MPI之聚合通信-Scatter,Gather,Allgather
转自:https://blog.csdn.net/sinat_22336563/article/details/70229243
参考:http://mpitutorial.com/tutorials/performing-parallel-rank-with-mpi/
一、 MPI_Scatter
MPI_Scatter与MPI_Bcast非常相似,都是一对多的通信方式,不同的是后者的0号进程将相同的信息发送给所有的进程,而前者则是将一段array 的不同部分发送给所有的进程,其区别可以用下图概括: 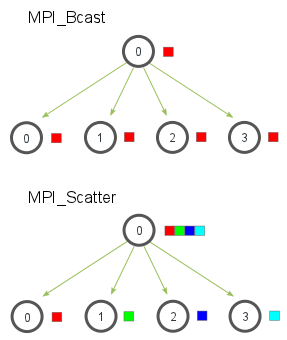
0号进程分发数据的时候是根据进程的编号进行的,array中的第一个元素发送给0号进程,第二个元素则发送给1号进程,以此类推。
MPI_Scatter(
void* send_data,//存储在0号进程的数据,array
int send_count,//具体需要给每个进程发送的数据的个数
//如果send_count为1,那么每个进程接收1个数据;如果为2,那么每个进程接收2个数据
MPI_Datatype send_datatype,//发送数据的类型
void* recv_data,//接收缓存,缓存 recv_count个数据
int recv_count,
MPI_Datatype recv_datatype,
int root,//root进程的编号
MPI_Comm communicator)
通常send_count等于array的元素个数除以进程个数。
二、 MPI_Gather
MPI_Gather和MPI_scatter刚好相反,他的作用是从所有的进程中将每个进程的数据集中到根进程中,同样根据进程的编号对array元素排序,如图所示: 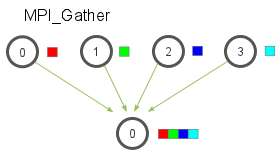
其函数为:
MPI_Gather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,//注意该参数表示的是从单个进程接收的数据个数,不是总数
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)
三、MPI_Allgather
当数据分布在所有的进程中时,MPI_Allgather将所有的数据聚合到每个进程中。 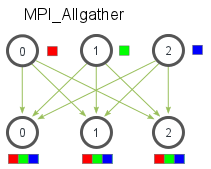
MPI_Allgather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
MPI_Comm communicator)
四、实例
问题描述:
我们的函数需要在每个进程中取一个数字,并返回其所有流程中所有其他数字的相关排名。 与此同时,我们将需要其他杂项信息,例如正在使用的通信器以及正在排名的数字的数据类型。
整体函数表示:
TMPI_Rank(
void *send_data,
void *recv_data,
MPI_Datatype datatype,
MPI_Comm comm)
TMPI_Rank接收一个包含一个datatype类型的send_data缓冲区。 recv_data在包含send_data的rank值的每个进程上只收到一个整数。 comm变量是正在进行排名的通信器。
解决并行排序问题的第一步是排序所有进程的所有数字。 这必须完成,以便我们可以在整个数字集中找到每个数字的排名。 有很多方法可以做到这一点。 最简单的方法是将所有数字收集到一个进程并对数字进行排序。
void *gather_numbers_to_root(void *number, MPI_Datatype datatype,
MPI_Comm comm) {
int comm_rank, comm_size;
MPI_Comm_rank(comm, &comm_rank);
MPI_Comm_size(comm, &comm_size); // 根据使用的数据类型,给根进程分配size
int datatype_size;
MPI_Type_size(datatype, &datatype_size);
void *gathered_numbers;
if (comm_rank == ) {
gathered_numbers = malloc(datatype_size * comm_size);
} // 收集根进程的所有数字
MPI_Gather(number, , datatype, gathered_numbers, ,
datatype, , comm); return gathered_numbers;
}
根进程必须在此函数中收集comm_size数字,所以它malloc一个datatype_size * comm_size长度的数组。在使用MPI_Gather在根进程上收集数字之后,数字必须在根进程中进行排序,以便可以确定其编号。
先定义一个结构体
typedef struct {
int comm_rank;
union {
float f;
int i;
} number;
} CommRankNumber;
排序使用C标准库函数:
int *get_ranks(void *gathered_numbers, int gathered_number_count,
MPI_Datatype datatype) {
int datatype_size;
MPI_Type_size(datatype, &datatype_size); //将收集的数字数组转换为CommRankNumbers数组。
// 这使我们能够对数字进行排序,并保留拥有数字的进程信息。
CommRankNumber *comm_rank_numbers = malloc(
gathered_number_count * sizeof(CommRankNumber));
int i;
for (i = ; i < gathered_number_count; i++) {
comm_rank_numbers[i].comm_rank = i;
memcpy(&(comm_rank_numbers[i].number),
gathered_numbers + (i * datatype_size),
datatype_size);
} // 根据数据类型进行排序
if (datatype == MPI_FLOAT) {
qsort(comm_rank_numbers, gathered_number_count,
sizeof(CommRankNumber), &compare_float_comm_rank_number);
} else {
qsort(comm_rank_numbers, gathered_number_count,
sizeof(CommRankNumber), &compare_int_comm_rank_number);
} // comm_rank_numbers被排序,为每个进程创建一个编号数组。 该数组的第i个元素包含进程i发送的数字的编号。数字排序后,我们必须以正确的顺序创建一个排列数组,以便它们可以scatter回请求进程。
int *ranks = (int *)malloc(sizeof(int) * gathered_number_count);
for (i = ; i < gathered_number_count; i++) {
ranks[comm_rank_numbers[i].comm_rank] = i;
} // Clean up and return the rank array
free(comm_rank_numbers);
return ranks;
}
综合可得:
int TMPI_Rank(void *send_data, void *recv_data, MPI_Datatype datatype,
MPI_Comm comm) {
// 首先检查基本情况 - 仅支持此函数的MPI_INT和MPI_FLOAT。
if (datatype != MPI_INT && datatype != MPI_FLOAT) {
return MPI_ERR_TYPE;
} int comm_size, comm_rank;
MPI_Comm_size(comm, &comm_size);
MPI_Comm_rank(comm, &comm_rank); // 要计算编号,我们必须将数字收集到一个进程中,对数字进行排序,然后分散结果的等级值。
//首先收集comm的进程0的数字。
void *gathered_numbers = gather_numbers_to_root(send_data, datatype,
comm); // 获得每个进程的编号
int *ranks = NULL;
if (comm_rank == ) {
ranks = get_ranks(gathered_numbers, comm_size, datatype);
} // Scatter the rank results
MPI_Scatter(ranks, , MPI_INT, recv_data, , MPI_INT, , comm); // Do clean up
if (comm_rank == ) {
free(gathered_numbers);
free(ranks);
}
}
流程如下: ![]()
五、总结
本节介绍了三种聚合通信,分别对应一对多,多对一,多对多通信。
MPI之聚合通信-Scatter,Gather,Allgather的更多相关文章
- NIO相关概念之Scatter / Gather
Scatter /Gather 是java NIO中用来对channel的读取或者写入操作的特殊的形式的描述 Scatter(发散) 是指在读操作的时候,从chanel读取到的数据,写入到多个buff ...
- JAVA NIO Scatter/Gather(矢量IO)
矢量IO=Scatter/Gather: 在多个缓冲区上实现一个简单的IO操作.减少或避免了缓冲区拷贝和系统调用(IO) write:Gather 数据从几个缓冲区顺序抽取并沿着通道发送,就好 ...
- 转:Java NIO系列教程(四) Scatter/Gather
Java NIO开始支持scatter/gather,scatter/gather用于描述从Channel(译者注:Channel在中文经常翻译为通道)中读取或者写入到Channel的操作.分散(sc ...
- java的nio之:java的nio系列教程之Scatter/Gather
一:Java NIO的scatter/gather应用概念 ===>Java NIO开始支持scatter/gather,scatter/gather用于描述从Channel(译者注:Chann ...
- Java基础知识强化之IO流笔记75:NIO之 Scatter / Gather
1. Java NIO开始支持scatter/gather,scatter/gather用于描述从Channel(译者注:Channel在中文经常翻译为通道)中读取或者写入到Channel的操作. 分 ...
- Java NIO Scatter / Gather
原文链接:http://tutorials.jenkov.com/java-nio/scatter-gather.html Java NIO发布时内置了对scatter / gather的支持.sca ...
- Java NIO中的通道Channel(二)分散/聚集 Scatter/Gather
什么是Scatter/Gather scatter/gather指的在多个缓冲区上实现一个简单的I/O操作,比如从通道中读取数据到多个缓冲区,或从多个缓冲区中写入数据到通道: scatter(分散): ...
- Java NIO系列教程(四) Scatter/Gather
Java NIO开始支持scatter/gather,scatter/gather用于描述从Channel(译者注:Channel在中文经常翻译为通道)中读取或者写入到Channel的操作.分散(sc ...
- NIO学习笔记六:channel 之前数据传输及scatter/gather
在Java NIO中,如果两个通道中有一个是FileChannel,那你可以直接将数据从一个channel传输到另外一个channel. FileChannel的transferFrom()方法可以将 ...
随机推荐
- Pycharm学习python路
import 模块之后是灰色的表明没有被引用过 lxml找不到的话用anaconda prompt :pip uninstall lxml 重新安装 用request时,写的reg无法正确解析网页,先 ...
- 【2017-2-23】C#switch case分支语句,for循环语句
switch case分支语句 switch(一个变量值) { case 值:要执行的代码段;break; case 值:要执行的代码段;break; … default:代码段;break;(def ...
- for-each 循环原理
for-each 循环原理1,for-each 是在java5 之后出现的.for是java 上的一个关键字,在jdk 找不到任何for的底层实现的.是因为for的底层实现被封装到了编译器中.所以通过 ...
- orb slam2 双目摄像头
主要参考了http://blog.csdn.net/awww797877/article/details/51171099这篇文章,其中需要添加的是:export ROS_PACKAGE_PATH=$ ...
- MongoDB3.X单机及shading cluster集群的权限管理(基于3.4.5)
mongodb集群的权限管理分为两部分,一部分是最常用的Role-Based Access Control,也就是用户名密码方式,这种验证方式一般出现在单机系统,或者集群中client端连接Mongo ...
- 查询和修改mysql最大连接数的方法
查询和修改mysql最大连接数的方法切换到mysql库里查询show variables like 'max_connections';show global status like 'Max_use ...
- Bluetooth_FTP_SPEC: 蓝牙FTP介绍
FTP(Bluetooth File Transfer Profile) defines howfolders and files on a server device can be browsed ...
- [转载]转,Oracle中关于处理小数点位数的几个函数,取小数位数,Oracle查询函数
关于处理小数点位数的几个oracle函数() 1. 取四舍五入的几位小数 select round(1.2345, 3) from dual; 结果:1.235 2. 保留两位小数,只舍 select ...
- PDF文档导出
代码如下: /// <summary> /// 获取html内容,转成PDF(注册) /// </summary> public void DownloadPDFByHTML( ...
- Markdown使用笔记
下载地址:http://markdownpad.com/ 简明版 Markdown 语法说明(简体中文版) 完整版 Markdown 语法说明(简体中文版) 官方文档:http://www.markd ...