StarRocks 如何在本地搭建存算分离集群
之前写过一篇 StarRocks 开发环境搭建踩坑指北之存算分离篇讲解如何在本地搭建一个可以 debug 的存算分离版本。
但最近在本地调试一个场景,需要 CN 节点是以集群的方式启动,我还是按照老方法通过 docker 启动 CN,然后 export 端口的方式让 FE 进行绑定。
比如用以下两个命令可以启动两个 CN 节点。
docker run -p 9060:9060 -p 8040:8040 -p 9050:9050 -p 8060:8060 -p 9070:9070 -itd --rm --name cn -e "TZ=Asia/Shanghai" starrocks/cn-ubuntu:3.5.2
docker run -p 9061:9060 -p 8041:8040 -p 9051:9050 -p 8061:8060 -p 9071:9070 -itd --rm --name cn2 -e "TZ=Asia/Shanghai" starrocks/cn-ubuntu:3.5.2
然后按照之前的方式在 FE 中手动绑定这两个节点:
ALTER SYSTEM ADD COMPUTE NODE "127.0.0.1:9050";
ALTER SYSTEM ADD COMPUTE NODE "127.0.0.1:9051";
show compute nodes;

此时会出现新增的第二个节点的状态有问题,比如 metrics 取不到,workerId 是-1(-1 代表节点创建失败了,默认值是 -1)
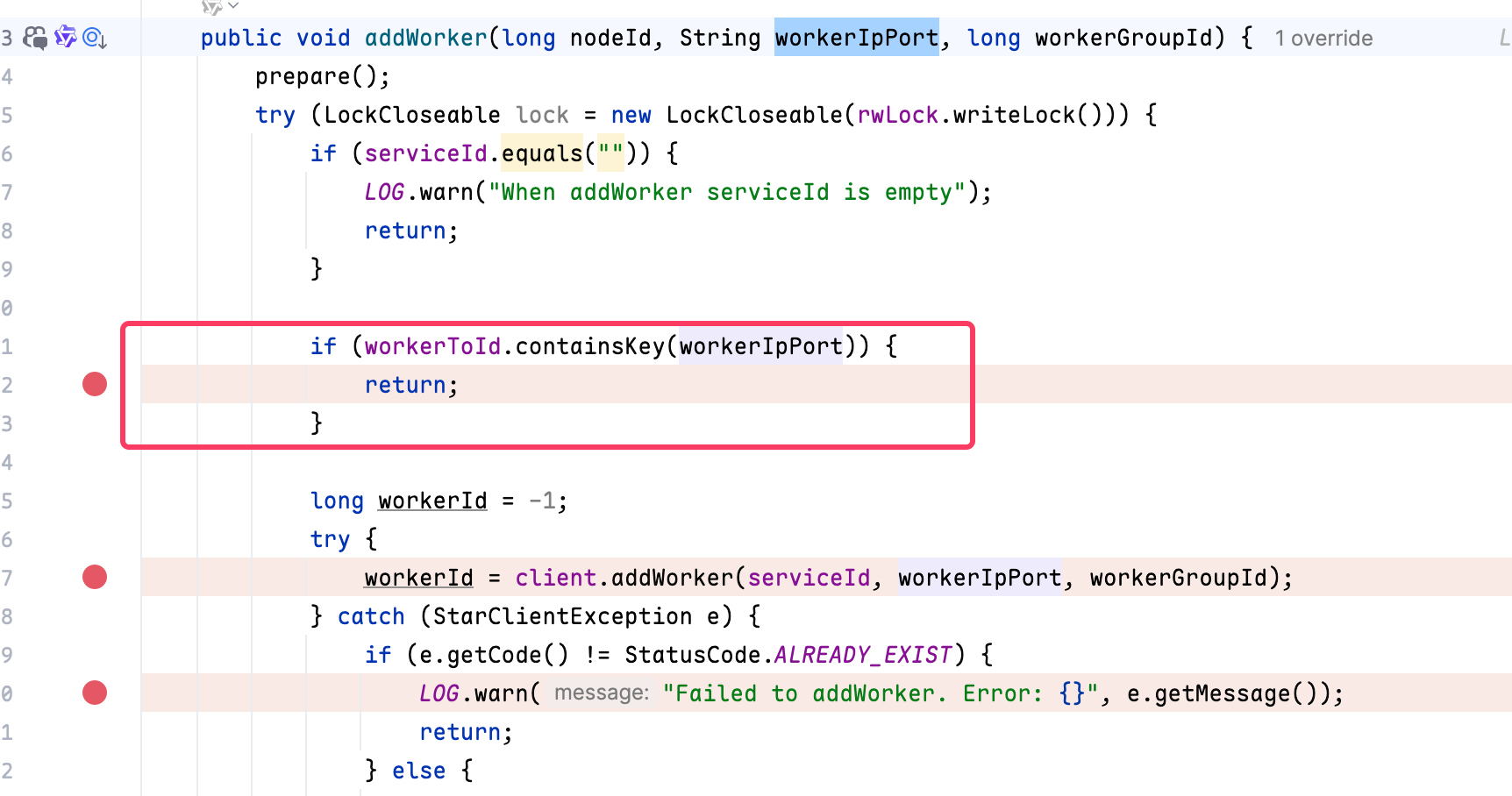

经过 debug 发现是在添加节点的时候,由于生成的 workerIpPort 与上一个节点相同(127.0.0.1:9060) 从而导致这个节点被跳过了。
也就是说我这两个 CN 节点不能是相同的 IP(用不同的端口来区分)。
解决这个问题有以下几个办法:
- 再找一个台机器来跑 CN2 节点
- 启动一个虚拟机来跑 CN2 节点
- 使用 docker compose 来启动 CN 集群,会在集群内自动分配不同的 IP
- 利用 Docker Bridge 创建一个虚拟网络,由他来分配 IP
第一种方案直接 Pass 了,我手上没有多余的设备。
第二种方案倒是可以直接用 OrbStack 启动一个 VM,但是还不如后面的 docker 来的轻量,此外还需要我安装运行环境,也 pass 了。
第三种方案看似可行,但也比较繁琐,由于 CN 给 docker compose 管理了,FE 要和 CN 网络打通也得在 docker compose 里运行,这样我 Debug 就不方便了,更别提如果需要频繁修改源码的情况。
甚至每次修改代码后都得重新打包上传镜像,以及开启 remote debug,非常麻烦。
这么看来就第四种方案最为合适了。
使用 Docker Bridge 网络
我们可以使用 Docker Bridge 创建一个虚拟网络,使用这个虚拟网络启动的镜像会自动分配自定义范围的 IP;同时本地启动的 FE 也能直接访问。
docker network create --subnet=172.18.0.0/16 --gateway=172.18.0.1 my_custom_net
首先用 docker 创建一个 network。
--subnet=172.18.0.0/16: 定义网络的 IP 地址范围。这里我们使用了172.18.x.x这个私有网段。--gateway=172.18.0.1: 指定这个网络的网关地址。
之后我们就可以使用这个虚拟网络来启动容器了。
docker run --ip 172.18.0.20 --net my_custom_net -p 9060:9060 -p 8040:8040 -p 9050:9050 -p 8060:8060 -p 9070:9070 -itd --rm --name cn -e "TZ=Asia/Shanghai" starrocks/cn-ubuntu:3.5.2
docker run --ip 172.18.0.30 --net my_custom_net -p 9061:9060 -p 8041:8040 -p 9051:9050 -p 8061:8060 -p 9071:9070 -itd --rm --name cn2 -e "TZ=Asia/Shanghai" starrocks/cn-ubuntu:3.5.2
这样这两个容器就会被分配不同的 IP,并且网络和宿主机也是互通的。
需要注意的是这里的子网尽量选择 172.16.0.0 到 172.31.255.255 这个 IP 段,192.168.0.0 到 192.168.255.255 这个范围段很有可能家里或公司的路由器占用了。
而这里的网关 --gateway=172.18.0.1地址也需要在我们自定义的 IP 范围里。
同时我们也不需要在这两个容器内为 CN 指定 priority_networks 参数了。
同理 minio 也得使用这个虚拟网络启动:
docker run -d --rm --name minio \
--ip 172.18.0.10 \
--net my_custom_net \
-e MINIO_ROOT_USER=miniouser \
-e MINIO_ROOT_PASSWORD=miniopassword \
-p 9001:9001 \
-p 9000:9000 \
--entrypoint sh \
minio/minio:latest \
-c 'mkdir -p /minio_data/starrocks && minio server /minio_data --console-address ":9001"'
设置 token 的时候也要指定对应的 IP:
mc alias set myminio http://172.18.0.10:9000 miniouser miniopassword; mc admin user svcacct add --access-key AAAAAAAAAAAAAAAAAAAA --secret-key BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB myminio miniouser
当 CN 和 minio 都启动之后,我们在 FE 里手动绑定这两个 CN 节点:
ALTER SYSTEM ADD COMPUTE NODE "172.18.0.20:9050";
ALTER SYSTEM ADD COMPUTE NODE "172.18.0.30:9050"
这样这两个节点就可以绑定成功了。
Blog
StarRocks 如何在本地搭建存算分离集群的更多相关文章
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- 存算分离实践:JuiceFS 在中国电信日均 PB 级数据场景的应用
01- 大数据运营的挑战 & 升级思考 大数据运营面临的挑战 中国电信大数据集群每日数据量庞大,单个业务单日量级可达到 PB 级别,且存在大量过期数据(冷数据).冗余数据,存储压力大:每个省公 ...
- 从 Hadoop 到云原生, 大数据平台如何做存算分离
Hadoop 的诞生改变了企业对数据的存储.处理和分析的过程,加速了大数据的发展,受到广泛的应用,给整个行业带来了变革意义的改变:随着云计算时代的到来, 存算分离的架构受到青睐,企业开开始对 Hado ...
- 如何使用XAMPP本地搭建一个属于你自己的网站
你好,从今天开始,我将为大家带来一些我学习SEO和建站的免费教程,今天为大家带来的是如何用XAMPP搭建一个属于你自己的网站.来到这里,可以说很多在百度上已经过时了的资料需要总结的资料这里都有,你只要 ...
- Hexo搭建博客教程(1) - 安装环境与本地搭建
前言 搭建个人博客一般有两种选择,一个是使用WordPress,但是需要将博客搭建在服务器上,不过搭建好后写文章方便,适合没有程序基础的人使用.另一个是使用Hexo,相对简洁高效,不需要服务器,既可以 ...
- Jekyll本地搭建开发环境以及Github部署流程
转载自: http://www.jianshu.com/p/f37a96f83d51 前言 博客从wordpres迁移到Jekyll上来了,整个过程还是很顺利的.Jekyll是什么?它是一个简单静态博 ...
- 存算分离下写性能提升10倍以上,EMR Spark引擎是如何做到的?
引言 随着大数据技术架构的演进,存储与计算分离的架构能更好的满足用户对降低数据存储成本,按需调度计算资源的诉求,正在成为越来越多人的选择.相较 HDFS,数据存储在对象存储上可以节约存储成本,但与此 ...
- 腾讯云 CHDFS — 云端大数据存算分离的基石
随着网络性能提升,云端计算架构逐步向存算分离转变,AWS Aurora 率先在数据库领域实现了这个转变,大数据计算领域也迅速朝此方向演化. 存算分离在云端有明显优势,不但可以充分发挥弹性计算的灵活,同 ...
- ClickHouse 存算分离架构探索
背景 ClickHouse 作为开源 OLAP 引擎,因其出色的性能表现在大数据生态中得到了广泛的应用.区别于 Hadoop 生态组件通常依赖 HDFS 作为底层的数据存储,ClickHouse 使用 ...
随机推荐
- 电脑tips #持续更新ing
记录日常get 1. Esc+ Fn 打开与锁住F1到F12功能键们 2. 没有找到支持的视频格式和MIME类型 场景:发生在网页嵌入的视频中 原因及解决:--网速不好,重新刷新解决 3. 问题描述: ...
- Prompt 攻击与防范:大语言模型安全的新挑战
随着大语言模型(LLM)在企业服务.智能助手.搜索增强等领域的广泛应用,围绕其"Prompt"机制的安全问题也逐渐引起关注.其中最具代表性的,就是所谓的 Prompt Inject ...
- odoo18运行报错问题解决
File "/Users/melon/.pyenv/versions/3.11.9/lib/python3.11/code.py", line 90, in runcode exe ...
- Spring Boot项目基于POI框架导出Excel表格
1. 依赖 我的项目是基于Spring Boot的,这里只贴出POI框架需要依赖的两个包,其他的都无所谓,只要能提供Controller让浏览器访问即可.在pom.xml配置文件中增加如下两个包 ...
- Spring 注解之@RequestBody和@PostMapping
@RequestBody的使用 注解@RequestBody用于接收前端传递给后端的.JSON对象的字符串,这些数据位于请求体中,适合处理的数据为非Content-Type: applicatio ...
- java XML字符串和json字符串互转
结果 原始 # 原始 {"head":{"opCode":"0202","bankCode":"0416000 ...
- Vue 学习笔记 [Part 4]
作者:故事我忘了¢个人微信公众号:程序猿的月光宝盒 目录 一. 组件化开发 1.1. 父子组件的访问 1.2. slot的使用 二. 前端模块化 2.1. 为什么要使用模块化 2.2. ES6中模块化 ...
- 关于Django项目集成Xadmin后,出现服务异常解决方案
Django项目集成Xadmin后,偶尔出现页面不能访问,重启服务也不行,如果是Nginx部署直接报504等错误. 解决方案: 在项目中的静态文件中找到:bootstrap-clockpicker.j ...
- Java 线程中断相关方法:interrupt() isInterrupted() interrupted()
interrupt() 方法只是改变中断状态而已,它不会中断一个正在运行的线程.如果线程被Object.wait, Thread.join和Thread.sleep三种方法之一阻塞,此时调用该线程的i ...
- android input
通常,从EditText中获取字符串很简单: EditText text = findViewById(R.id.textName); String name = text.getText ...