Hive之一:hive2.1.1安装部署
一、Hive 运行模式
1. 内嵌模式
将元数据保存在本地内嵌的 Derby 数据库中,这是使用 Hive 最简单的方式。但是这种方式缺点也比较明显,因为一个内嵌的 Derby 数据库每次只能访问一个数据文件,这也就意味着它不支持多会话连接。
2. 本地模式
这种模式是将元数据保存在本地独立的数据库中(一般是 MySQL),这用就可以支持多会话和多用户连接了。
3. 远程模式
此模式应用于 Hive 客户端较多的情况。把 MySQL 数据库独立出来,将元数据保存在远端独立的 MySQL 服务中,避免了在每个客户端都安装 MySQL 服务从而造成冗余浪费的情况。
二、下载安装 Hive
http://hive.apache.org/downloads.html
tar -xzvf apache-hive-2.1.1-bin.tar.gz ##解压
三、配置系统环境变量
修改 /etc/profile 文件 vi /etc/profile 来修改(root用户操作):
export JAVA_HOME="/usr/local/jdk1.8.0_172"
export HIVE_HOME=/home/duanxz/hive/apache-hive-2.1.-bin
export PATH="$PATH:$JAVA_HOME/bin:$HIVE_HOME/bin:$HIVE_HOME/conf"
四、内嵌模式
(1)修改 Hive 配置文件
$HIVE_HOME/conf 对应的是 Hive 的配置文件路径,类似于之前学习的Hbase, 该路径下的 hive-site.xml 是 Hive 工程的配置文件。默认情况下,该文件并不存在,我们需要拷贝它的模版来实现:
hive-site.xml 的主要配置有:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
<description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.</description>
</property>
hive.metastore.warehouse.dir
该参数指定了 Hive 的数据存储目录,默认位置在 HDFS 上面的 /user/hive/warehouse 路径下。hive.exec.scratchdir
该参数指定了 Hive 的数据临时文件目录,默认位置为 HDFS 上面的 /tmp/hive 路径下。
同时我们还要修改 Hive 目录下 /conf/hive-env.sh 文件(请根据自己的实际路径修改),该文件默认也不存在,同样是拷贝它的模版来修改:
cp hive-env.sh.template hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/local/hadoop-2.7. # Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/home/duanxz/hive/apache-hive-2.1.-bin/conf # Folder containing extra ibraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=/home/duanxz/hive/apache-hive-2.1.-bin/bin
(2)创建必要目录
前面我们看到 hive-site.xml 文件中有两个重要的路径,切换到 hadoop 用户下查看 HDFS 是否有这些路径:
duanxz@three:~$ sudo chmod a+w hive
hadoop fs -ls /
没有发现上面提到的路径,因此我们需要自己新建这些目录,并且给它们赋予用户写(W)权限。
$HADOOP_HOME/bin/hadoop fs -mkdir -p /hive/warehouse
$HADOOP_HOME/bin/hadoop fs -mkdir -p /tmp/hive/
hadoop fs -chmod /hive/warehouse
hadoop fs -chmod /tmp/hive
检查是否新建成功 hadoop fs -ls / 以及 hadoop fs -ls /tmp/hive/ :
(3)修改 io.tmpdir 路径
同时,要修改 hive-site.xml 中所有包含 ${system:java.io.tmpdir} 字段的 value 即路径(vim下 / 表示搜索,后面跟你的关键词,比如搜索 hello,则为 /hello , 再回车即可),你可以自己新建一个目录来替换它,例如
(4)运行 Hive
./bin/hive
报错
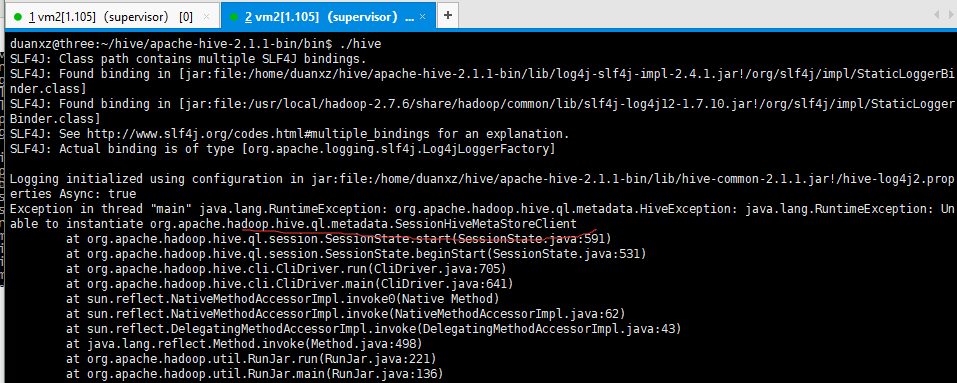
解决办法:./schematool -initSchema -dbType derby
报错
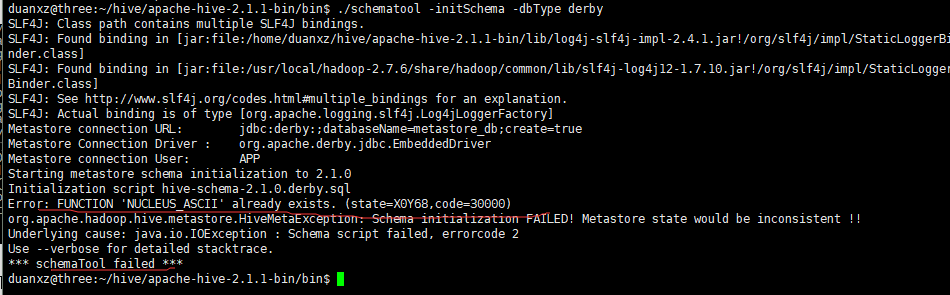
解决方法:删除/home/hadoop/cloud/apache-hive-2.1.1-bin目录下 rm -rf metastore_db/ ,再初始化:./bin/schematool -initSchema -dbType derby
重新运行
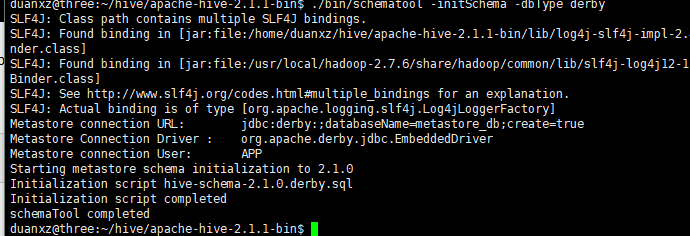
但在我的机器上没有metastore_db/这个目录,也修改下初始化命令,执行目录向上退一级再执行:
./bin/schematool -initSchema -dbType derby
执行成功,如下图:
再启动hive:
./bin/hive
报错
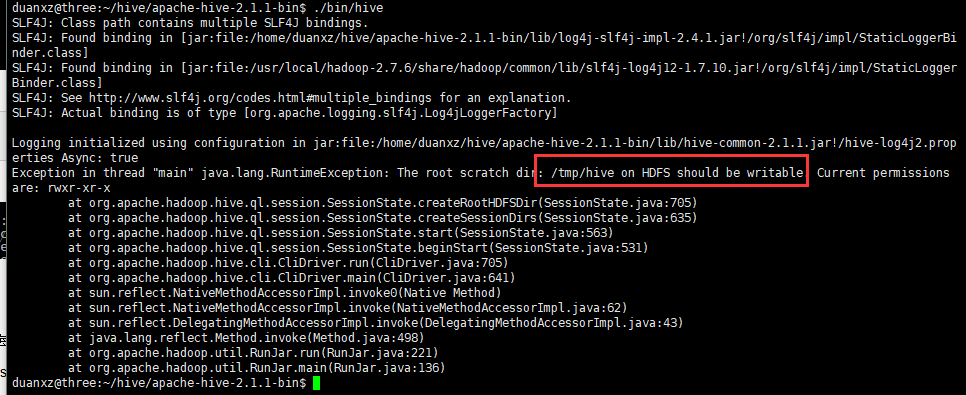
/tmp/hive 没写的权限
duanxz@three:~/hive/apache-hive-2.1.-bin$ hadoop fs -chmod a+w /tmp/hive
启动城后,如下:
关闭就杀死对应的进程即可
duanxz@three:~$ jps
RunJar
Hive本身自带一个数据库,但是有弊端,hive本身数据库,每次只允许一个用户登录
mysql安装:http://blog.csdn.net/u014695188/article/details/51532410
设置mysql关联hive
修改配置文件
### 创建hive-site.xml文件
在hive/conf/目录下创建hive-site.xml文件
- <?xml version="1.0" encoding="UTF-8" standalone="no"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>javax.jdo.option.ConnectionURL</name>
- <value>jdbc:mysql://192.168.169.134:3306/hive?createDatabaseIfNotExist=true</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionDriverName</name>
- <value>com.mysql.jdbc.Driver</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionUserName</name>
- <value>root</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionPassword</name>
- <value>123456</value>
- </property>
- <property>
- <name>hive.metastore.schema.verification</name>
- <value>false</value>
- <description>
- Enforce metastore schema version consistency.
- True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic
- schema migration attempt. Users are required to manully migrate schema after Hive upgrade which ensures
- proper metastore schema migration. (Default)
- False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
- </description>
- </property>
- </configuration>
报错:Caused by: MetaException(message:Version information not found in metastore. )
解决:hive-site.xml加入
- <property>
- <name>hive.metastore.schema.verification</name>
- <value>false</value>
- <description>
- Enforce metastore schema version consistency.
- True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic
- schema migration attempt. Users are required to manully migrate schema after Hive upgrade which ensures
- proper metastore schema migration. (Default)
- False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
- </description>
- </property>
报错:缺少mysql jar包
解决:将其(如mysql-connector-Java-5.1.15-bin.jar)拷贝到$HIVE_HOME/lib下即可。
报错:
- Exception in thread "main" java.lang.RuntimeException: Hive metastore database is not initialized.
- Please use schematool (e.g. ./schematool -initSchema -dbType ...) to create the schema. If needed,
- don't forget to include the option to auto-create the underlying database in your JDBC connection string (e.g. ?createDatabaseIfNotExist=true for mysql)
解决:
- #数据库的初始化。
- bin/schematool -initSchema -dbType mysql
启动:
- bin/hive
启动后mysql 多了hive 数据库

创建数据库

创建测试表
use db_hive_test;
create table student(id int,name string) row format delimited fields terminated by '\t';


加载数据到表中
新建student.txt 文件写入数据(id,name 按tab键分隔)
vi student.txt
- 1001 zhangsan
- 1002 lisi
- 1003 wangwu
- 1004 zhaoli
load data local inpath '/home/hadoop/student.txt' into table db_hive_test.student

查询表信息
select * from student;
查看表的详细信息
desc formatted student;
通过ui页面查看创建的数据位置
http://192.168.169.132:50070/explorer.html#/user/hive/warehouse/db_hive_test.db

通过Mysql查看创建的表

查看hive的函数
show functions;
查看函数详细信息
desc function sum;
desc function extended

感谢:https://www.cnblogs.com/hmy-blog/p/6506417.html
Hive之一:hive2.1.1安装部署的更多相关文章
- Hive 系列(一)安装部署
Hive 系列(一)安装部署 Hive 官网:http://hive.apache.org.参考手册 一.环境准备 JDK 1.8 :从 Oracle 官网下载,设置环境变量(JAVA_HOME.PA ...
- Ubuntu16.04 和 hadoop2.7.3环境下 hive2.1.1安装部署
参考文献: http://blog.csdn.NET/reesun/article/details/8556078 http://blog.csdn.Net/zhongguozhichuang/art ...
- hive2.1.1安装部署
转至:https://i.cnblogs.com/EditPosts.aspx?opt=1 一.Hive 运行模式 与 Hadoop 类似,Hive 也有 3 种运行模式: 1. 内嵌模式 将元数据保 ...
- Hive 环境的安装部署
Hive在客户端上的安装部署 一.客户端准备: 到这我相信大家都已经打过三节点集群了,如果是的话则可以跳过一,直接进入二.如果不是则按流程来一遍! 1.克隆虚拟机,见我的博客:虚拟机克隆及网络配置 2 ...
- 【Hadoop离线基础总结】impala简单介绍及安装部署
目录 impala的简单介绍 概述 优点 缺点 impala和Hive的关系 impala如何和CDH一起工作 impala的架构及查询计划 impala/hive/spark 对比 impala的安 ...
- Hive基础概念、安装部署与基本使用
1. Hive简介 1.1 什么是Hive Hives是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能. 1.2 为什么使用Hive ① 直接使用 ...
- 【Hadoop离线基础总结】Hive的安装部署以及使用方式
Hive的安装部署以及使用方式 安装部署 Derby版hive直接使用 cd /export/softwares 将上传的hive软件包解压:tar -zxvf hive-1.1.0-cdh5.14. ...
- 【原】Centos6.5下cdh4.6 hive安装部署
1.前提条件: 只需要选择一台服务器即可,这里选择安装在namenode上:安装用户为cloud-user 2.安装包: sudo yum install -y hive hive ...
- CentOS下SparkR安装部署:hadoop2.7.3+spark2.0.0+scale2.11.8+hive2.1.0
注:之前本人写了一篇SparkR的安装部署文章:SparkR安装部署及数据分析实例,当时SparkR项目还没正式入主Spark,需要自己下载SparkR安装包,但现在spark已经支持R接口,so更新 ...
随机推荐
- Ubuntu18.10下运行blender2.80bate闪退(问题?)
Ubuntu18.10下直接运行blender2.80bate闪退, 运行blender2.79正常. ================= root@tom-laptop:/# uname -aLin ...
- hdu4553 约会安排 线段树
寒假来了,又到了小明和女神们约会的季节. 小明虽为屌丝级码农,但非常活跃,女神们常常在小明网上的大段发言后热情回复“呵呵”,所以,小明的最爱就是和女神们约会.与此同时,也有很多基友找他开黑,由于数量实 ...
- hdu3613 Best Reward manacher+贪心+前缀和
After an uphill battle, General Li won a great victory. Now the head of state decide to reward him w ...
- 【JVM】java对象
一.对象内存布局 对象在内存中存储可分为3块区域:对象头,实例数据,对齐填充 1.对象头 对象头包含两部分内容. 第一部分:存储对象自身的运行时数据,哈希吗(hashCode),GC分代年龄,锁状态标 ...
- 【mybatis源码学习】mybtias扩展点
[1]org.apache.ibatis.reflection.ReflectorFactory 该扩展点,主要是对javaBean对象,进行反射操作. org.apache.ibatis.refle ...
- 【idea】清除类中无用的包
快捷键 ctrl+alt+o 自动清除的配置方法 可以settings-general-auto import-java项,勾选optimize imports on the fly,在当前项目下会自 ...
- LOJ3048 「十二省联考 2019」异或粽子
题意 题目描述 小粽是一个喜欢吃粽子的好孩子.今天她在家里自己做起了粽子. 小粽面前有 $n$ 种互不相同的粽子馅儿,小粽将它们摆放为了一排,并从左至右编号为 $1$ 到 $n$.第 $i$ 种馅儿具 ...
- minio 对于压缩的处理
我们可以简单的配置就可以让minio 支持数据压缩了,这个对于减少带宽的请求,以及web 端的优化很有意义 配置说明 配置文件 "compress": { "enable ...
- ubuntu忘记登录密码解决方法
1.重启系统,长按Shift键,直到出现下面菜单.选择recovery mode(恢复模式).2.接下来会进入如下界面,选择Drop to root shell prompt ,也就是获取root权限 ...
- 螺旋矩阵 II
给定一个正整数 n,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的正方形矩阵. 示例: 输入: 3 输出: [ [ 1, 2, 3 ], [ 8, 9, 4 ], [ 7, 6, ...