AI应用实战课学习总结(11)用RNN做时序预测
大家好,我是Edison。
最近入坑黄佳老师的《AI应用实战课》,记录下我的学习之旅,也算是总结回顾。
今天是我们的第11站,一起了解RNN循环神经网络的基本概念 以及 通过RNN来做时序预测的案例。
RNN循环神经网络介绍
RNN(循环神经网络)是一种专门用于处理序列数据的神经网络架构。与传统的神经网络不同,RNN具有记忆能力,能够捕捉序列数据中的时间依赖关系。
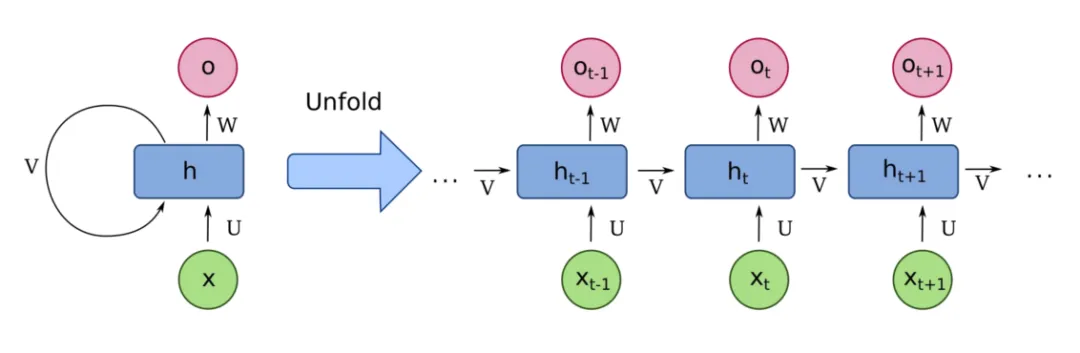
我们以一个例子来说RNN,有多个学生站成了一排,老师给第一个学生一个纸条,上面写着一句话,然后这个学生需要理解纸条上的第一个字的内容,然后再将纸条传给下一个学生,下一个学生理解第二个字的内容,然后再传给第三个学生理解第三个字的内容,以此类推不断往后传。与此同时,每个学生还有一个自己的笔记本,记录着自己对自己需要理解的那个字的理解,但可能并不是第一个字的真实内容,这个笔记本也会从第一个学生传到后续的学生。因此,从第二个学生开始,就有两条信息来源,一条是老师给的纸条自己需要去理解自己负责的那块内容,另一条是前面同学传来的笔记本可以去参考上一个同学给到的一些总结的隐藏信息,直到将这条纸条上的这句话理解完毕,再开始下一个纸条的理解传递。
从上面的解释看出,RNN对于每个序列在做循环处理,并且具有记忆功能,通过这种方式来捕捉序列模式和依赖关系。
RNN经常用于下列场景:
时间序列预测:例如股票市场预测、气象预测、流量分析等;
自然语言处理:例如文本生成、情感分析、机器翻译等;
语音识别:将语音信号转换成文本,广泛用于语音助手、转写工具等;
视频分析:处理视频数据中的连续帧,进行动作识别、事件检测等;
RNN的几种变体
主要的RNN变体有以下几种:
(1)Simple RNN
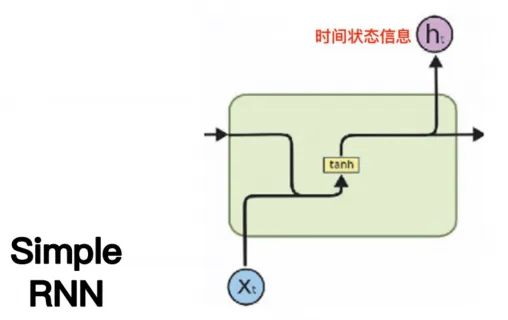
最原始的版本,它里面有一个时间状态信息作为短期记忆。它存在的问题是短期记忆,记不住太长的东西,处理到后面会把前面的内容忘记了。
(2)LSTM
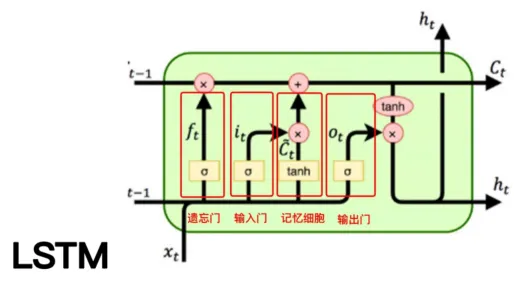
LSTM就解决了一部分短期记忆的问题,当然它的设计也复杂得多。但是它也没有完美的解决短期记忆问题,直到后期Transformer的自注意力机制出现,才把这个问题真正地解决。
(3)GRU
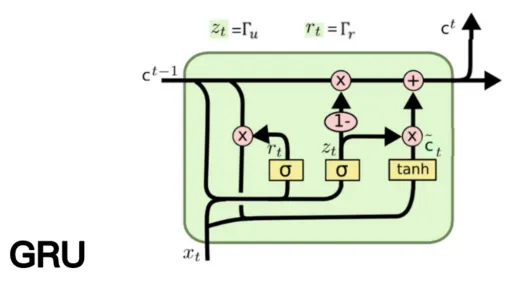
它解决了Simple RNN的问题,又比LSTM的设计简单一些,算是一个折中的方案。
各种神经网络的比较
(1)DNN(深度神经网络)
场景:
- 结构化数据的分类和回归问题
- 一些基本的图像识别任务
优势:对于非序列数据,DNN可以是一个良好的起点。
(2)RNN(循环神经网络)
场景:
- 时间序列预测
- 语音识别
- 语言模型和文本生成
- 机器翻译
优势:RNN设计用来捕捉时间或序列数据中的依赖关系,例如给定之前的单词或时间步,预测下一个单词或时间步的值。注意:需要注意RNN可能会遇到长序列的梯度消失或梯度爆炸的问题。
(3)CNN(卷积神经网络)
场景:
- 图像分类、对象检测和图像生成
- 语音识别和一些文本分类任务
优势:CNN可以捕捉到输入数据的局部特征,并且具有参数共享的特性,这使得它非常适合处理图像和其他具有空间或时间连续性的数据。
RNN做时序预测案例
问题背景:
某App记录了过去两年每天的用户注册人数数据
问题目标:
根据历史数据,预测后续一段时间的用户注册数?
RNN做时序预测代码实战
Step1 读取数据并做归一化处理
# 导入所需库
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable df_app = pd.read_csv('app-user-activiation-data.csv', index_col='Date', parse_dates=['Date']) #导入数据
# 按照2020年10月1日为界拆分数据集
Train = df_app[:'2020-09-30'].iloc[:,0:1].values #训练集
Test = df_app['2020-10-01':].iloc[:,0:1].values #测试集
from sklearn.preprocessing import MinMaxScaler #导入归一化缩放器
Scaler = MinMaxScaler(feature_range=(0,1)) #创建缩放器
Train = Scaler.fit_transform(Train) #拟合缩放器并对训练集进行归一化
# 对测试数据进行归一化处理
Test = Scaler.transform(Test)
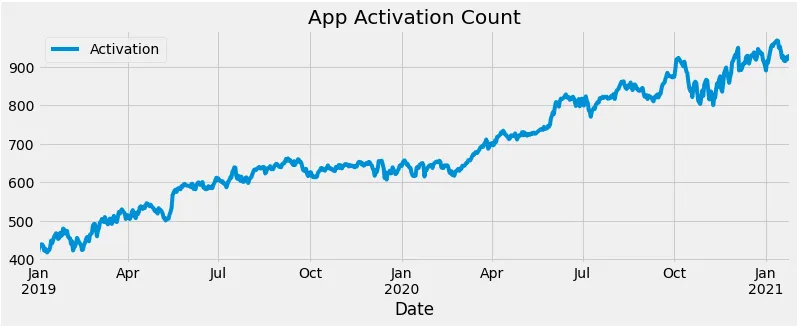
然后,借助matplotlib绘制用户注册人数图:
import matplotlib.pyplot as plt #导入matplotlib.pyplot
plt.style.use('fivethirtyeight') #设定绘图风格
df_app["Activation"].plot(figsize=(12,4),legend=True) #绘制激活数
plt.title('App Activation Count') #图题
plt.show() #绘图
绘制出来的图如下所示:
Step2 将数据集转化为序列 和 张量
为了能够将数据集转化为PyTorch可以识别的内容,需要对数据集做时序转换 以及 张量转换。
# 创建一个函数,将数据集转化为时间序列格式
def sliding_windows(data, seq_length):
x = []
y = []
for i in range(len(data)-seq_length):
_x = data[i:(i+seq_length)]
_y = data[i+seq_length]
x.append(_x)
y.append(_y)
return np.array(x),np.array(y)
# 设定窗口大小
seq_length = 4
x_train, y_train = sliding_windows(Train, seq_length)
# 使用滑动窗口为测试数据创建特征和标签
x_test, y_test = sliding_windows(Test, seq_length)
# 将数据转化为torch张量
testX = Variable(torch.Tensor(np.array(x_test)))
testY = Variable(torch.Tensor(np.array(y_test)))
Step3 设置模型参数 及 定义RNN
# 设置模型参数
input_size = 1
hidden_size = 64
num_layers = 1
output_size = 1 class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(RNN, self).__init__() self.hidden_size = hidden_size # RNN层
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True) # 全连接层,用于输出
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 初始化隐状态
h0 = Variable(torch.zeros(num_layers, x.size(0), self.hidden_size)) # 前向传播RNN
out, _ = self.rnn(x, h0) # 解码RNN的最后一个隐藏层的输出
out = self.fc(out[:, -1, :]) return out
Step4 创建模型 和 训练模型
# 创建模型
rnn = RNN(input_size, hidden_size, num_layers, output_size)
# 定义损失函数和优化器
criterion = torch.nn.MSELoss() # 均方误差
optimizer = torch.optim.Adam(rnn.parameters(), lr=0.01) # Adam优化器
# 将数据转化为torch张量
trainX = Variable(torch.Tensor(np.array(x_train)))
trainY = Variable(torch.Tensor(np.array(y_train)))
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
outputs = rnn(trainX)
optimizer.zero_grad() # 计算损失
loss = criterion(outputs, trainY)
loss.backward() optimizer.step()
if epoch % 10 == 0:
print("Epoch: %d, loss: %1.5f" % (epoch, loss.item()))
这个案例的数据集很小,也不涉及感知类的例如图片、音频或视频之类的,所以我们直接在CPU上做训练即可。打印出来的每一轮的损失为:
Epoch: 0, loss: 0.45516
Epoch: 10, loss: 0.02038
Epoch: 20, loss: 0.00982
Epoch: 30, loss: 0.00167
Epoch: 40, loss: 0.00174
Epoch: 50, loss: 0.00089
Epoch: 60, loss: 0.00058
Epoch: 70, loss: 0.00056
Epoch: 80, loss: 0.00052
Epoch: 90, loss: 0.00049
Step5 测试模型
# 使用训练好的模型进行预测
rnn.eval() # 设置模型为评估模式
test_outputs = rnn(testX)
# 将预测结果逆归一化
test_outputs = test_outputs.data.numpy()
test_outputs = Scaler.inverse_transform(test_outputs) # 逆归一化
# 真实测试标签逆归一化
y_test_actual = Scaler.inverse_transform(y_test)
# 输出预测和真实结果
for i in range(len(y_test)):
print(f"Date: {df_app['2020-10-01':].index[i+seq_length]}, Actual Activation: {y_test_actual[i][0]}, Predicted Activation: {test_outputs[i][0]}")
打印出来的真实值 和 预测值如下:
Date: 2020-10-05 00:00:00, Actual Activation: 923.0, Predicted Activation: 885.0889282226562
Date: 2020-10-06 00:00:00, Actual Activation: 919.0000000000001, Predicted Activation: 893.8333129882812
Date: 2020-10-07 00:00:00, Actual Activation: 915.0, Predicted Activation: 898.3600463867188
Date: 2020-10-08 00:00:00, Actual Activation: 910.0000000000001, Predicted Activation: 896.8088989257812
Date: 2020-10-09 00:00:00, Actual Activation: 905.0000000000001, Predicted Activation: 895.2501220703125
Date: 2020-10-10 00:00:00, Actual Activation: 901.0, Predicted Activation: 891.626953125
Date: 2020-10-11 00:00:00, Actual Activation: 913.0000000000001, Predicted Activation: 888.2245483398438
Date: 2020-10-12 00:00:00, Actual Activation: 900.0, Predicted Activation: 890.2631225585938
Date: 2020-10-13 00:00:00, Actual Activation: 888.0000000000001, Predicted Activation: 885.708984375
Date: 2020-10-14 00:00:00, Actual Activation: 883.0, Predicted Activation: 880.345458984375
Date: 2020-10-15 00:00:00, Actual Activation: 861.0, Predicted Activation: 878.3155517578125
Date: 2020-10-16 00:00:00, Actual Activation: 844.0, Predicted Activation: 865.739013671875
Date: 2020-10-17 00:00:00, Actual Activation: 837.0, Predicted Activation: 853.5955810546875
Date: 2020-10-18 00:00:00, Actual Activation: 841.0, Predicted Activation: 845.1204223632812
Date: 2020-10-19 00:00:00, Actual Activation: 821.0, Predicted Activation: 838.4027709960938
Date: 2020-10-20 00:00:00, Actual Activation: 843.0, Predicted Activation: 826.8444213867188
Date: 2020-10-21 00:00:00, Actual Activation: 857.0, Predicted Activation: 830.8392333984375
Date: 2020-10-22 00:00:00, Actual Activation: 861.0, Predicted Activation: 837.3353881835938
Date: 2020-10-23 00:00:00, Actual Activation: 858.0, Predicted Activation: 838.6307983398438
Date: 2020-10-24 00:00:00, Actual Activation: 832.0, Predicted Activation: 845.0518798828125
Date: 2020-10-25 00:00:00, Actual Activation: 811.0, Predicted Activation: 839.138427734375
Date: 2020-10-26 00:00:00, Actual Activation: 807.0, Predicted Activation: 828.6616821289062
Date: 2020-10-27 00:00:00, Actual Activation: 803.0, Predicted Activation: 820.3754272460938
Date: 2020-10-28 00:00:00, Actual Activation: 821.0, Predicted Activation: 809.3426513671875
Date: 2020-10-29 00:00:00, Actual Activation: 838.0, Predicted Activation: 809.6136474609375
...Date: 2021-01-22 00:00:00, Actual Activation: 925.0000000000001, Predicted Activation: 897.9528198242188
Date: 2021-01-23 00:00:00, Actual Activation: 926.0, Predicted Activation: 898.5119018554688
Date: 2021-01-24 00:00:00, Actual Activation: 920.0, Predicted Activation: 899.7281494140625
Date: 2021-01-25 00:00:00, Actual Activation: 932.0, Predicted Activation: 899.1580200195312
光这样看不太直观,绘制一个对比图:
# 定义绘图函数
def plot_predictions(test,predicted):
plt.plot(test, color='red',label='Real Count') #真值
plt.plot(predicted, color='blue',label='Predicted Count') #预测值
plt.title('Flower App Activation Prediction') #图题
plt.xlabel('Time') #X轴时间
plt.ylabel('Flower App Activation Count') #Y轴激活数
plt.legend() #图例
plt.show() #绘图
plot_predictions(y_test_actual,test_outputs) #绘图
绘制出来的对比图如下所示:

可以看到,预测值和真实值还是存在一定的差距。
Step6 计算性能
这里,我们计算一下MSE损失值 和 R平方分数:
import math #导入数学函数
from sklearn.metrics import mean_squared_error def return_rmse(test,predicted): #定义均方损失函数
rmse = math.sqrt(mean_squared_error(test, predicted)) #均方损失
print("MSE损失值 {}".format(rmse))
return_rmse(y_test_actual, test_outputs)
MSE损失值 25.51237936695477
from sklearn.metrics import r2_score r2 = r2_score(y_test_actual, test_outputs)
print(f"R2 Score: {r2}")
R2 Score: 0.6570994936886689
小结
本文介绍了RNN循环神经网络的基本概念 和 各种神经网络(DNN、CNN、RNN)的对比,最后介绍了如何基于RNN来做时序预测的案例。
推荐学习
黄佳,《AI应用实战课》(课程)

黄佳,《图解GPT:大模型是如何构建的》(图书)
黄佳,《动手做AI Agent》(图书)

AI应用实战课学习总结(11)用RNN做时序预测的更多相关文章
- DDD实战课--学习笔记
目录 学好了DDD,你能做什么? 领域驱动设计:微服务设计为什么要选择DDD? 领域.子域.核心域.通用域和支撑域:傻傻分不清? 限界上下文:定义领域边界的利器 实体和值对象:从领域模型的基础单元看系 ...
- 《即时消息技术剖析与实战》学习笔记11——IM系统如何保证服务高可用:流量控制和熔断机制
IM 系统的不可用主要有以下两个原因: 一是无法预测突发流量,即使进行了服务拆分.自动扩容,但流量增长过快时,服务已经不可用了: 二是业务中依赖的这些接口.资源不可用或变慢时,比如发消息可能需要依赖& ...
- 《Angular4从入门到实战》学习笔记
<Angular4从入门到实战>学习笔记 腾讯课堂:米斯特吴 视频讲座 二〇一九年二月十三日星期三14时14分 What Is Angular?(简介) 前端最流行的主流JavaScrip ...
- Python第八课学习
Python第八课学习 www.cnblogs.com/resn/p/5800922.html 1 Ubuntu学习 根 / /: 所有目录都在 /boot : boot配置文件,内核和其他 linu ...
- AI面试必备/深度学习100问1-50题答案解析
AI面试必备/深度学习100问1-50题答案解析 2018年09月04日 15:42:07 刀客123 阅读数 2020更多 分类专栏: 机器学习 转载:https://blog.csdn.net ...
- JavaEE精英进阶课学习笔记《博学谷》
JavaEE精英进阶课学习笔记<博学谷> 第1章 亿可控系统分析与设计 学习目标 了解物联网应用领域及发展现状 能够说出亿可控的核心功能 能够画出亿可控的系统架构图 能够完成亿可控环境的准 ...
- Ext.Net学习笔记11:Ext.Net GridPanel的用法
Ext.Net学习笔记11:Ext.Net GridPanel的用法 GridPanel是用来显示数据的表格,与ASP.NET中的GridView类似. GridPanel用法 直接看代码: < ...
- [AI开发]将深度学习技术应用到实际项目
本文介绍如何将基于深度学习的目标检测算法应用到具体的项目开发中,体现深度学习技术在实际生产中的价值,算是AI算法的一个落地实现.本文算法部分可以参见前面几篇博客: [AI开发]Python+Tenso ...
- SQL反模式学习笔记11 限定列的有效值
目标:限定列的有效值,将一列的有效字段值约束在一个固定的集合中.类似于数据字典. 反模式:在列定义上指定可选值 1. 对某一列定义一个检查约束项,这个约束不允许往列中插入或者更新任何会导致约束失败的值 ...
- Python第十课学习
Python第十课学习 www.cnblogs.com/yuanchenqi/articles/5828233.html 函数: 1 减少代码的重复 2 更易扩展,弹性更强:便于日后文件功能的修改 3 ...
随机推荐
- 阿里云平台OSS对象存储
OSS即"OpenStorageService",概念上没啥新意,就是本地存储搬到阿里云平台上了,单个存储对象大小可以达到5G,看了下阿里的OSS教程java版本, 使用原生js和 ...
- raw.githubusercontent.com 访问不了
访问 Github 中的 raw 文件内容时会跳转到 raw.githubusercontent.com 这个域名 但是访问不了. 解决办法 Windows 在 C:\Windows\System32 ...
- Springboot+MongoDB添加数据时会自带_class字段
_class字段作用 帮助映射子类,为了方便处理Pojo中存在继承的情况,增加系统的扩展性 去除_class字段 新增mongodb的配置类,配置mappingMongoConverter,配置类网上 ...
- ChirpStack 设备连通性测试极简工具
一.工具简介 你是否为调试 ChirpStack 设备数据连通性而烦恼?是否希望快速验证数据解析逻辑而无需复杂部署?这个 ChirpStack 数据连通性测试工具,算是一个极简解决方案! 无论是 Ch ...
- .NET 阻止关机机制以及关机前执行业务
本文主要介绍Windows在关闭时,如何正确.可靠的阻止系统关机以及关机前执行相应业务.因有一些场景需要在关机/重启前执行业务逻辑,确保下次开机时数据的一致性以及可靠性. 以下是实现这一需求的几种方法 ...
- RocketMQ的Producer是如何发送消息的
RocketMQ 的 Producer 发送消息过程涉及多个步骤,包括初始化.消息创建.发送方式选择 1.Producer初始化 首先,我们需要创建并初始化一个Producer示例 这段代码完成了以下 ...
- java基础之Stream流
一.使用Stream的目的:用于解决已有集合类库既有的弊端,只求关注[目的],不关注[方式],且其数据源:可以是集合,数组等 例子: public class NormalFilter { publi ...
- 基于Surprise和Flask构建个性化电影推荐系统:从算法到全栈实现
一.引言:推荐系统的魔法与现实意义 在Netflix每年节省10亿美元内容采购成本的背后,在YouTube占据用户80%观看时长的推荐算法中,推荐系统正悄然改变内容消费模式.本文将带您从零开始构建一个 ...
- Sentinel——控制台使用
简介 官网:https://sentinelguard.io/ 随着微服务的流行,服务和服务之间的稳定性变得越来越重要.Sentinel 是面向分布式.多语言异构化服务架构的流量治理组件,主要以流量为 ...
- 代码随想录第二十四天 | Leecode 93. 复原IP地址 、78. 子集、 90.子集II
Leecode 93. 复原IP地址 题目描述 有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 '.' 分隔. 例如:"0.1.2 ...