Spark SQL 之 Performance Tuning & Distributed SQL Engine
Spark SQL 之 Performance Tuning & Distributed SQL Engine
转载请注明出处:http://www.cnblogs.com/BYRans/
缓存数据至内存(Caching Data In Memory)
Spark SQL可以通过调用sqlContext.cacheTable("tableName") 或者dataFrame.cache(),将表用一种柱状格式( an inmemory columnar format)缓存至内存中。然后Spark SQL在执行查询任务时,只需扫描必需的列,从而以减少扫描数据量、提高性能。通过缓存数据,Spark SQL还可以自动调节压缩,从而达到最小化内存使用率和降低GC压力的目的。调用sqlContext.uncacheTable("tableName")可将缓存的数据移出内存。
可通过两种配置方式开启缓存数据功能:
- 使用SQLContext的setConf方法
- 执行SQL命令 SET key=value

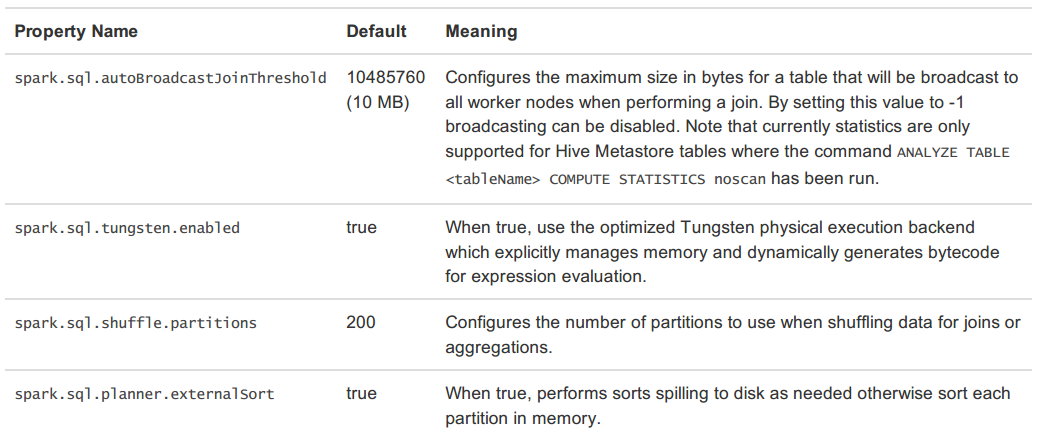
调优参数(Other Configuration Options)
可以通过配置下表中的参数调节Spark SQL的性能。在后续的Spark版本中将逐渐增强自动调优功能,下表中的参数在后续的版本中或许将不再需要配置。
分布式SQL引擎
使用Spark SQL的JDBC/ODBC或者CLI,可以将Spark SQL作为一个分布式查询引擎。终端用户或应用不需要编写额外的代码,可以直接使用Spark SQL执行SQL查询。
运行Thrift JDBC/ODBC服务
这里运行的Thrift JDBC/ODBC服务与Hive 1.2.1中的HiveServer2一致。可以在Spark目录下执行如下命令来启动JDBC/ODBC服务:
./sbin/start-thriftserver.sh
这个命令接收所有 bin/spark-submit 命令行参数,添加一个 --hiveconf 参数来指定Hive的属性。详细的参数说明请执行命令 ./sbin/start-thriftserver.sh --help 。
服务默认监听端口为localhost:10000。有两种方式修改默认监听端口:
- 修改环境变量:
export HIVE_SERVER2_THRIFT_PORT=<listening-port>
export HIVE_SERVER2_THRIFT_BIND_HOST=<listening-host>
./sbin/start-thriftserver.sh \
--master <master-uri> \
...
- 修改系统属性
./sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=<listening-port> \
--hiveconf hive.server2.thrift.bind.host=<listening-host> \
--master <master-uri>
...
使用 beeline 来测试Thrift JDBC/ODBC服务:
./bin/beeline
连接到Thrift JDBC/ODBC服务
beeline> !connect jdbc:hive2://localhost:10000
在非安全模式下,只需要输入机器上的一个用户名即可,无需密码。在安全模式下,beeline会要求输入用户名和密码。安全模式下的详细要求,请阅读beeline documentation的说明。
配置Hive需要替换 conf/ 目录下的 hive-site.xml。
Thrift JDBC服务也支持通过HTTP传输发送thrift RPC messages。开启HTTP模式需要将下面的配参数配置到系统属性或 conf/: 下的 hive-site.xml中
hive.server2.transport.mode - Set this to value: http
hive.server2.thrift.http.port - HTTP port number fo listen on; default is 10001
hive.server2.http.endpoint - HTTP endpoint; default is cliservice
测试http模式,可以使用beeline链接JDBC/ODBC服务:
beeline> !connect jdbc:hive2://<host>:<port>/<database>?hive.server2.transport.mode=http;hive.server2.thrift.http.path=<http_endpoint>
运行Spark SQL CLI
Spark SQL CLI可以很方便的在本地运行Hive元数据服务以及从命令行执行查询任务。需要注意的是,Spark SQL CLI不能与Thrift JDBC服务交互。
在Spark目录下执行如下命令启动Spark SQL CLI:
./bin/spark-sql
配置Hive需要替换 conf/ 下的 hive-site.xml 。执行 ./bin/spark-sql --help 可查看详细的参数说明 。
Spark SQL 之 Performance Tuning & Distributed SQL Engine的更多相关文章
- Microsoft.SQL.Server2012.Performance.Tuning.Cookbook学习笔记(一)
一.Creating a trace or workload 注意点: In the Trace Properties dialog box, there is a checkbox option i ...
- Microsoft.SQL.Server2012.Performance.Tuning.Cookbook学习笔记(二)
Creating trace with system stored procedures Following are the stored procedures which you should kn ...
- 30 分钟快快乐乐学 SQL Performance Tuning
转自:http://www.cnblogs.com/WizardWu/archive/2008/10/27/1320055.html 有些程序员在撰写数据库应用程序时,常专注于 OOP 及各种 fra ...
- Sql性能检测工具:Sql server profiler和优化工具:Database Engine Tuning Advisor
原文:Sql性能检测工具:Sql server profiler和优化工具:Database Engine Tuning Advisor 一.工具概要 数据库应用系统性能低下,需要对其进行优化 ...
- [转]Performance Analysis Using SQL Server 2008 Activity Monitor Tool
本文转自:https://www.mssqltips.com/sqlservertip/1917/performance-analysis-using-sql-server-2008-activity ...
- SQL Server performance tips
Refer to: http://harriyott.com/2006/01/sql-server-performance-tips A colleague of mine has been look ...
- spark 分析sql内容再插入到sql表中
package cn.spark.study.core.mycode_dataFrame; import java.sql.DriverManager;import java.util.ArrayLi ...
- 《高性能SQL调优精要与案例解析》一书谈主流关系库SQL调优(SQL TUNING或SQL优化)核心机制之——索引(index)
继<高性能SQL调优精要与案例解析>一书谈SQL调优(SQL TUNING或SQL优化),我们今天就谈谈各主流关系库中,占据SQL调优技术和工作半壁江山的.最重要的核心机制之一——索引(i ...
- 初次使用SQL调优建议工具--SQL Tuning Advisor
在10g中,Oracle推出了自己的SQL优化辅助工具: SQL优化器(SQL Tuning Advisor :STA),它是新的DBMS_SQLTUNE包. 使用STA一定要保证优化器是CBO模式下 ...
随机推荐
- Xamarin安装和跳坑指南
安装Checklist 注意:本文只描述安装过程,由于组件的版本更新很快,为保证文章时效性,不提供下载链接,也尽可能不指明具体版本. 安装Visual Studio 2015进行默认安装,除非已经FQ ...
- Intercooler.js – 让 AJAX 像锚标签一样简单
使用 Intercooler,你可以添加 Ajax 到你的应用程序,而无需使用客户端模式的路由,认证,渲染,工厂或依赖注入.事实上,你不需要写任何的 JavaScript 代码.Intercooler ...
- MySQL的常规操作
MySQL的常规知识 show 查看数据库 show databases; 查看表 存在的所有表 show tables; 创建表的命令 show create table table_name; 表 ...
- 【追寻javascript高手之路04】理解prototype
前言 中午时候我去药店称了下体重,好家伙!我减肥成功了,足足比上个月瘦了10斤!于是想减肥就去郑州吧... 然后回来迷迷糊糊睡了一会,居然想起了周三的面试,有点小遗憾有点小触动. 这次回成都后,还没有 ...
- An interesting experiment on China’s censorship
This paper presented a very interesting topic. Censorship in China has always drawn people's attenti ...
- 微信小程序如何设置开发者和体验者
微信小程序需要在后台添加开发者和体验者 开发者:增加开发人员的,开发人员添加后,可上传代码,最多10个人,可以删除 体验者:添加为体验者,管理员发布体验版本后,通过扫码二维码可以下载体验版小程序,最多 ...
- 关于Android Force Close 出现的原因 以及解决方法
一.原因: forceclose,意为强行关闭,当前应用程序发生了冲突. NullPointExection(空指针),IndexOutOfBoundsException(下标越界),就连Androi ...
- IDA来Patch android的so文件
在上文中,我们通过分析定位到sub_130C()这个函数有很大可能性是用来做反调试检测的,并且作者开了一个新的线程,并且用了一个while来不断执行sub_130C()这个函数,所以说我们每次手动的修 ...
- hybrid app
hybrid app Hybrid App(混合模式移动应用)是指介于web-app.native-app这两者之间的app,兼具“Native App良好用户交互体验的优势”和“Web App跨平台 ...
- Android 应用程序的反编译
1.ApkTool工具 安装ApkTool工具,该工具可以解码得到资源文件,但不能得到Java源文件.安装环境:需要安装JRE1.61> 到http://code.google.com/p/an ...