学习 TreeWalker api 并与普通遍历 DOM 方式进行比较
介绍 TreeWalker
TreeWalker 是 JavaScript 中用于遍历 DOM 树的一个接口。允许你以灵活的方式在 DOM 树中进行前向和后向遍历,包括访问父节点、子节点和兄弟节点。适用于处理复杂的 DOM 操作:在遍历过程中进行添加、删除或修改节点的操作,并继续遍历。
与普通的 for 循环 + querySelector 相比灵活性更高。执行速度方面,在 DOM 超过一定复杂度的情况下,TreeWalker 更快,后面会举例说明。
实践
创建 TreeWalker
可以使用 document.createTreeWalker 方法来创建一个 TreeWalker 对象。这个方法接受四个参数:
root:要遍历的根节点。whatToShow(可选):一个整数,表示要显示的节点类型。默认值是NodeFilter.SHOW_ALL,表示显示所有节点。filter(可选):一个NodeFilter对象,用于自定义过滤逻辑。entityReferenceExpansion(可选):一个布尔值,表示是否展开实体引用。这个参数在现代浏览器中通常被忽略,因为实体引用在HTML中很少使用
const walker = document.createTreeWalker(
document.body,//.root
NodeFilter.SHOW_ELEMENT,// whatToShow(可选)
null,// filter(可选)
false //entityReferenceExpansion(可选)
)
NodeFilter.SHOW_ELEMENT 表示显示元素节点。
节点类型
NodeFilter 有 12 种节点类型,和 Node 接口的节点类型一一对应;
| NodeFilter | Node.prototype |
|---|---|
| SHOW_ELEMENT:显示元素节点。 | 1: ELEMENT_NODE |
| SHOW_ATTRIBUTE:显示属性节点(在HTML 中不常用)。 | 2: ATTRIBUTE_NODE |
| SHOW_TEXT:显示文本节点。 | 3:TEXT_NODE |
| SHOW_CDATA_SECTION:显示CDATA 节点(在HTML 中不常用)。 | 4:CDATA_SECTION_NODE |
| SHOW_ENTITY_REFERENCE:显示实体引用节点(在HTML 中不常用)。 | 5: ENTITY_REFERENCE_NODE |
| SHOW_ENTITY:显示实体节点(在HTML 中不常用)。 | 6 : ENTITY_NODE |
| SHOW_PROCESSING_INSTRUCTION:显示处理指令节点。 | 7: PROCESSING_INSTRUCTION_NODE |
| SHOW_COMMENT:显示注释节点。 | 8:COMMENT_NODE |
| SHOW_DOCUMENT:显示文档节点。 | 9:DOCUMENT_NODE |
| SHOW_DOCUMENT_TYPE:显示文档类型节点。 | 10: DOCUMENT_TYPE_NODE |
| SHOW_DOCUMENT_FRAGMENT:显示文档片段节点。 | 11 : DOCUMENT_FRAGMENT_NODE |
| SHOW_NOTATION:显示符号节点(在HTML 中不常用)。 | 12 : NOTATION_NDE |
NodeFilter.SHOW_ALL 表示显示所有类型节点,这和遍历节点的 childNodes 一样,childNodes 会把该节点下的所有类型的子节点遍历出来。而节点的 children 就只遍历元素节点。
自定义过滤器
可以通过传递一个 NodeFilter 对象来实现自定义的过滤逻辑。NodeFilter 对象有一个 acceptNode 方法,该方法返回一个常量来决定是否接受节点:
- NodeFilter.FILTER_ACCEPT:接受节点。
- NodeFilter.FILTER_REJECT:拒绝节点及其子节点。
- NodeFilter.FILTER_SKIP:跳过节点,但继续遍历其子节点。
const filter = {
acceptNode: function (node){
if (node.tagName=== "DIV"){
return NodeFilter.FILTER_ACCEPT;
}else {
return NodeFilter.FILTER_SKIP;
}
},
};
const walker = document.createTreeWalker(
document.body,
NodeFilter.SHOW_ELEMENT,
filter,//只遍历标签名是div的元素
false
);
let node;
while ((node = walker.nextNode())!== nu11){
console.log(node);
遍历节点
TreeWalker 提供了多种方法来遍历节点:
nextNode():移动到下一个节点,如果没有更多节点则返回 null。
- previousNode():移动到上一个节点,如果没有更多节点则返回 null。
- parentNode():移动到当前节点的父节点,如果没有父节点则返回 null。
- firstChild():移动到当前节点的第一个子节点,如果没有子节点则返回 null。
- lastChild():移动到当前节点的最后一个子节点,如果没有子节点则返回 null。
- nextSibling():移动到当前节点的下一个兄弟节点,如果没有更多兄弟节点则返回 null。
- previousSibling():移动到当前节点的上一个兄弟节点,如果没有更多兄弟节点则返回 null。
需要注意的是,nextNode()是深度优先遍历。
当前节点
TreeWalker 对象有一个 currentNode 属性,表示当前遍历到的节点,这个属性是可读写的,可以通过这个属性来获取或设置当前节点。
console.log(walker.currentNode);// 输出当前节点
//设置当前节点
walker.currentNode = document.getElementById("id");
console.log(walker.currentNode);//输出新设置的当前节点
实践并和 querySelector() 比较
querySelector() 是一个选择器通过传入静态的 css 选择器获取元素。
而 TreeWalker 会创建一个对象,适应于进行复杂的 DOM 操作的场景,在遍历过程中支持添加、删除或修改节点,或者动态改变遍历方向,很灵活。
这两个本来就是适用于不同场景,获取元素基本上还是用querySelector(),不过涉及到复杂循环遍历时就可以考虑 TreeWalker 了。
这里我测试了一下,在怎样的复杂程度下,TreeWalker 遍历 会比用 for 循环 + querySelector() 遍历执行速度上更快。
经过不断测试,在循环嵌套遍历 1000 个元素时,并且对每个元素进行添加删除子元素的操作,此时使用 TreeWalker 遍历执行速度更快。这 1000 个数量并不是一个可以判定复杂程度确定的值,只是在当前浏览器下测试出来的一个大概的数量。
因为这还与对元素操作复杂度有关,与浏览器执行性能也有关,随着浏览器不断更新迭代,后面应该只会越来越快。
下面整理下测试过程,在页面中创建了一个 id是root的元素
<div id="root"></div>
<style>
#root>div{margin-bottom: 20px;}
.ColDiv{display: flex;gap: 10px;}
</style>
然后给 root 创建1000个子元素,这里使用了三重 for 循环js
function createEl(el) {
var fragment = document.createDocumentFragment();
for (var i = 0; i < 10; i++) {
var divBox = document.createElement("div");
var innerHTML = `Row${i}`;
for (let j = 0; j < 10; j++) {
innerHTML += `<div><div class="ColDiv">Col${j}=>`;
for (let k = 0; k < 10; k++) {
innerHTML += `<div>children${k}</div>`;
}
innerHTML += `</div>`;
}
divBox.innerHTML = innerHTML;
fragment.appendChild(divBox);
el.appendChild(fragment);
}
}
createEl(document.getElementById("root"));
渲染到页面上就是这样,截图没有全部截完:

然后用循环 + querySelector 遍历 root,这里为了让遍历复杂一点,添加了一个逻辑:当遍历到子节点是 children2 时,
给这个节点添加一个新的子节点,然后又删除它;最后计算执行时间;
const querySelectorTest = () => {
let root = document.querySelector("#root");
let children = root.children;
let len = children.length;
console.time("querySelector");
const tempFn = (list) => {
for (let i = 0; i < list.length; i++) {
let node = list[i];
if (node.textContent==="children2") {
//添加一个新的子节点
const newDiv = document.createElement("div");
newDiv.textContent = "New Item";
node.appendChild(newDiv);
console.log("Added new node:");
//删除添加的子节点
node.removeChild(newDiv);
}
if (node.children.length) {
tempFn(node.children);
}
}
}
tempFn(children);
console.timeEnd("querySelector");
}
然后同样的逻辑,用 TreeWalker 来遍历
const TreeWalkerTest = () => {
const walker = document.createTreeWalker(
document.getElementById("root"),
NodeFilter.SHOW_ELEMENT,
null,
false
);
console.time("treeWalker");
let node;
while ((node = walker.nextNode()) !== null) {
if (node.textContent === "children2") {
//添加一个新的子节点
const newDiv = document.createElement("div");
newDiv.textContent = "New Item";
node.appendChild(newDiv);
//移动到新添加的节点
let newNode = walker.nextNode();
console.log("Added new node:");
//删除一个节点前需要先移动到上一个节点 walker.previousNode(),这样才能顺利遍历下一个;
walker.previousNode();
newNode.parentNode.removeChild(newNode);
}
}
console.timeEnd("treeWalker");
}
这里需要注意的是,删除一个节点前需要先移动到上一个节点 walker.previousNode(),这样才能顺利遍历下一个;
同时测试这两个函数
for (let i = 0; i < 10; i++) {
TreeWalkerTest()
querySelectorTest()
}
结果如下:
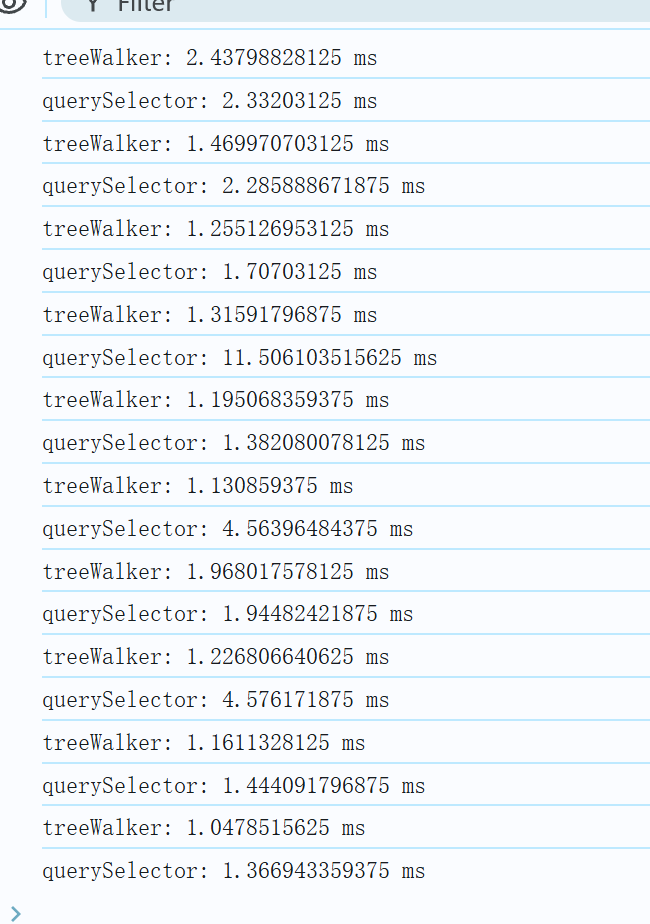
可以看到多次运行测试函数,TreeWalker 执行速度大多数都更快;
然后修改 root 子元素数量试试,从1000改为100,测试函数的逻辑不变;
function createEl(el) {
var fragment = document.createDocumentFragment();
// for (var i = 0; i < 10; i++) {
var divBox = document.createElement("div");
var innerHTML = `Row`;
for (let j = 0; j < 10; j++) {
innerHTML += `<div><div class="ColDiv">Col${j}=>`;
for (let k = 0; k < 10; k++) {
innerHTML += `<div>children${k}</div>`;
}
innerHTML += `</div>`;
}
divBox.innerHTML = innerHTML;
fragment.appendChild(divBox);
el.appendChild(fragment);
// }
}
再来测试下:
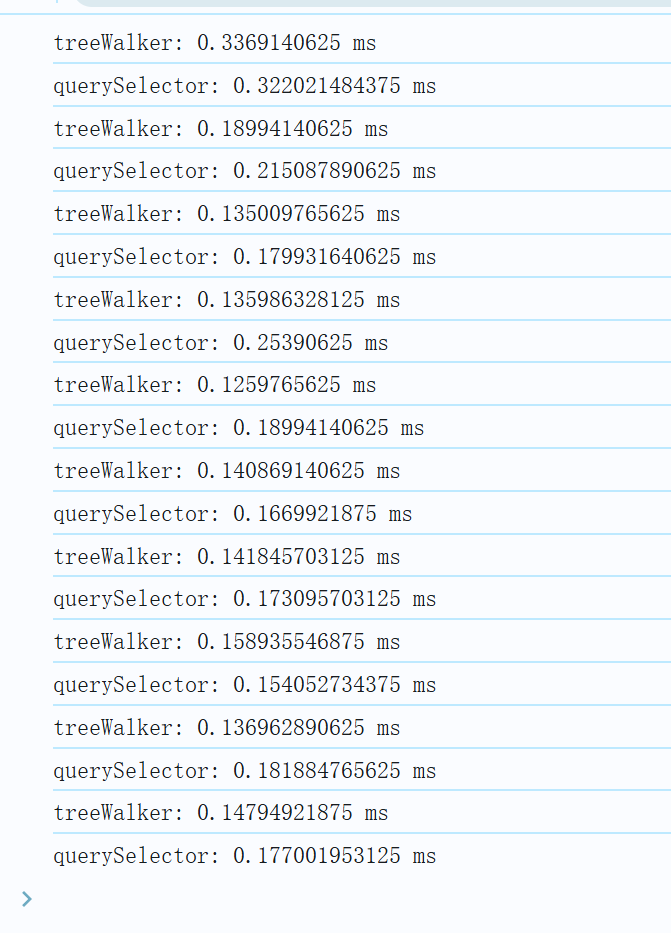
TreeWalker 执行速度依然大多数都更快;
再来修改下测试函数的逻辑,只遍历,不进行添加删除节点的操作
const querySelectorTest = () => {
let root = document.querySelector("#root");
let children = root.children;
let len = children.length;
console.time("querySelector");
const tempFn = (list) => {
for (let i = 0; i < list.length; i++) {
let node = list[i];
// if (node.textContent === "children2") {
// //添加一个新的子节点
// const newDiv = document.createElement("div");
// newDiv.textContent = "New Item";
// node.appendChild(newDiv);
// // console.log("Added new node:");
// //删除添加的子节点
// node.removeChild(newDiv);
// }
if (node.children.length) {
tempFn(node.children);
}
}
}
tempFn(children);
console.timeEnd("querySelector");
}
const TreeWalkerTest = () => {
const walker = document.createTreeWalker(
document.getElementById("root"),
NodeFilter.SHOW_ELEMENT,
null,
false
);
console.time("treeWalker");
let node;
while ((node = walker.nextNode()) !== null) {
// if (node.textContent === "children2") {
// //添加一个新的子节点
// const newDiv = document.createElement("div");
// newDiv.textContent = "New Item";
// node.appendChild(newDiv);
// //移动到新添加的节点
// let newNode = walker.nextNode();
// // console.log("Added new node:");
// //删除一个节点
// walker.previousNode();
// newNode.parentNode.removeChild(newNode);
// }
}
console.timeEnd("treeWalker");
}
for (let i = 0; i < 10; i++) {
TreeWalkerTest()
querySelectorTest()
}
结果如下:
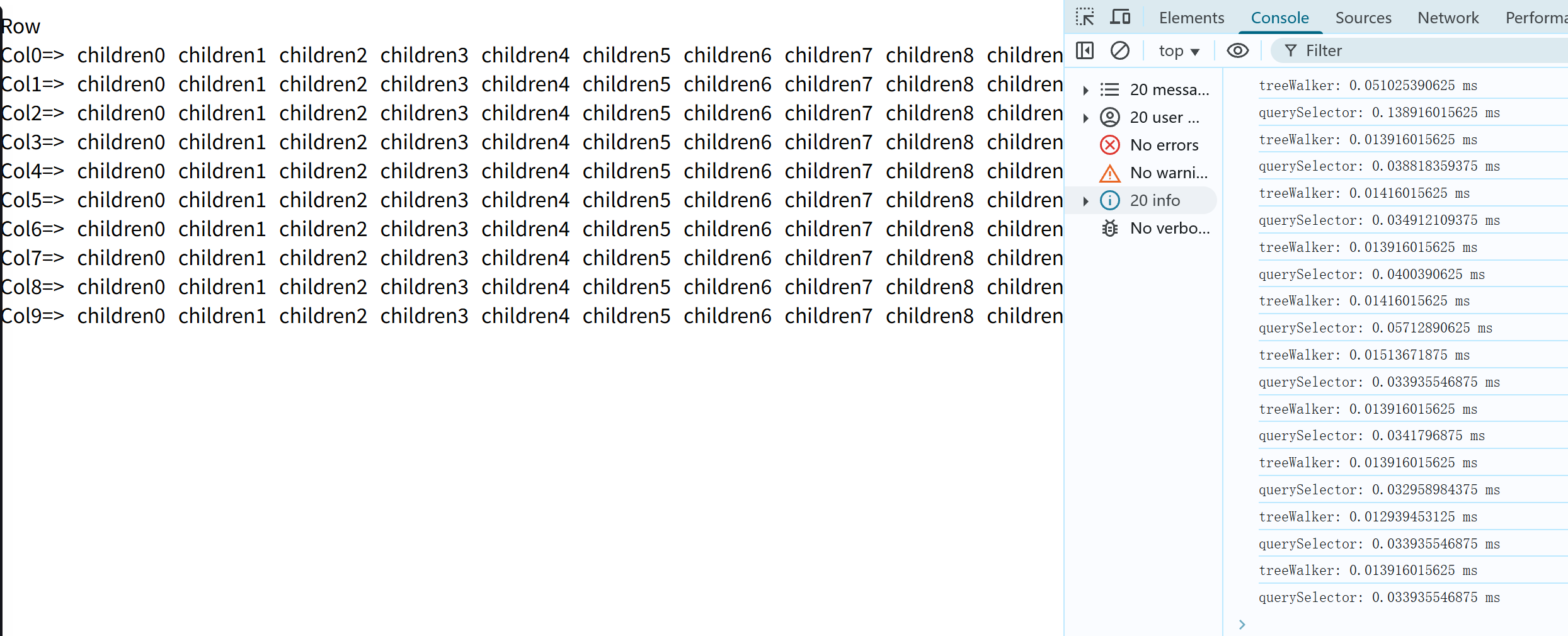
TreeWalker 执行速度还是大多数都更快;
但其实这里测试意义不大了,这个例子实际上是在测试 while 循坏 和 for 循环+递归 的差异了;单论循环而言, while 循环总是最快的;
那么接下来把 root 子节点打平,不再嵌套了,也就是遍历一维数组,然后把 querySelectorTest 的 for 循环改为 while 循环,再来试一下
function createEl(el, len) {
var fragment = document.createDocumentFragment();
for (var i = 0; i < 10000; i++) {
var divBox = document.createElement("div");
divBox.innerHTML = "Row" + i;
fragment.appendChild(divBox);
}
el.appendChild(fragment);
}
const TreeWalkerTest = () => {
const walker = document.createTreeWalker(
document.getElementById("root"),
NodeFilter.SHOW_ELEMENT,
null,
false
);
console.time("treeWalker");
let node;
while ((node = walker.nextNode()) !== null) {}
console.timeEnd("treeWalker");
};
const querySelectorTest = () => {
let root = document.querySelector("#root");
let children = root.children;
let len = children.length;
console.time("querySelector");
let i = 0;
while (i++ < len) { }
console.timeEnd("querySelector");
}
这样就是普通的两个 while 循环对比了,此时 TreeWalker 就没有优势了。
总结起来,在不复杂的场景下,遍历的元素数量不多或者嵌套层级不深,或者对遍历的元素没有进行复杂的DOM操作,使用普通 for 循环,while 循环操作元素始终比 TreeWalker 快,
反之可以考虑使用 TreeWalker。
学习 TreeWalker api 并与普通遍历 DOM 方式进行比较的更多相关文章
- iOS 学习 - 6.Objective-C中的各种遍历(迭代)方式
说明:转自文顶顶 一.使用 for 循环 要遍历字典.数组或者是集合,for 循环是最简单也用的比较多的方法 -(void)iteratorWithFor { //////////处理数组////// ...
- javaweb学习总结十(xml解析<SAX以及DOM方式>)
一:XML解析技术 一般我们使用sun公司或者开源组织开发的工具包解析xml效率比较高. 1:jaxp解析xml,jaxp是sun公司开发的解析xml工具包 2:jaxp解析xml代码如下 a:获取d ...
- JQuery学习笔记(三)遍历 DOM
遍历 DOM jQuery 提供了多种遍历 DOM 的方法.遍历方法中最大的种类是树遍历(tree-traversal). 向上父节点parent,向下子节点child,同胞next和pre 缩写搜索 ...
- 先序遍历DOM树的5种方法
DOM树由文档中的所有节点(元素节点.文本节点.注释节点等)所构成的一个树结构,DOM树的解析和构建是浏览器要实现的关键功能.既然DOM树是一个树结构,那么我们就可以使用遍历树结构的相关方法来对DOM ...
- canvas学习之API整理笔记(二)
前面我整理过一篇文章canvas学习之API整理笔记(一),从这篇文章我们已经可以基本了解到常用绘图的API.简单的变换和动画.而本篇文章的主要内容包括高级动画.像素操作.性能优化等知识点,讲解每个知 ...
- 学习FFmpeg API
ffmpeg是编解码的利器,用了很久,以前看过dranger 的教程,非常精彩,受益颇多,是学习ffmpeg api很好的材料.可惜的是其针对的ffmpeg版本已经比较老了,而ffmpeg的更新又很快 ...
- 【转】学习FFmpeg API – 解码视频
ffmpeg是编解码的利器,用了很久,以前看过dranger 的教程,非常精彩,受益颇多,是学习ffmpeg api很好的材料.可惜的是其针对的ffmpeg版本已经比较老了,而ffmpeg的更新又很快 ...
- jQuery向上遍历DOM树之parents(),parent(),closest()之间的区别
http://www.poluoluo.com/jzxy/201312/253059.html 在这个sprint中,因为要写前端UI,所以用到了jQuery,但是jQuery在向上遍历DOM树的AP ...
- 不要遍历dom
function selectProvince() { $.ajax( { type: "post", url: "/province/getStrType", ...
- salesforce 零基础学习(三十二)通过Streams和DOM方式读写XML
有的时候我们需要对XML进行读写操作,常用的XML操作主要有Streams和DOM方式. 一.Streams方式 Streams常用到的类主要有两个XmlStreamReader 以及XmlStrea ...
随机推荐
- 实现低PE策略的回测
回测的基本流程 首先需要声明下,此回测属于日间回测,即当天收盘后对交易信号进行检测,得到买入或卖出检测结果,然后由第二天开盘后根据前一天的检测结果完成交易. 其次要对账户进行除权除息处理.因为除权除息 ...
- File与IO流之File练习
创建文件夹,并在其中创建文件 package Java_test; import java.io.*; public class Test { public static void main(Stri ...
- 【2020.12.02提高组模拟】球员(player) 题解
[2020.12.02提高组模拟]球员(player) 题解 题意描述 基本的递推. ①所有运动员姓氏的长度必须不同. ②每个运动员的姓氏必须是长度比其长的所有其他运动员姓氏的连续子串 潜在的球员分成 ...
- python爬虫基本学习——函数
函数 概念:编写程序时,需要某块代码多次,为了提高编写效率和代码的重用,把具有独立功能的代码块组织为一个小模块,即函数. 代码练习 ''' #函数的定义 def printinfo(): print( ...
- K&R 语法 vs. ANSI C 语法
由于项目中使用了Bison,看到有个奇怪的C语言的语法,查了一下居然是要兼容早期的C标准 Bison 是什么? Bison 是一个 语法分析器生成器(parser generator),它用于根据 上 ...
- Linux配置/etc/resolv.conf详解
一.具体说明 /etc/resolv.conf是DNS客户机的配置文件,用于设置DNS服务器的IP地址及DNS域名,还包含了主机的域名搜索顺序.该文件是由域名解析器(resolver,一个根据主机名解 ...
- 世事洞明皆学问 — 如何理解 OB 4.x 版本中的日志流?
首先为大家推荐这个 OceanBase 开源负责人老纪的公众号 "老纪的技术唠嗑局",会持续更新和 #数据库.#AI.#技术架构 相关的各种技术内容.欢迎感兴趣的朋友们关注! 最近 ...
- sass ruby 中文
解决办法: 1.koala可视化编译工具, 找到安装目录里面sass-3.3.7模块下面的engine.rb文件,例如下面路径: C:\Program Files (x86)\Koala\rubyge ...
- .NET应用中的高效分布式同步解决方案
前言 在分布式系统中,多个线程.进程或服务之间常常需要并发访问共享资源,这就带来了数据同步与一致性的挑战.今天大姚给大家分享一个.NET应用中的高效分布式同步解决方案:DistributedLock. ...
- Blazor学习之旅 (14) Blazor WebAssembly
在上一篇我们学习了如何创建和使用Razor类库,这一篇我们了解下WebAssembly是什么,以及创建第一个Blazor WebAssembly应用. 什么是WebAssembly? WebAssem ...