论文笔记之:Deep Attention Recurrent Q-Network
Deep Attention Recurrent Q-Network
5vision groups
摘要:本文将 DQN 引入了 Attention 机制,使得学习更具有方向性和指导性。(前段时间做一个工作打算就这么干,谁想到,这么快就被这几个孩子给实现了,自愧不如啊( ⊙ o ⊙ ))
引言:我们知道 DQN 是将连续 4帧的视频信息输入到 CNN 当中,那么,这么做虽然取得了不错的效果,但是,仍然只是能记住这 4 帧的信息,之前的就会遗忘。所以就有研究者提出了 Deep Recurrent Q-Network (DRQN),一个结合 LSTM 和 DQN 的工作:
1. the fully connected layer in the latter is replaced for a LSTM one ,
2. only the last visual frame at each time step is used as DQN's input.
作者指出虽然只是使用了一帧的信息,但是 DRQN 仍然抓住了帧间的相关信息。尽管如此,仍然没有看到在 Atari game上有系统的提升。
另一个缺点是:长时间的训练时间。据说,在单个 GPU 上训练时间达到 12-14天。于是,有人就提出了并行版本的算法来提升训练速度。作者认为并行计算并不是唯一的,最有效的方法来解决这个问题。
最近 visual attention models 在各个任务上都取得了惊人的效果。利用这个机制的优势在于:仅仅需要选择然后注意一个较小的图像区域,可以帮助降低参数的个数,从而帮助加速训练和测试。对比 DRQN,本文的 LSTM 机制存储的数据不仅用于下一个 actions 的选择,也用于 选择下一个 Attention 区域。此外,除了计算速度上的改进之外,Attention-based models 也可以增加 Deep Q-Learning 的可读性,提供给研究者一个机会去观察 agent 的集中区域在哪里以及是什么,(where and what)。
Deep Attention Recurrent Q-Network:
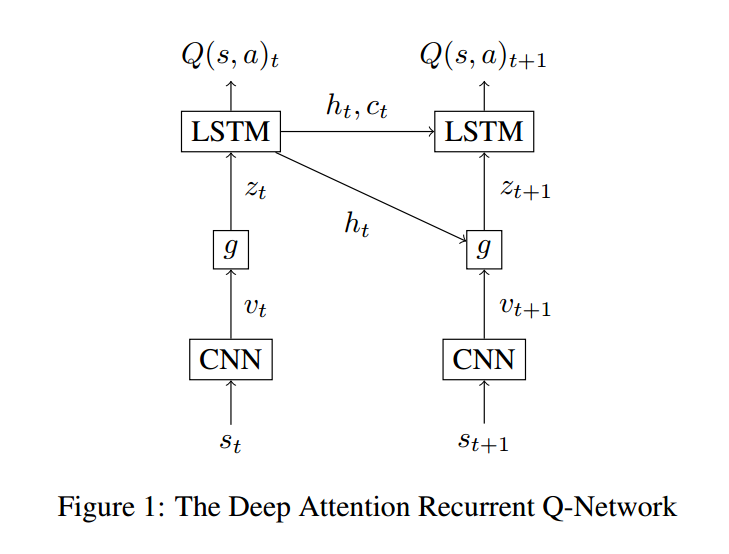
如上图所示,DARQN 结构主要由 三种类型的网络构成:convolutional (CNN), attention, and recurrent . 在每一个时间步骤 t,CNN 收到当前游戏状态 $s_t$ 的一个表示,根据这个状态产生一组 D feature maps,每一个的维度是 m * m。Attention network 将这些 maps 转换成一组向量 $v_t = \{ v_t^1, ... , v_t^L \}$,L = m*m,然后输出其线性组合 $z_t$,称为 a context vector. 这个 recurrent network,在我们这里是 LSTM,将 context vector 作为输入,以及 之前的 hidden state $h_{t-1}$,memory state $c_{t-1}$,产生 hidden state $h_t$ 用于:
1. a linear layer for evaluating Q-value of each action $a_t$ that the agent can take being in state $s_t$ ;
2. the attention network for generating a context vector at the next time step t+1.
Soft attention :
这一小节提到的 "soft" Attention mechanism 假设 the context vector $z_t$ 可以表示为 所有向量 $v_t^i$ 的加权和,每一个对应了从图像不同区域提取出来的 CNN 特征。权重 和 这个 vector 的重要程度成正比例,并且是通过 Attention network g 衡量的。g network 包含两个 fc layer 后面是一个 softmax layer。其输出可以表示为:
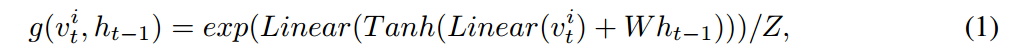
其中,Z是一个normalizing constant。W 是权重矩阵,Linear(x) = Ax + b 是一个放射变换,权重矩阵是A,偏差是 b。我们一旦定义出了每一个位置向量的重要性,我们可以计算出 context vector 为:

另一个网络在第三小节进行详细的介绍。整个 DARQN model 是通过最小化序列损失函数完成训练:
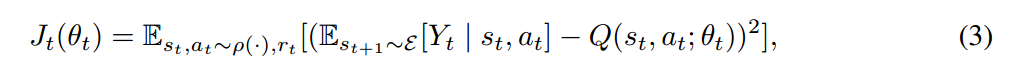
其中,$Y_t$ 是一个近似的 target value,为了优化这个损失函数,我们利用标准的 Q-learning 更新规则:
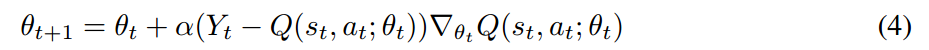
DARQN 中的 functions 都是可微分的,所以每一个参数都有梯度,整个模型可以 end-to-end 的进行训练。本文的算法也借鉴了 target network 和 experience replay 的技术。
Hard Attention:
此处的 hard attention mechanism 采样的时候要求仅仅从图像中采样一个图像 patch。
假设 $s_t$ 从环境中采样的时候,受到了 attention policy 的影响,attention network g 的softmax layer 给出了带参数的类别分布(categorical distribution)。然后,在策略梯度方法,策略参数的更新可以表示为:

其中 $R_t$ 是将来的折扣的损失。为了估计这个值,另一个网络 $G_t = Linear(h_t)$ 才引入进来。这个网络通过朝向 期望值 $Y_t$ 进行网络训练。Attention network 参数最终的更新采用如下的方式进行:

其中 $G_t - Y_t$ 是advantage function estimation。
作者提供了源代码:https://github.com/5vision/DARQN
实验部分:
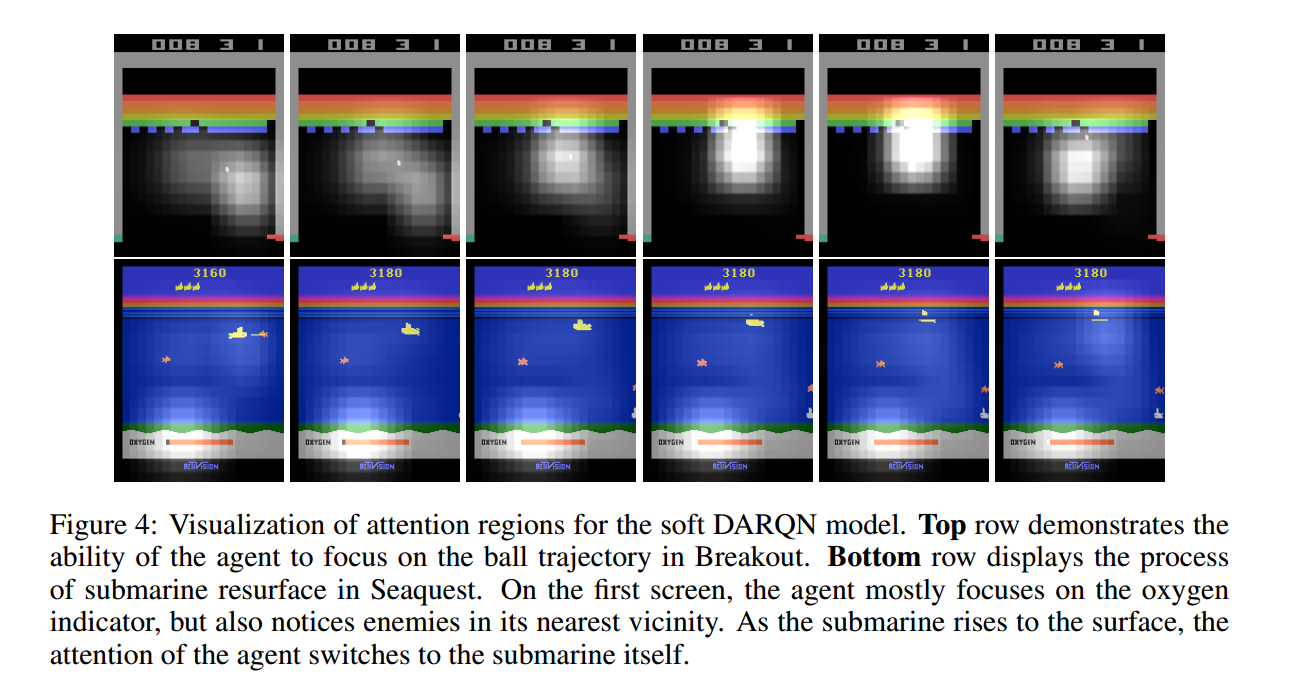
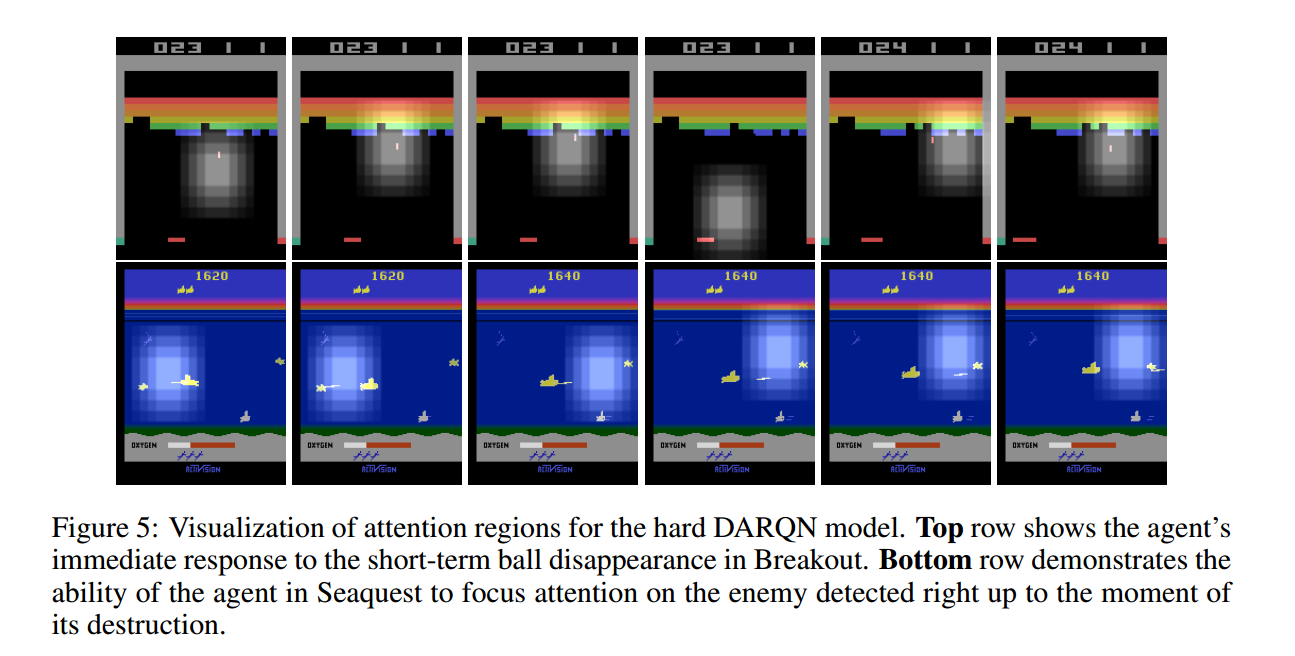
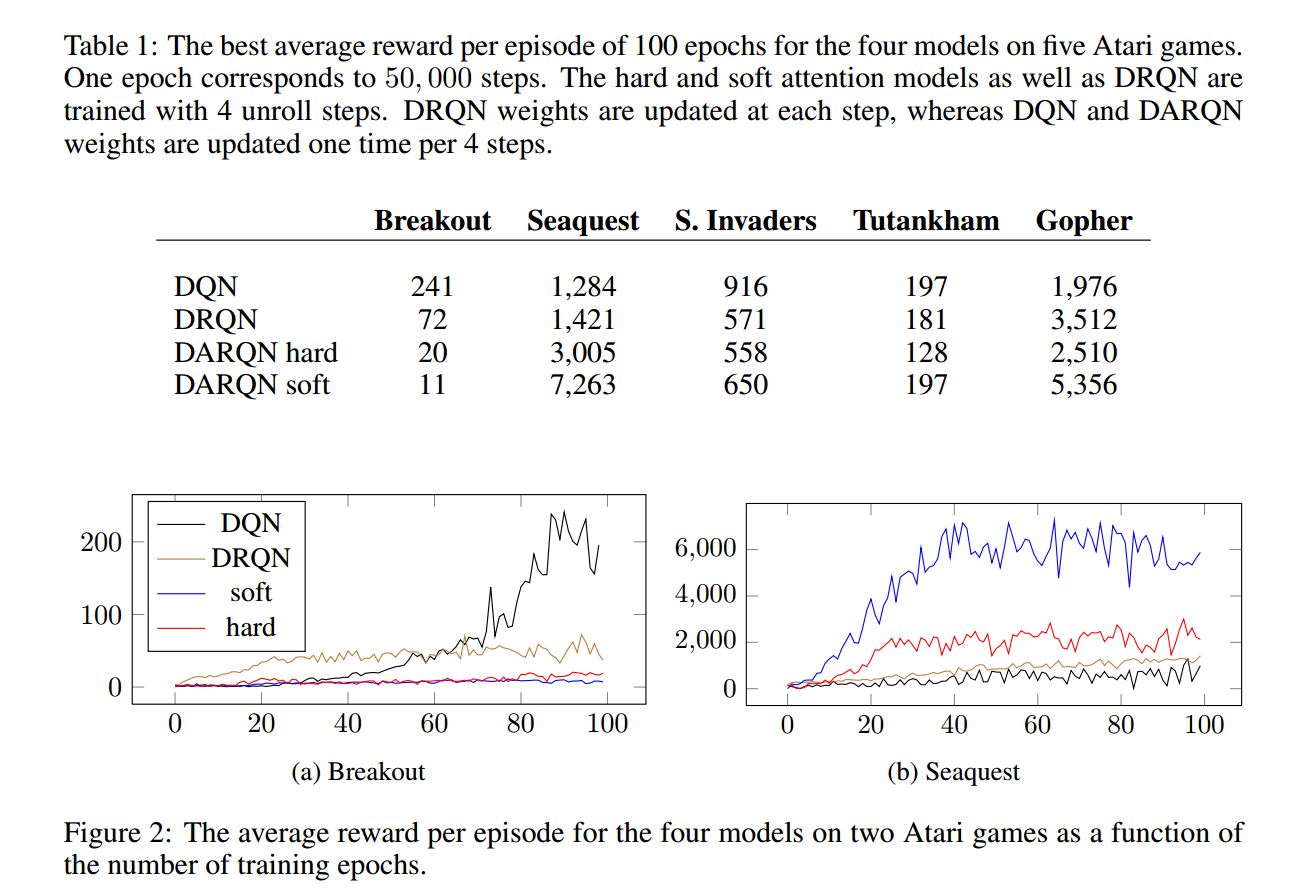

总结:
论文笔记之:Deep Attention Recurrent Q-Network的更多相关文章
- 论文笔记:ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks
ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks2018-03-05 11:13:05 ...
- 论文笔记 《Maxout Networks》 && 《Network In Network》
论文笔记 <Maxout Networks> && <Network In Network> 发表于 2014-09-22 | 1条评论 出处 maxo ...
- 论文笔记——A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding
论文<A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding> Prunin ...
- 论文笔记:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning NIPS18_tracking Type:Tracking-By-Detection 本篇论文地主 ...
- 论文笔记之:RATM: RECURRENT ATTENTIVE TRACKING MODEL
RATM: RECURRENT ATTENTIVE TRACKING MODEL ICLR 2016 本文主要内容是 结合 RNN 和 attention model 用来做目标跟踪. 其中模型的组成 ...
- 论文笔记之:Attention For Fine-Grained Categorization
Attention For Fine-Grained Categorization Google ICLR 2015 本文说是将Ba et al. 的基于RNN 的attention model 拓展 ...
- 论文笔记:Deep feature learning with relative distance comparison for person re-identification
这篇论文是要解决 person re-identification 的问题.所谓 person re-identification,指的是在不同的场景下识别同一个人(如下图所示).这里的难点是,由于不 ...
- 论文笔记:Deep Residual Learning
之前提到,深度神经网络在训练中容易遇到梯度消失/爆炸的问题,这个问题产生的根源详见之前的读书笔记.在 Batch Normalization 中,我们将输入数据由激活函数的收敛区调整到梯度较大的区域, ...
- 论文笔记 Pose-driven Deep Convolutional Model for Person Re-identification_tianqi_2017_ICCV
1. 摘要 为解决姿态变化的问题,作者提出Pose-driven-deep convolutional model(PDC),结合了global feature跟local feature, 而loc ...
随机推荐
- 用Python编写的第一个回测程序
用Python编写的第一个回测程序 2016-08-06 def savfig(figureObj, fn_prefix1='backtest8', fn_prefix2='_1_'): import ...
- golang strings
package main import s "strings" //别名 import ( "fmt" ) var p = fmt.Println func m ...
- HBase之集群状态
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.*; import org.apache.had ...
- SCCM 2007日志
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://ycrsjxy.blog.51cto.com/618627/203174 ...
- linux笔记:shell编程-正则表达式
正则表达式与通配符(正则表达式匹配字符串,是包含匹配:通配符匹配文件名,是完全匹配.): 基础正则表达式: 正则表达式示例:
- Code Simplicity–The Science of Software Development 书摘
Chapter1 Introduction That is the art and talent involved in programming—reducing complexity to simp ...
- investopedia level 2
Mispricing can be explained by the sum of the two components: true mispricing and estimation errorVe ...
- Windows Store App 插值动画
插值动画支持DoubleAnimation.ColorAnimation和PointAnimation类型的动画.其中比较常用的是DoubleAnimation动画,它可以用来控制界面元素的Doubl ...
- 困扰我多年的Connection reset问题
第一次出现:是thrift的python client去请求server,发现偶尔出现这个问题 第二次:接入第三方的api,去请求数据时,发现一个接入方的api第一次总是报这个错,当时又没有做处理,导 ...
- iOS开发多线程篇—线程的状态
iOS开发多线程篇—线程的状态 一.简单介绍 线程的创建: self.thread=[[NSThread alloc]initWithTarget:self selector:@selector(te ...