MySQL 10 MySQL为什么有时候会选错索引?
场景引入
我们知道,MySQL中一张表可以支持多个索引。但是写SQL语句时,并没有主动指定使用哪个索引,而是由MySQL来确定。而有时候,MySQL会选错索引,导致执行速度变得很慢。
举个例子,假设一张表里有(id,a,b)三个字段,并分别建立索引。然后往表中插入10万行记录,取值依次递增,即数据从(1,1,1)一直到(100000,100000,100000)。
插入过程用了一个存储过程:
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into t values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
接下来分析一条SQL语句:
select * from t where a between 10000 and 20000;
显然,该语句能用上索引a。对该语句进行EXPLAIN,查看执行情况:

接着,在表t上做如下操作:

如上,session A开启了一个事务,随后session B删除所有数据,又调用存储过程插入数据,并进行查询。
但是,这条查询语句没有选择索引a。使用如下三条语句进行实验:
set long_query_time=0;
select * from t where a between 10000 and 20000;
select * from t force index(a) where a between 10000 and 20000;/*对照作用*/
慢查询日志如下:
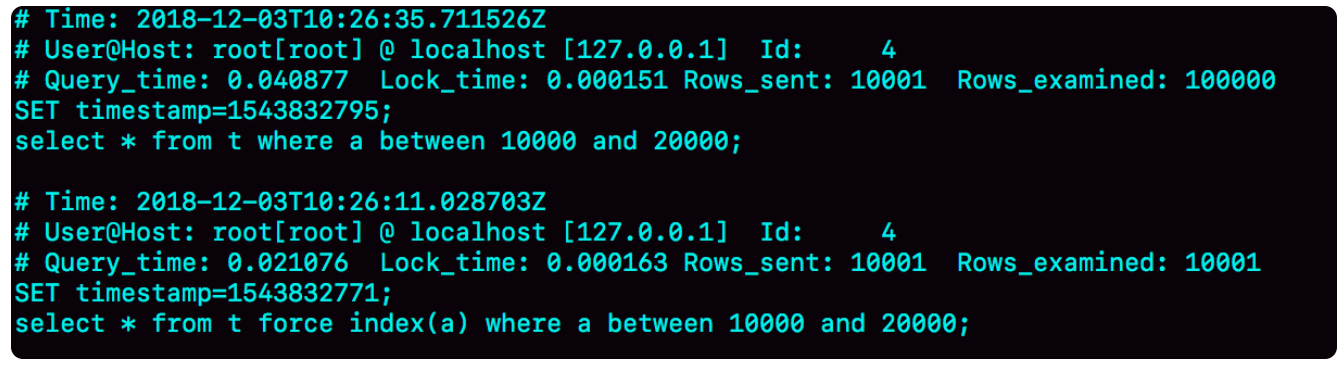
可以发现,session B的查询语句走的是全表扫描,即MySQL用错了索引。
这个场景其实很常见,对应平时不断删除数据和新增数据的场景。因此,本文要讲清为什么会选错索引。
优化器的逻辑
在MySQL 01里,我们已经介绍过了,选择索引是由MySQL的优化器完成的。优化器选择索引的目的是找到一个最优的执行方案,并用最小代价执行语句。
在数据库里,判断执行代价的标准有很多。直观的就是扫描行数,扫描行数越少,意味着访问磁盘次数越少,消耗的CPU资源越少。除此之外,优化器还会结合是否使用临时表、是否排序等因素进行综合判断。
在前面的例子中,没有涉及临时表和排序,那么就是在判断扫描行数是判断错误了。因此,我们需要知道,MySQL如何判断扫描行数。
MySQL在执行语句之前,并不能精确知道满足条件的记录有多少条,只能根据统计信息进行估算。这个统计信息指的是索引的区分度。一个索引上不同的值(我们称之为基数)越多,索引的区分度就越好。
可以使用show index方法来看索引的基数。我们查看例子中表t的基数,其结果如下:

可以发现,尽管三个字段插入的数据都是相同的,但MySQL统计的基数都不同,且都不准确。
由于取每行进行统计代价太高,MySQL在统计基数时使用的是采样统计的方法:采样统计时,InnoDB默认选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,计算出这个索引的基数。
数据表会持续更新,因此索引统计信息也会不断变化。当变更的数据行数超过总行数的1/M,会自动触发重新做一次索引统计。在MySQL中,索引统计有两种存储方式,可以通过设置参数innodb_stats_persistent的值进行选择:
设为on,表示统计信息持久化存储,此时默认
N=20,M=10;设为off,表示统计信息只存在内存,此时默认
N=8,M=16。
尽管基数统计不是完全准确,但从show index的结果看,大体还是接近的,因此选错索引还有其他原因。
除了进行基数统计,优化器还会判断执行语句本身要扫描多少行。对于例子的语句,优化器预估的扫描行数为:
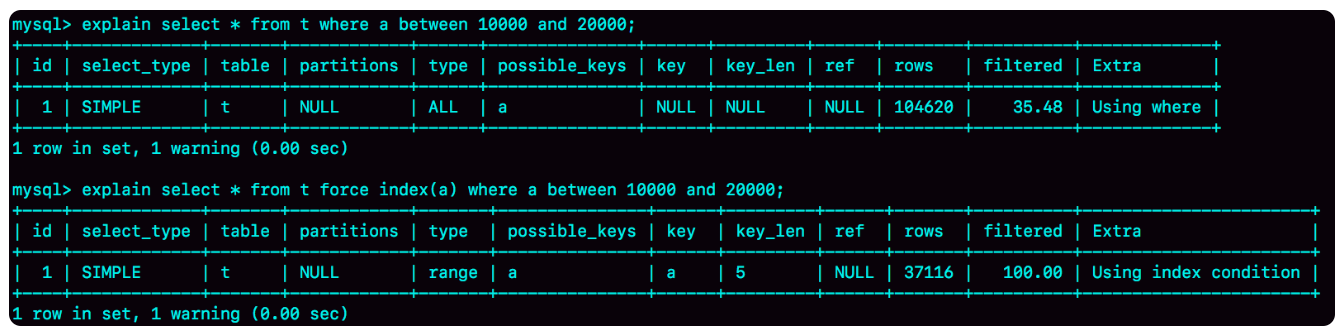
从rows字段可以看出,没用上a索引的预计扫描行数为104620,而强制使用a索引的预计扫描行数为37116。
此时,你或许有疑问,既然用上索引a的扫描行数少,且该语句可以用索引a,为什么优化器不使用呢?
这是因为,如果使用索引a,在select *时,需要先从索引a得到id,再回到主键索引找出整行数据,优化器会计算这个代价;如果不使用索引a,是直接在主键索引上扫描并获得数据。在这个例子中,优化器认为直接扫描主键索引更快,尽管该判断是错误的。
因此选错索引的本质原因还在于没有准确判断出扫描行数。
既然是统计信息有误,就需要进行修正。可以使用analyze table t来重新统计索引信息:
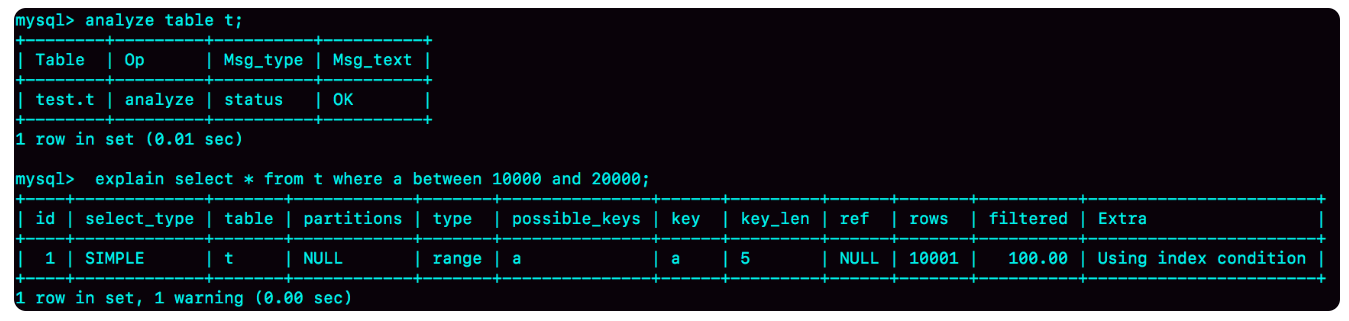
可以发现这次判断正确。因此,当发现explain的结果和实际情况差距较大,可以先使用analyze进行重新统计。
基于相同的表t,来看另外一个语句:
select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1;
从条件来看,这个查询返回的是空。那么在索引的选择上,该语句会怎么选择呢?
按照我们自己的分析:
若使用索引a,会先扫描索引a的前1000个值,取到对应的id后进行回表,然后根据字段b进行过滤,这样需要扫描1000行。
若使用索引b,会先扫描索引b的最后50001个值,取到对应的id后进行回表,然后根据字段b进行过滤,这样需要扫描50001行。
对该语句explain的结果:

可以看到,优化器选择的是索引b,预估扫描行数为50198,即MySQL又选错了索引。
索引选择异常和处理
遇到上面例子中选错索引的情况,处理办法主要有三种:
(1)采用force index强制选择索引
在不强制选择索引时,MySQL会根据词法解析结果分析出可能使用的索引,然后依次判断每个索引需要扫描多少行。而强制选择后,MySQL会直接选择这个索引。
比如对于例子2,假设使用force index强制选择索引a:

可以看到,使用合理的索引,速度快了很多。
不过强制选择也有缺点:
如果索引改名,该语句也得修改;
如果以后迁移到其他数据库,该语法不一定兼容;
变更不及时,往往是等出现选错索引的问题时才会去强制选择。
(2)修改语句
比如在例子2中,将order by b limit 1改为order by b,a limit 1,语义逻辑不变。但之前优化器使用索引b是因为认为使用索引b可以避免排序,而修改后使用两个索引都需要排序,扫描行数成了影响决策的主要条件,此时优化器选择扫描行数较少的a。
这种方法的缺点就是不通用,需要根据不同语句做不同修改。
(3)新建更合适的索引
在有些场景下,可以新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引。
MySQL 10 MySQL为什么有时候会选错索引?的更多相关文章
- 10 | MySQL为什么有时候会选错索引? 学习记录
<MySQL实战45讲>10 | MySQL为什么有时候会选错索引? 学习记录http://naotu.baidu.com/file/e7c521276650e80fe24584bc9a6 ...
- 10 | MySQL为什么有时候会选错索引?
前面我们介绍过索引,你已经知道了在MySQL中一张表其实是可以支持多个索引的.但是,你写SQL语句的时候,并没有主动指定使用哪个索引.也就是说,使用哪个索引是由MySQL来确定的. 不知道你有没有碰到 ...
- MySQL选错索引导致的线上慢查询事故
前言 又和大家见面了!又两周过去了,我的云笔记里又多了几篇写了一半的文章草稿.有的是因为质量没有达到预期还准备再加点内容,有的则完全是一个灵感而已,内容完全木有.羡慕很多大佬们,一周能产出五六篇文章, ...
- 10 mysql选错索引
10 mysql选错索引 在mysql表中可以支持多个索引,有的sql不指定使用哪个索引,由mysql自己来决定,但是有时候mysql选错了索引,导致执行很慢. 例子 CREATE TABLE `t1 ...
- MySQL 笔记整理(10) --MySQL为什么有时会选错索引?
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> (本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除) 10) --MySQL为什么有时会选错索引? MySQL中的一张表上可以 ...
- MySQL 选错索引的原因?
MySQL 中,可以为某张表指定多个索引,但在语句具体执行时,选用哪个索引是由 MySQL 中执行器确定的.那么执行器选择索引的原则是什么,以及会不会出现选错索引的情况呢? 先看这样一个例子: 创建表 ...
- MySQL ORDER BY主键id加LIMIT限制走错索引
背景及现象 report_product_sales_data表数据量2800万: 经测试,在当前数据量情况下,order by主键id,limit最大到49的时候可以用到索引report_produ ...
- Mysql only_full_group_by以及其他关于sql_mode原因报错详细解决方案
Mysql only_full_group_by以及其他关于sql_mode原因报错详细解决方案 网上太多相关资料,但是抄袭严重,有的讲的也是之言片语的,根本不连贯(可能知道的人确实不想多说) 我总共 ...
- mysql启动时报错:Starting MySQL... ERROR! The server quit without updating PID file (/opt/mysql/data/mysql.pid) 的解决方法
出现问题的可能性 1.可能是/opt/mysql/data/数据目录mysql用户没有权限(修改数据目录的权限) 解决方法 :给予权限,执行 "chown -R mysql.mysql / ...
- 【MYSQL】MYSQL报错解决方法: Warning: (3719, "'utf8' is currently an alias for the character set UTF8MB3, but will be an alias for UTF8M B4 in a future release."
用python3.6.5创建mysql库时出现如下报错,虽然报错,但是数据库可以插入成功. D:\python3\lib\site-packages\pymysql\cursors.py:170: W ...
随机推荐
- 大量数据topk-分桶+堆+多路并归解决方案
利用分桶.堆与多路归并解决 TopK 问题:结果处理阶段解析 在处理大规模数据时,TopK 问题是一个常见且具有挑战性的任务,即从海量数据中找出最大(或最小)的 K 个元素.为了高效地解决这个问题,我 ...
- nodejs读写json文件
读json文件 'use strict'; const fs = require('fs'); let rawdata = fs.readFileSync('student.json'); let s ...
- 🎀腾讯云nodejs SDK打包体积过大吐槽事件
简介 2025年2月1日有位开发同学batchor在GitHub上提出了issue(你们是把***打包了吗?)对腾讯云Node.js的SDK打包体积过大进行吐槽(言语偏贴吧风格略显激进),SDK打包体 ...
- 基于华为交换机的三层Clos架构(Leaf-Spine)配置指南
基于华为交换机的三层Clos架构(Leaf-Spine)配置指南 目录 设计原则 配置步骤 物理连接与基础配置 路由协议配置 VXLAN+EVPN配置 M-LAG高可用配置 BFD快速检测 验证命令 ...
- 树莓派智能摄像头实战指南:基于TensorFlow Lite的端到端AI部署
引言:嵌入式AI的革新力量 在物联网与人工智能深度融合的今天,树莓派这一信用卡大小的计算机正在成为边缘计算的核心载体.本文将手把手教你打造一款基于TensorFlow Lite的低功耗智能监控设备,通 ...
- 代码随想录第六天 | Leecode 242.有效的字母异位词、 349. 两个数组的交集、202. 快乐数、1. 两数之和
昨天第五天是周日休息一天,今天第六天开始哈希表部分题目. Leecode 242.有效的字母异位词 题目链接:https://leetcode.cn/problems/valid-anagram/de ...
- PC端自动化测试实战教程-5-pywinauto 操作PC端应用程序窗口 - 下篇(详细教程)
1.简介 上一篇宏哥主要讲解和介绍了如何获取PC端应用程序窗口信息和如何连接窗口对其进行操作的常用的几种方法.今天宏哥接着讲解和分享一下窗口的基本操作:最大化.最小化.恢复正常.关闭窗口.获取窗口状态 ...
- 信息资源管理综合题之“S公司规划网络系统-内部用户需要使用的信息安全技术及其相应用途”
一.案例:S公司是某网络设备制造商在国内的一级代理商,总部设在上海,在外高桥有一处大型的仓库,其二级经销商客户分布在全国几十座大中城市,并在北京.成都.西安和沈阳等地设立了办事处.总部实施了ERP系统 ...
- 原生JS表格数据常用总结
主要是在数据报表这块, 做了好几年发现, 其实用户最终想要看的并不是酷炫的BI大屏, 而是最基础也是最复杂的 中国式报表. 更多就是倾向于从表格中去获取数据信息, 最简单的就是最好的, 于是还是来总结 ...
- 编译原理:中间代码IR
IR,中间代码(Intermediate Representation,有时也称为Intermediate Code,IC),它是编译器中很重要的一种数据结构.编译器在做完前端工作以后,首先就生成IR ...