,可以使用一些大厂的改进版本,比如百度的uid-generator ,或美团的leaf
snowflake算法的workerId问题的更多相关文章
- snowflake算法(java版)
转自:http://www.cnblogs.com/haoxinyue/p/5208136.html 1. 数据库自增长序列或字段 最常见的方式.利用数据库,全数据库唯一. 优点: 1)简单,代码方 ...
- twitter的snowflake算法(C#版本)
转自:http://blog.csdn.net/kinwyb/article/details/50238505 使用twitter的snowflake算法生成唯一ID. 在分布式系统中,需要生成全局U ...
- twitter的ID生成器的snowFlake算法的自造版
snowFlake算法在生成ID时特别高效,可参考:https://segmentfault.com/a/1190000011282426 SnowFlake算法生成id的结果是一个64bit大小的整 ...
- 分布式唯一id:snowflake算法思考
匠心零度 转载请注明原创出处,谢谢! 缘起 为什么会突然谈到分布式唯一id呢?原因是最近在准备使用RocketMQ,看看官网介绍: 一句话,消息可能会重复,所以消费端需要做幂等.为什么消息会重复后续R ...
- 基于Twitter的Snowflake算法实现分布式高效有序ID生产黑科技(无懈可击)
参考美团文档:https://tech.meituan.com/2017/04/21/mt-leaf.html Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万 ...
- id生成器,分布式ID自增算法(Snowflake 算法)
接口: /** * id生成器 */ public interface IdGenerator { String next(); } 实现类: /** * 分布式ID自增算法<br/> * ...
- 关于snowflake算法生成的ID转换为JS的数字类型由于过大导致JS精度丢失的问题
JS的数字类型目前支持的最大值为:9007199254740992,一旦数字超过这个值,JS将会丢失精度,导致前后端的值出现不一致. JAVA的Long类型的 最大值为:922337203 ...
- 根据twitter的snowflake算法生成唯一ID
C#版本 /// <summary> /// 根据twitter的snowflake算法生成唯一ID /// snowflake算法 64 位 /// 0---0000000000 000 ...
- C# 根据twitter的snowflake算法生成唯一ID
C# 版算法: using System; using System.Collections.Generic; using System.Linq; using System.Text; using ...
- snowflake算法
snowflake算法思考 缘起 为什么会突然谈到分布式唯一id呢?原因是最近在准备使用RocketMQ,看看官网介绍: 一句话,消息可能会重复,所以消费端需要做幂等.为什么消息会重复后续Rocket ...
随机推荐
- Servlet创建的三种方式
目录 1 实现Servlet接口 2 继承GenericServlet 3 继承HttpServlet 4 web.xml配置 关于servlet的创建,我们有三种方式. 实现Servlet接口 继承 ...
- Alembic迁移脚本:让数据库变身时间旅行者
title: Alembic迁移脚本:让数据库变身时间旅行者 date: 2025/05/09 13:08:18 updated: 2025/05/09 13:08:18 author: cmdrag ...
- RabbitMQ高级使用
概述 在支付场景中,支付成功后利用RabbitMQ通知交易服务,更新业务订单状态为已支付.但是大家思考一下,如果这里MQ通知失败,支付服务中支付流水显示支付成功,而交易服务中的订单状态却显示未支付,数 ...
- TVM:使用自动调度优化算子
与基于模板的AutoTVM不同(会依赖手动模板定义搜索空间),自动调度器不需要任何模板.用户只需要编写计算声明,而不需要任何调度命令或模板.自动调度器可以自动生产一个大的搜索空间,并在空间中找到一个好 ...
- Java 删除目录下相同文件
摘要:通过MD5算法对指定目录下的文件去重. 背景 之前写了一篇博客<Java判断两个文件是否相同>,介绍如何校验两个文件内容是否相同,但是,不适用于对目录下文件去重的场景,故对其进行 ...
- Vue3+Ts笔记:基于element-UI 实现下拉框滚动翻页查询通用组件
element 提供了 el-select组件,并且支持远程搜索,但是对于数据量大需要翻页的场景并未提供相应配置,所以自己写了一个通用组件,作为记录 初始化控件,定义传入参数 将远程查询的接口封装为函 ...
- CentOS 7.* 安装最新版nginx1.28*
一.下载nginx https://nginx.org/en/download.html 选择稳定版本 nginx-1.28.0 如果使用虚拟机,可以先用windows系统下载后,上传到虚机,此步骤省 ...
- Spring扩展接口-内置事件ContextEvent
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- 【中文】【吴恩达课后编程作业】Course 2 - 改善深层神经网络 - 第三周作业
[中文][吴恩达课后编程作业]Course 2 - 改善深层神经网络 - 第三周作业 - TensorFlow入门 上一篇:[课程2 - 第三周测验]※※※※※ [回到目录]※※※※※下一篇:[课程3 ...
- pip安装模块提示Command "python setup.py egg_info" failed with error code 1
报错详情: [root@k8s001 ~]# pip install kubernetes Collecting kubernetes Using cached https://files.pytho ...