SparkRDD算子(transformations算子和actions算子)
RDD提供了两种类型的操作:transformation和action
1、所有的transformation都是采用的懒策略,如果只是将transformation提交是不会执行计算的,计算只有在action被提交的时候才被触发。
2、action操作:action是得到一个值,或者一个结果(直接将RDD cache到内存中)
transformations算子
actions算子

transformations算子
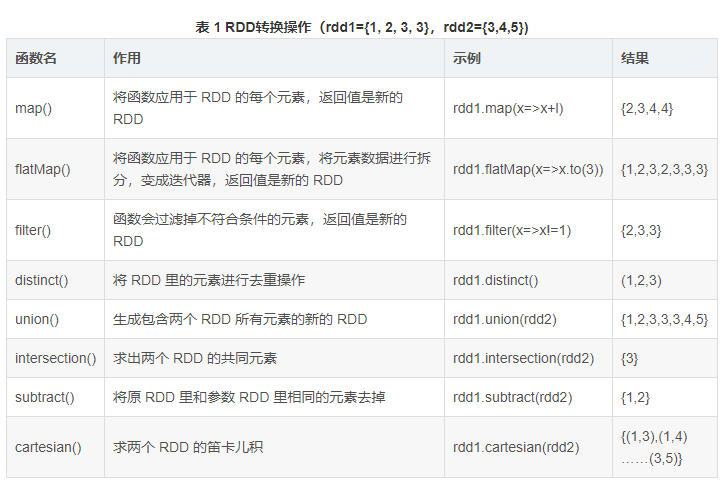
1、map算子
var listRDD = sc.makeRDD(1 to 10)
listRDD.map((_*2)).foreach(println)
// 输出结果: 2,4,6,8,10,12,14,16,18,20 (这里为了节省篇幅去掉了换行,后文亦同)
2、flatMap算子
flatMap(func)与map类似,但每一个输入的 item 会被映射成 0 个或多个输出的 items( *func* 返回类型需要为Seq`)
val list = List(List(1, 2), List(3), List(), List(4, 5))
sc.parallelize(list).flatMap(_.toList).map(_ * 10).foreach(println)
// 输出结果: 10,20,30,40,50(这里为了节省篇幅去掉了换行,后文亦同)
flatmap 流的扁平化,最终输出的数据类型为一维数组Array[String]。
被分割出来的每个数据都作为同一个数组中的相同类型的元素,最终全部被分割出来的数据都存储于同一个一维数组中。
结论:多行数据被分割后都存储到同一个一维数组Array[String]中。
flatMap 这个算子在日志分析中使用概率非常高,这里进行一下演示:拆分输入的每行数据为单个单词,并赋值为 1,代表出现一次,之后按照单词分组并统计其出现总次数,代码如下:
var list = List("hello scala","hello python")
sc.parallelize(list).flatMap(line=>line.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
// 输出结果:(scala,1)(python,1)(hello,2)(这里为了节省篇幅去掉了换行,后文亦同)
3、filter算子
var listRDD = sc.makeRDD(1 to 10) listRDD .filter(_%2==0).foreach(println)
// 输出结果: 2,4,6,8,10
4、sample(withReplacement, fraction, seed)算子
以指定的随机种子随机抽样出数量为fraction的数据,fraction表示抽取的数据占总数据的比例,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样,seed用于指定随机数生成器种子(步长)。
val rdd: RDD[String] = sc.makeRDD(Array("hello1","hello1","hello2","hello3","hello4","hello5","hello6","hello1","hello1","hello2","hello3"))
val sampleRDD: RDD[String] = rdd.sample(false,0.7)
sampleRDD.foreach(println)
//输出结果hello1 hello6 hello1 hello2 hello3 hello5 hello1 hello3
5、union(otherDataset)算子
对源RDD和参数RDD求并集后返回一个新的RDD
val rdd1 = sc.parallelize(1 to 5)
val rdd2 = sc.parallelize(5 to 10)
val rdd3 = rdd1.union(rdd2)
rdd3.collect().foreach(println)
//输出结果1 2 3 4 5 5 6 7 8 9 10
6、intersection(otherDataset)算子
对源RDD和参数RDD求交集后返回一个新的RDD
val rdd6 = sc.parallelize(1 to 7)
val rdd7 = sc.parallelize(5 to 10)
val rdd8 = rdd6.intersection(rdd7)
rdd8.collect().foreach(println)
//输出结果5 6 7
7、distinct([numPartitions]))算子
对源RDD进行去重后返回一个新的RDD。默认情况下,只有8个并行任务来操作,但是可以传入一个可选的numTasks参数改变它
val makeRDD: RDD[Int] = sc.makeRDD(Array(1,3,2,5,6,3,2,1))
val makedist: RDD[Int] = makeRDD.distinct() //不指定并行度
/**对RDD(指定并行度为2)
makeRDD.distinct(2)*/
makedist.collect().foreach(println)
//输出结果1 2 3 5 6
8、groupByKey([numPartitions])算子
groupByKey也是对每个key进行操作,但只生成一个sequence。
val words = Array("one","two","three","one","two","three")
val listRdd: RDD[(String, Int)] = sc.makeRDD(words).map(word => (word,1))
listRdd.collect().foreach(println)
//groupByKey算子
val group: RDD[(String, Iterable[Int])] = listRdd.groupByKey()
group.collect().foreach(println)
//输出结果(two,CompactBuffer(1, 1)) (one,CompactBuffer(1, 1)) (three,CompactBuffer(1, 1))
9、reduceByKey(func, [numPartitions])算子
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。分组和聚合一起干了
val words = Array("one","two","three","one","two","three")
val listRdd: RDD[(String, Int)] = sc.makeRDD(words).map(word => (word,1))
val reduceByKeyRDD: Array[(String, Int)] = listRdd.reduceByKey(_+_).collect()
//输出结果(two,2) (one,2) (three,2)
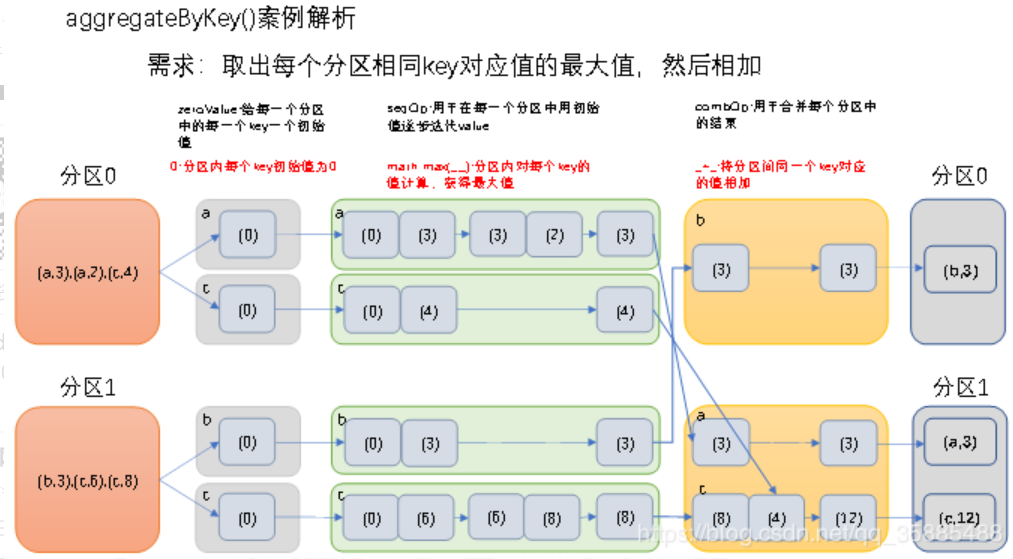
10、aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions])算子
参数描述:
(1)zeroValue:给每一个分区中的每一个key一个初始值;
(2)seqOp:函数用于在每一个分区中用初始值逐步迭代value;
(3)combOp:函数用于合并每个分区中的结果
在kv对的RDD中,,按key将value进行分组合并,合并时,将每个value和初始值作为seq函数的参数,进行计算,返回的结果作为一个新的kv对,然后再将结果按照key进行合并,最后将每个分组的value传递给combine函数进行计算(先将前两个value进行计算,将返回结果和下一个value传给combine函数,以此类推),将key与计算结果作为一个新的kv对输出。
val rdd = sc.parallelize(List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8)),2)
val aggregateByKeyRDD: RDD[(String, Int)] = rdd.aggregateByKey(0)(math.max(_,_),_+_)
aggregateByKeyRDD.collect().foreach(println)
//输出结果(b,3), (a,3), (c,12)
11、sortByKey([ascending], [numPartitions])
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
//根据key正序排
rdd.sortByKey(true).collect().foreach(println)
//倒序排序
rdd.sortByKey(false).collect().foreach(println)
//输出结果(1,dd)(2,bb)(3,aa)(6,cc) 和 (6,cc) (3,aa) (2,bb) (1,dd)
12、join(otherDataset, [numPartitions])
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD,等价于内连接操作。如果想要执行外连接,可以使用 leftOuterJoin, rightOuterJoin 和 fullOuterJoin 等算子。
val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6)))
rdd.join(rdd1).collect().foreach(println)
//输出结果(1,(dd,4)) (2,(bb,5)) (3,(aa,6))
Actions算子
1、reduce(func)算子
val list = List(1, 2, 3, 4, 5)
sc.parallelize(list).reduce((x, y) => x + y)
sc.parallelize(list).reduce(_ + _)
// 输出结果 15
2、collect()算子
在驱动程序中,以数组的形式返回数据集的所有元素。
val rdd = sc.parallelize(1 to 10)
println(rdd.collect.mkString(","))
//输出结果 1,2,3,4,5,6,7,8,9,10
3、count()算子
计算RDD中元素的个数
val rdd = sc.parallelize(1 to 10)
println(rdd.count)
//输出结果 10
4、first()算子
返回RDD中第一个元素
val rdd = sc.parallelize(1 to 10)
println(rdd.first)
//输出结果 1
5、take()算子
返回一个由RDD的前n个元素组成的数组
val rdd = sc.parallelize(Array(2,5,4,6,8,3))
println(rdd.take(3).mkString(","))
//输出结果 2 5 4
6、takeOrdered(n)算子
返回该RDD排序后的前n个元素组成的数组(会按照升序进行自动排序)
val makeRDD: RDD[Int] = sc.makeRDD(Array(2,5,4,6,3,8))
val ordered: Array[Int] = makeRDD.takeOrdered(3)
ordered.foreach(println)
//输出结果 2 3 4
7、saveAsTextFile算子
将 dataset 中的元素以文本文件的形式写入本地文件系统、HDFS 或其它 Hadoop 支持的文件系统中。Spark 将对每个元素调用 toString 方法,将元素转换为文本文件中的一行记录。
val list = List(("hadoop", 10), ("hadoop", 10), ("storm", 3), ("storm", 3), ("azkaban", 1))
sc.parallelize(list).saveAsTextFile("/usr/file/temp")
8、countByKey()算子
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。
val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
println(rdd.countByKey)
//输出结果 Map(3 -> 2, 1 -> 3, 2 -> 1)
9、foreach(func)算子
var rdd = sc.makeRDD(1 to 5,2)
rdd.foreach(println(_))
rdd.foreach(println)
//输出结果 1 2 3 4 5
SparkRDD算子(transformations算子和actions算子)的更多相关文章
- Java流中的map算子和flatMap算子的区别
map算子和flatMap算子 map和flatMap都是映射(转换),那么他们之间究竟有什么区别呢? 1.我们先简单了解下map算子: @org.junit.Test public void tes ...
- Python 图像处理 OpenCV (12): Roberts 算子、 Prewitt 算子、 Sobel 算子和 Laplacian 算子边缘检测技术
前文传送门: 「Python 图像处理 OpenCV (1):入门」 「Python 图像处理 OpenCV (2):像素处理与 Numpy 操作以及 Matplotlib 显示图像」 「Python ...
- Python 图像处理 OpenCV (13): Scharr 算子和 LOG 算子边缘检测技术
前文传送门: 「Python 图像处理 OpenCV (1):入门」 「Python 图像处理 OpenCV (2):像素处理与 Numpy 操作以及 Matplotlib 显示图像」 「Python ...
- 灰度图像--图像分割 Sobel算子,Prewitt算子和Scharr算子平滑能力比较
学习DIP第47天 转载请标明本文出处:http://blog.csdn.net/tonyshengtan ,出于尊重文章作者的劳动,转载请标明出处!文章代码已托管,欢迎共同开发: https://g ...
- SBX(Simulated binary crossover)模拟二进制交叉算子和DE(differential evolution)差分进化算子
一起来学演化计算-SBX(Simulated binary crossover)模拟二进制交叉算子和DE(differential evolution)差分进化算子 觉得有用的话,欢迎一起讨论相互学习 ...
- [转]Laplace算子和Laplacian矩阵
1 Laplace算子的物理意义 Laplace算子的定义为梯度的散度. 在Cartesian坐标系下也可表示为: 或者,它是Hessian矩阵的迹: 以热传导方程为例,因为热流与温度的梯度成正比,那 ...
- Laplace算子和Laplacian矩阵
1 Laplace算子的物理意义 Laplace算子的定义为梯度的散度. 在Cartesian坐标系下也可表示为: 或者,它是Hessian矩阵的迹: 以热传导方程为例,因为热流与温度的梯度成正比,那 ...
- halcon基础算子介绍(窗口创建,算子运行时长,是否启用更新函数)
前言 halcon有有大约1500个算子,我总结一些简单大家用得到的算子,比如创建窗口的方式有3种,接下来结束这方式,及其异同点等! 1.窗口创建的三种方式 1.1使用dev_open_window算 ...
- [大数据之Spark]——Actions算子操作入门实例
Actions reduce(func) Aggregate the elements of the dataset using a function func (which takes two ar ...
- spark actions 算子
package action; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; imp ...
随机推荐
- ABAP开发规范V1.0
1. 概要 1.1目的 该文档定义了在开发与维护ABAP程序过程中必须遵守的规范与标准.该文档应当被视为一个动态的文档,该文档会根据需要进行增补和修订. 开发规范的重要作用在于保持整个开发团队的开发风 ...
- Attribute application@label value=(xxx) from AndroidManifest.xml:8:16-37 is also present at [com.github.adrielcafe:AndroidAudioConverter:0.0.8] AndroidManifest.xml:11:18-50 value=(@string/app_name)
关于安卓编译错误Attribute application@label value=(xxx) from AndroidManifest.xml:8:16-37 is also present at ...
- ajax请求与前后端交互的数据编码格式
目录 一.Ajax AJAX简介 应用场景 AJAX的优点 语法实现 二.数据编码格式(Content-Type) 写在前面 form表单 几种数据编码格式介绍 三.ajax携带文件数据 四.ajax ...
- django连接数据库与orm基础知识
目录 一.django连接数据库 二.pycharm连接MySQL数据库 三.ORM简介 1.ORM概念 2.ORM由来 3.ORM的优势和劣势 ORM的优势 ORM的劣势 四.ORM基本操作 1.现 ...
- ctr命令的基本使用与技巧
k8s早1.24后放弃docker,并把containerd作为运行时组件,containerd 调用链更短,组件更少,更稳定,占用节点资源更少 ctr是containerd的一个客户端工具 cric ...
- Qt编写物联网管理平台39-报警联动
一.前言 本系统支持报警联动,就是某个探测器报警后,再去下发命令,通知下面的继电器警号,一般是通过串口发送,由于现场会利用现有的串口线路比如485总线,所以本系统需要做特殊处理,就是公用485通信总线 ...
- Qt音视频开发24-ffmpeg音视频同步
一.前言 用ffmpeg来做音视频同步,个人认为这个是ffmpeg基础处理中最难的一个,无数人就卡在这里,怎么也不准,本人也是尝试过网上各种demo,基本上都是渣渣,要么仅仅支持极其少量的视频文件比如 ...
- Python串口实现dk-51e1单相交直流标准源通信
Python实现dk-51e1单相交直流标准源RS232通信 使用RS232,信号源DK51e1的协议帧格式如下: 注意点 配置串口波特率为115200 Check异或和不需要加上第一个0x81的字段 ...
- nio-总结列表
java IO体系图 IO流的操作规律总结: 1,明确体系:数据源:InputStream ,Reader数据汇:OutputStream,Writer 2,明确数据:因为数据分两种:字节,字符.数据 ...
- w3cschool-Apache Pig 教程
https://www.w3cschool.cn/apache_pig/ 什么是Apache Pig? Apache Pig是MapReduce的一个抽象.它是一个工具/平台,用于分析较大的数据集,并 ...