SynchronousQueue的put方法底层源码
一、SynchronousQueue的put方法底层源码
SynchronousQueue 的 put 方法用于将元素插入队列。由于 SynchronousQueue 没有实际的存储空间,put 方法会阻塞,直到有消费者线程调用 take 方法移除元素
1、put 方法的作用
将元素插入队列。
如果没有消费者线程等待,当前线程会阻塞,直到有消费者线程移除元素。
该方法不会返回任何值,也不会抛出异常(除非线程被中断)。
2、put 方法的源码
以下是 SynchronousQueue 中 put 方法的源码(基于 JDK 17):

可以看到,put 方法的核心逻辑是通过 transferer.transfer 方法实现的。transferer 是 SynchronousQueue 的内部组件,负责实际的数据传输
3、transferer.transfer 方法
transferer 是一个抽象类,有两个实现:
TransferStack:用于非公平模式。
TransferQueue:用于公平模式。
以下是 TransferStack 和 TransferQueue 中 transfer 方法的通用逻辑:
(1)TransferStack.transfer 方法
E transfer(E e, boolean timed, long nanos) {
SNode s = null; // 创建一个新节点
int mode = (e == null) ? REQUEST : DATA; // 判断是生产者还是消费者
for (;;) {
SNode h = head; // 获取栈顶节点
if (h == null || h.mode == mode) { // 如果栈为空或模式匹配
if (timed && nanos <= 0) { // 如果超时
if (h != null && h.isCancelled()) // 如果节点已取消
casHead(h, h.next); // 移除已取消的节点
else
return null; // 返回 null
} else if (casHead(h, s = snode(s, e, h, mode))) { // 尝试插入新节点
SNode m = awaitFulfill(s, timed, nanos); // 等待匹配
if (m == s) { // 如果节点被取消
clean(s); // 清理节点
return null; // 返回 null
}
if ((h = head) != null && h.next == s) // 如果匹配成功
casHead(h, s.next); // 移除匹配的节点
return (E) ((mode == REQUEST) ? m.item : s.item); // 返回数据
}
} else if (!isFulfilling(h.mode)) { // 如果栈顶节点未完成匹配
if (h.isCancelled()) // 如果节点已取消
casHead(h, h.next); // 移除已取消的节点
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) { // 尝试插入新节点
for (;;) {
SNode m = s.next; // 获取下一个节点
if (m == null) { // 如果下一个节点为空
casHead(s, null); // 重置栈顶
s = null; // 重置节点
break;
}
SNode mn = m.next;
if (m.tryMatch(s)) { // 尝试匹配
casHead(s, mn); // 移除匹配的节点
return (E) ((mode == REQUEST) ? m.item : s.item); // 返回数据
} else
s.casNext(m, mn); // 移除未匹配的节点
}
}
} else { // 如果栈顶节点已完成匹配
SNode m = h.next; // 获取下一个节点
if (m == null) // 如果下一个节点为空
casHead(h, null); // 重置栈顶
else {
SNode mn = m.next;
if (m.tryMatch(h)) // 尝试匹配
casHead(h, mn); // 移除匹配的节点
else
h.casNext(m, mn); // 移除未匹配的节点
}
}
}
}
(2)TransferQueue.transfer 方法
E transfer(E e, boolean timed, long nanos) {
QNode s = null; // 创建一个新节点
boolean isData = (e != null); // 判断是生产者还是消费者
for (;;) {
QNode t = tail;
QNode h = head;
if (t == null || h == null) // 如果队列未初始化
continue;
if (h == t || t.isData == isData) { // 如果队列为空或模式匹配
QNode tn = t.next;
if (t != tail) // 如果 tail 已更新
continue;
if (tn != null) { // 如果 tail 未更新
advanceTail(t, tn); // 更新 tail
continue;
}
if (timed && nanos <= 0) // 如果超时
return null; // 返回 null
if (s == null) // 如果节点未初始化
s = new QNode(e, isData); // 创建新节点
if (!t.casNext(null, s)) // 尝试插入新节点
continue;
advanceTail(t, s); // 更新 tail
Object x = awaitFulfill(s, e, timed, nanos); // 等待匹配
if (x == s) { // 如果节点被取消
clean(t, s); // 清理节点
return null; // 返回 null
}
if (!s.isOffList()) { // 如果节点未移除
advanceHead(t, s); // 更新 head
if (x != null) // 如果匹配成功
s.item = s; // 标记节点
s.waiter = null; // 清除等待线程
}
return (x != null) ? (E)x : e; // 返回数据
} else { // 如果模式不匹配
QNode m = h.next;
if (t != tail || m == null || h != head) // 如果队列已更新
continue;
Object x = m.item;
if (isData == (x != null) || x == m || !m.casItem(x, e)) { // 如果匹配失败
advanceHead(h, m); // 移除未匹配的节点
continue;
}
advanceHead(h, m); // 更新 head
LockSupport.unpark(m.waiter); // 唤醒等待线程
return (x != null) ? (E)x : e; // 返回数据
}
}
}
4、关键点总结
无存储空间:SynchronousQueue 没有容量,插入和移除操作必须一一对应。
阻塞行为:如果没有配对的插入或移除操作,线程会一直阻塞。
公平性:公平模式下,等待时间最长的线程优先获得执行机会。
二、SynchronousQueue的类结构
先看一下SynchronousQueue类里面有哪些属性:
public class SynchronousQueue<E>
extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/**
* 转接器(栈和队列的父类)
*/
abstract static class Transferer<E> {
/**
* 转移(put和take都用这一个方法)
*
* @param e 元素
* @param timed 是否超时
* @param nanos 纳秒
*/
abstract E transfer(E e, boolean timed, long nanos);
}
/**
* 栈实现类
*/
static final class TransferStack<E> extends Transferer<E> {
}
/**
* 队列实现类
*/
static final class TransferQueue<E> extends Transferer<E> {
}
}
SynchronousQueue底层是基于Transferer抽象类实现的,放数据和取数据的逻辑都耦合在transfer()方法中。而Transferer抽象类又有两个实现类,分别是基于栈结构实现和基于队列实现
1、初始化
SynchronousQueue常用的初始化方法有两个:
1、无参构造方法
2、指定容量大小的有参构造方法
/**
* 无参构造方法
*/
BlockingQueue<Integer> blockingQueue1 = new SynchronousQueue<>(); /**
* 有参构造方法,指定是否使用公平锁(默认使用非公平锁)
*/
BlockingQueue<Integer> blockingQueue2 = new SynchronousQueue<>(true);
再看一下对应的源码实现:
/**
* 无参构造方法
*/
public SynchronousQueue() {
this(false);
}
/**
* 有参构造方法,指定是否使用公平锁
*/
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
可以看出SynchronousQueue的无参构造方法默认使用的非公平策略,有参构造方法可以指定使用公平策略。 操作策略:
1、公平策略,基于队列实现的是公平策略,先进先出。
2、非公平策略,基于栈实现的是非公平策略,先进后出。
2、栈的类结构
/**
* 栈实现
*/
static final class TransferStack<E> extends Transferer<E> {
/**
* 头节点(也是栈顶节点)
*/
volatile SNode head;
/**
* 栈节点类
*/
static final class SNode {
/**
* 当前操作的线程
*/
volatile Thread waiter;
/**
* 节点值(取数据的时候,该字段为null)
*/
Object item;
/**
* 节点模式(也叫操作类型)
*/
int mode;
/**
* 后继节点
*/
volatile SNode next;
/**
* 匹配到的节点
*/
volatile SNode match;
}
}
节点模式有以下三种:
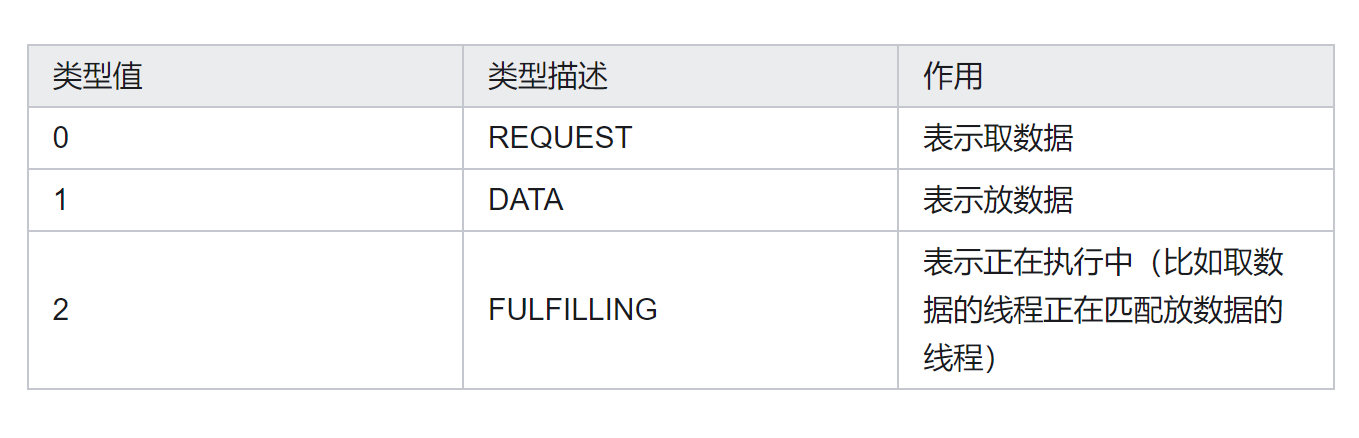
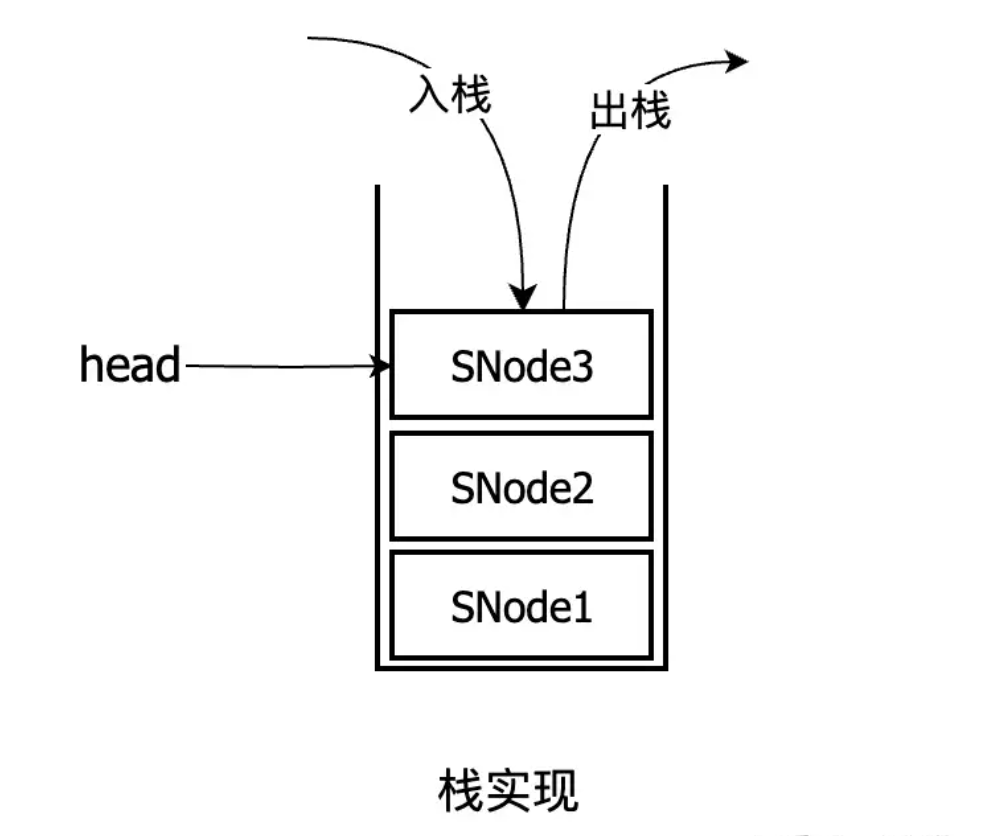
3、栈的transfer方法实现
transfer()方法中,把放数据和取数据的逻辑耦合在一块了,逻辑有点绕,不过核心逻辑就四点,把握住就能豁然开朗。其实就是从栈顶压入,从栈顶弹出。
详细流程如下:
1、首先判断当前线程的操作类型与栈顶节点的操作类型是否一致,比如都是放数据,或者都是取数据。
2、如果是一致,把当前操作包装成SNode节点,压入栈顶,并挂起当前线程。
3、如果不一致,表示相互匹配(比如当前操作是放数据,而栈顶节点是取数据,或者相反)。然后也把当前操作包装成SNode节点压入栈顶,并使用tryMatch()方法匹配两个节点,匹配成功后,弹出两个这两个节点,并唤醒栈顶节点线程,同时把数据传递给栈顶节点线程,最后返回。
4、栈顶节点线程被唤醒,继续执行,然后返回传递过来的数据。
/**
* 转移(put和take都用这一个方法)
*
* @param e 元素(取数据的时候,元素为null)
* @param timed 是否超时
* @param nanos 纳秒
*/
E transfer(E e, boolean timed, long nanos) {
SNode s = null;
// 1. e为null,表示要取数据,否则是放数据
int mode = (e == null) ? REQUEST : DATA;
for (; ; ) {
SNode h = head;
// 2. 如果本次操作跟栈顶节点模式相同(都是取数据,或者都是放数据),就把本次操作包装成SNode,压入栈顶
if (h == null || h.mode == mode) {
if (timed && nanos <= 0) {
if (h != null && h.isCancelled()) {
casHead(h, h.next);
} else {
return null;
}
// 3. 把本次操作包装成SNode,压入栈顶,并挂起当前线程
} else if (casHead(h, s = snode(s, e, h, mode))) {
// 4. 挂起当前线程
SNode m = awaitFulfill(s, timed, nanos);
if (m == s) {
clean(s);
return null;
}
// 5. 当前线程被唤醒后,如果栈顶有了新节点,就删除当前节点
if ((h = head) != null && h.next == s) {
casHead(h, s.next);
}
return (E) ((mode == REQUEST) ? m.item : s.item);
}
// 6. 如果栈顶节点类型跟本次操作不同,并且模式不是FULFILLING类型
} else if (!isFulfilling(h.mode)) {
if (h.isCancelled()) {
casHead(h, h.next);
}
// 7. 把本次操作包装成SNode(类型是FULFILLING),压入栈顶
else if (casHead(h, s = snode(s, e, h, FULFILLING | mode))) {
// 8. 使用死循环,直到匹配到对应的节点
for (; ; ) {
// 9. 遍历下个节点
SNode m = s.next;
// 10. 如果节点是null,表示遍历到末尾,设置栈顶节点是null,结束。
if (m == null) {
casHead(s, null);
s = null;
break;
}
SNode mn = m.next;
// 11. 如果栈顶的后继节点跟栈顶节点匹配成功,就删除这两个节点,结束。
if (m.tryMatch(s)) {
casHead(s, mn);
return (E) ((mode == REQUEST) ? m.item : s.item);
} else {
// 12. 如果没有匹配成功,就删除栈顶的后继节点,继续匹配
s.casNext(m, mn);
}
}
}
} else {
// 13. 如果栈顶节点类型跟本次操作不同,并且是FULFILLING类型,
// 就再执行一遍上面第8步for循环中的逻辑(很少概率出现)
SNode m = h.next;
if (m == null) {
casHead(h, null);
} else {
SNode mn = m.next;
if (m.tryMatch(h)) {
casHead(h, mn);
} else {
h.casNext(m, mn);
}
}
}
}
}
不用关心细枝末节,把握住代码核心逻辑即可。 再看一下第4步,挂起线程的代码逻辑: 核心逻辑就两条:
第6步,挂起当前线程
第3步,当前线程被唤醒后,直接返回传递过来的match节点
/**
* 等待执行
*
* @param s 节点
* @param timed 是否超时
* @param nanos 超时时间
*/
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
// 1. 计算超时时间
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
// 2. 计算自旋次数
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (; ; ) {
if (w.isInterrupted())
s.tryCancel();
// 3. 如果已经匹配到其他节点,直接返回
SNode m = s.match;
if (m != null)
return m;
if (timed) {
// 4. 超时时间递减
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
// 5. 自旋次数减一
if (spins > 0)
spins = shouldSpin(s) ? (spins - 1) : 0;
else if (s.waiter == null)
s.waiter = w;
// 6. 开始挂起当前线程
else if (!timed)
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
再看一下匹配节点的tryMatch()方法逻辑: 作用就是唤醒栈顶节点,并当前节点传递给栈顶节点。
/**
* 匹配节点
*
* @param s 当前节点
*/
boolean tryMatch(SNode s) {
if (match == null &&
UNSAFE.compareAndSwapObject(this, matchOffset, null, s)) {
Thread w = waiter;
if (w != null) {
waiter = null;
// 1. 唤醒栈顶节点
LockSupport.unpark(w);
}
return true;
}
// 2. 把当前节点传递给栈顶节点
return match == s;
}
4、队列的类结构
/**
* 队列实现
*/
static final class TransferQueue<E> extends Transferer<E> {
/**
* 头节点
*/
transient volatile QNode head;
/**
* 尾节点
*/
transient volatile QNode tail;
/**
* 队列节点类
*/
static final class QNode {
/**
* 当前操作的线程
*/
volatile Thread waiter;
/**
* 节点值
*/
volatile Object item;
/**
* 后继节点
*/
volatile QNode next;
/**
* 当前节点是否为数据节点
*/
final boolean isData;
}
}
可以看出TransferQueue队列是使用带有头尾节点的单链表实现的。 还有一点需要提一下,TransferQueue默认构造方法,会初始化头尾节点,默认是空节点。
/**
* TransferQueue默认的构造方法
*/
TransferQueue() {
QNode h = new QNode(null, false);
head = h;
tail = h;
}
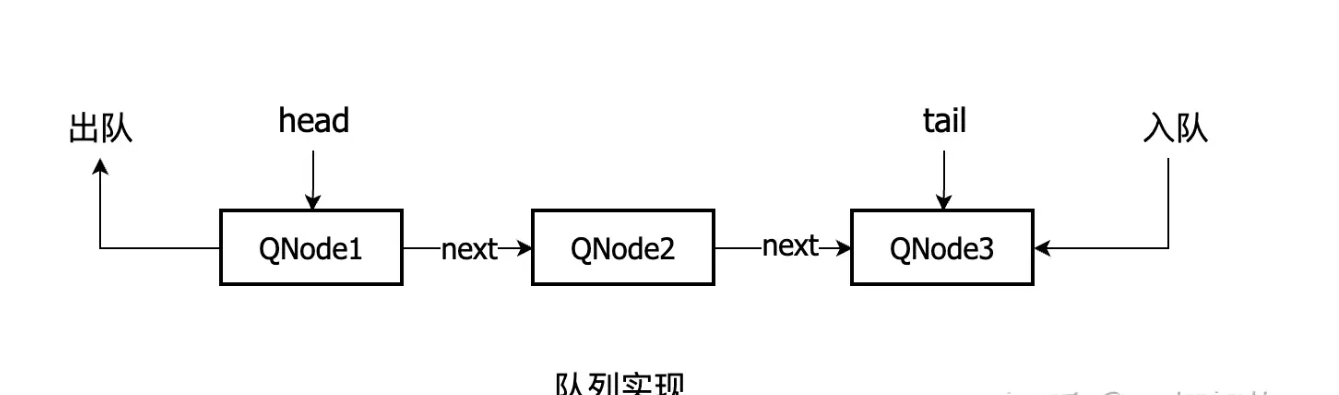
队列的transfer方法实现
队列使用的公平策略,体现在,每次操作的时候,都是从队尾压入,从队头弹出。 详细流程如下:
1、首先判断当前线程的操作类型与队尾节点的操作类型是否一致,比如都是放数据,或者都是取数据。
2、如果是一致,把当前操作包装成QNode节点,压入队尾,并挂起当前线程。
3、如果不一致,表示相互匹配(比如当前操作是放数据,而队尾节点是取数据,或者相反)。然后在队头节点开始遍历,找到与当前操作类型相匹配的节点,把当前操作的节点值传递给这个节点,并弹出这个节点,唤醒这个节点的线程,最后返回。
4、队头节点线程被唤醒,继续执行,然后返回传递过来的数据。
/**
* 转移(put和take都用这一个方法)
*
* @param e 元素(取数据的时候,元素为null)
* @param timed 是否超时
* @param nanos 超时时间
*/
E transfer(E e, boolean timed, long nanos) {
QNode s = null;
// 1. e不为null,表示要放数据,否则是取数据
boolean isData = (e != null);
for (; ; ) {
QNode t = tail;
QNode h = head;
if (t == null || h == null) {
continue;
}
// 2. 如果本次操作跟队尾节点模式相同(都是取数据,或者都是放数据),就把本次操作包装成QNode,压入队尾
if (h == t || t.isData == isData) {
QNode tn = t.next;
if (t != tail) {
continue;
}
if (tn != null) {
advanceTail(t, tn);
continue;
}
if (timed && nanos <= 0) {
return null;
}
// 3. 把本次操作包装成QNode,压入队尾
if (s == null) {
s = new QNode(e, isData);
}
if (!t.casNext(null, s)) {
continue;
}
advanceTail(t, s);
// 4. 挂起当前线程
Object x = awaitFulfill(s, e, timed, nanos);
// 5. 当前线程被唤醒后,返回返回传递过来的节点值
if (x == s) {
clean(t, s);
return null;
}
if (!s.isOffList()) {
advanceHead(t, s);
if (x != null) {
s.item = s;
}
s.waiter = null;
}
return (x != null) ? (E) x : e;
} else {
// 6. 如果本次操作跟队尾节点模式不同,就从队头结点开始遍历,找到模式相匹配的节点
QNode m = h.next;
if (t != tail || m == null || h != head) {
continue;
}
Object x = m.item;
// 7. 把当前节点值e传递给匹配到的节点m
if (isData == (x != null) || x == m ||
!m.casItem(x, e)) {
advanceHead(h, m);
continue;
}
// 8. 弹出队头节点,并唤醒节点m
advanceHead(h, m);
LockSupport.unpark(m.waiter);
return (x != null) ? (E) x : e;
}
}
}
SynchronousQueue的put方法底层源码的更多相关文章
- Android开发之漫漫长途 Ⅵ——图解Android事件分发机制(深入底层源码)
该文章是一个系列文章,是本人在Android开发的漫漫长途上的一点感想和记录,我会尽量按照先易后难的顺序进行编写该系列.该系列引用了<Android开发艺术探索>以及<深入理解And ...
- 为什么很多类甚者底层源码要implements Serializable ?
为什么很多类甚者底层源码要implements Serializable ? 在碰到异常类RuntimeException时,发现Throwable实现了 Serializable,还有我们平进的ja ...
- List-LinkedList、set集合基础增强底层源码分析
List-LinkedList 作者 : Stanley 罗昊 [转载请注明出处和署名,谢谢!] 继上一章继续讲解,上章内容: List-ArreyLlist集合基础增强底层源码分析:https:// ...
- 从底层源码浅析Mybatis的SqlSessionFactory初始化过程
目录 搭建源码环境 POM依赖 测试SQL Mybatis全局配置文件 UserMapper接口 UserMapper配置 User实体 Main方法 快速进入Debug跟踪 源码分析准备 源码分析 ...
- Java泛型底层源码解析-ArrayList,LinkedList,HashSet和HashMap
声明:以下源代码使用的都是基于JDK1.8_112版本 1. ArrayList源码解析 <1. 集合中存放的依然是对象的引用而不是对象本身,且无法放置原生数据类型,我们需要使用原生数据类型的包 ...
- 2018.11.20 Struts2中对结果处理方式分析&struts2内置的方式底层源码剖析
介绍一下struts2内置帮我们封装好的处理结果方式也就是底层源码分析 这是我们的jar包里面找的位置目录 打开往下拉看到result-type节点 name那一列就是我们的type类型取值 上一篇博 ...
- HashMap和ConcurrentHashMap的区别,HashMap的底层源码
HashMap本质是数组加链表,根据key取得hash值,然后计算出数组下标,如果多个key对应到同一个下标,就用链表串起来,新插入的在前面. ConcurrentHashMap在HashMap的基础 ...
- 总结HashSet以及分析部分底层源码
总结HashSet以及分析部分底层源码 1. HashSet继承的抽象类和实现的接口 继承的抽象类:AbstractSet 实现了Set接口 实现了Cloneable接口 实现了Serializabl ...
- LInkedList总结及部分底层源码分析
LInkedList总结及部分底层源码分析 1. LinkedList的实现与继承关系 继承:AbstractSequentialList 抽象类 实现:List 接口 实现:Deque 接口 实现: ...
- Vector总结及部分底层源码分析
Vector总结及部分底层源码分析 1. Vector继承的抽象类和实现的接口 Vector类实现的接口 List接口:里面定义了List集合的基本接口,Vector进行了实现 RandomAcces ...
随机推荐
- biancheng-HBase
目录http://c.biancheng.net/view/6509.html 1HBase是什么?2HBase的优势有哪些?3Hadoop与HBase的关系4HDFS5HDFS的特点与使用场景6HB ...
- uni-app中picker-view显示默认值的注意点(坑)
今天我在使用picker-view的时候,发现无法给picker-view给一个默认值:后面经过发现后: 才知道到,是一个异步问题: 1==>动态循环出来的数据,在data中直接循环,不要在re ...
- 部署Palworld幻兽帕鲁服务器最佳实践(Ubuntu)
本文为您介绍Ubuntu系统部署Palworld幻兽帕鲁服务器的最/佳实践. 1.登录云主机控制台,选择创建云主机的资源池,点击"创建云主机"按钮. 2.基础配置. CPU架构选择 ...
- 从零开始的函数式编程(2) —— Church Boolean 编码
[!quote] 关于λ表达式-- 详见λ表达式 本文导出自Obsidian,可能存在格式偏差(例如链接.Callout等) 本文地址:https://www.cnblogs.com/oberon-z ...
- JAVA基础环境配置指南(简洁版)
1.安装JDK 官网下载后直接安装 配置环境变量: 添加 JAVA_HOME 变量名:JAVA_HOME 变量值:C:\Program Files (x86)\Java\jdk1.8.0_91 // ...
- 5分钟搞定!用比扬云SD-WAN远程访问飞牛NAS全攻略
作为一个NAS重度用户,我最近遇到了一个头疼的问题:如何在外部安全地访问家里的飞牛NAS?经过一番摸索,我发现比扬云SD-WAN是个不错的解决方案,今天就来分享我的实战经验. 一.为什么选择比扬云SD ...
- STC内部扩展RAM的应用
RAM是用来在程序运行中存放随机变量的数据空间,51单片机默认的内部RAM只有128字节,52单片机增加至256字节,STC89C52增加到512字节,STC89C54.55.58.516等增加到12 ...
- java.lang.IllegalStateException: File name has been re-used with different files. (flume报错)
报错日志: java.lang.IllegalStateException: File name has been re-used with different files. Spooling ass ...
- 【Python】转载一个python 爬虫的帖子
原帖地址 原帖标题:爬取图网的4K图片自动保存本地 https://www.52pojie.cn/thread-1809600-1-1.html (出处: 吾爱破解论坛) python 代码 impo ...
- datagrid源码
/** * jQuery EasyUI 1.2.3 * * Licensed under the GPL terms * To use it on other terms please contact ...