ElasticSearch 2 (10) - 在ElasticSearch之下(深入理解Shard和Lucene Index)
摘要
从底层介绍ElasticSearch Shard的内部原理,以及回答为什么使用ElasticSearch有必要了解Lucene的内部工作方式?
了解ElasticSearch API的代价
- 构建快速的搜索应用
- 不要任何时候都commit
- 何时使用Stored Fields和Document Values
- Lucene可能不是一个合适的工具
了解索引的存储方式
- term vector是索引大小的1/2
- 我移除了20%的文件,但是索引占用空间并未发生任何变化
版本
elasticsearch版本: elasticsearch-2.2.0
内容
索引
毫不夸张的说,如果不了解Lucene索引的工作方式,可以说完全不了解Lucene,对于ElasticSearch更是如此。
可以使搜索更快速
- 可以冗余信息
- 根据查询(queries)建立索引
在更新速度与查询速度间妥协
需要注意的是搜索的应用场景
- Grep vs. 全文检索(full-text indexing)
- Prefix queries vs. edge n-grams
- Phrase queries vs shingles
如果是进行前缀查询(右模糊匹配)或者是短语查询(phrase queries),ElasticSearch可能不合适,需要做特殊的优化。(在2.x中,ES对以上应用场景都有支持,具体使用方式可以参考:Search in Depth)
Lucene索引的速度
创建索引
以两个简单的文件为例:Lucene in action和Databases。
假设Lucene in action里有单词
{index, term, data, Lucene}Databases里有单词
{sql, index, data}树形结构(Tree structure)
对于range query有序
查询的时间复杂度为O(log(n))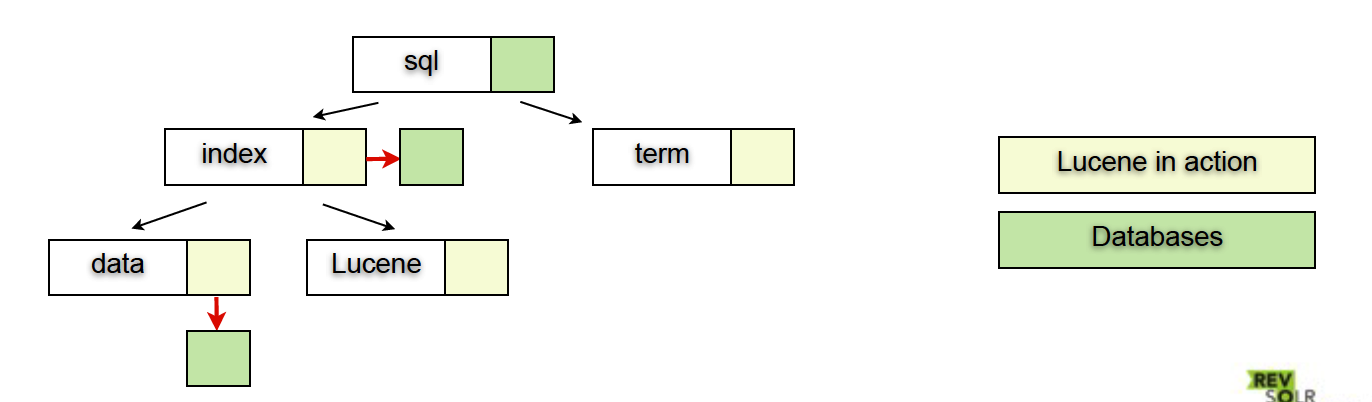
一般的关系型数据库大致结构可能是上面这样的一颗B、B+树,但是Lucene是另外一种存储结构。
倒排索引(或反向索引Inverted Index)
对于Lucene来说,其主要的存储结构是一个反向索引,它是一个数组,数组里面是一个有序的数据字典。
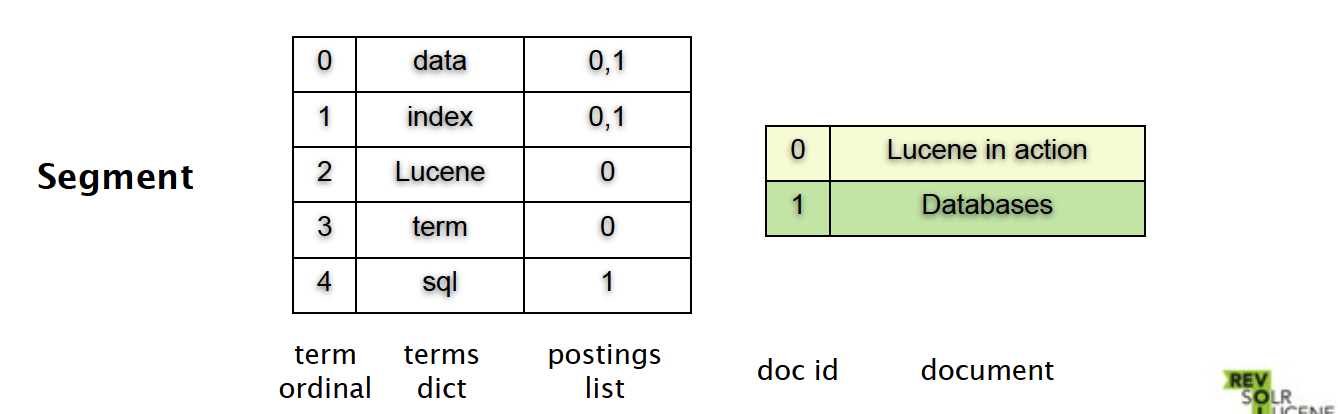
这样一个存储结构存在与Lucene的Segment里。
- term ordinal —— 是一个词的序号
- term dict —— 是词的内容
- postings list —— 存放包含词的文件的id序列
- doc id —— 是每个文件的唯一标识
- document —— 存放每个文件的内容
这两种结构的一个重要区别是:在增加或删除文件时,系统会树形结构频繁操作,这个结构是一直变化的,而反向索引可以维持不变(Immutable)。
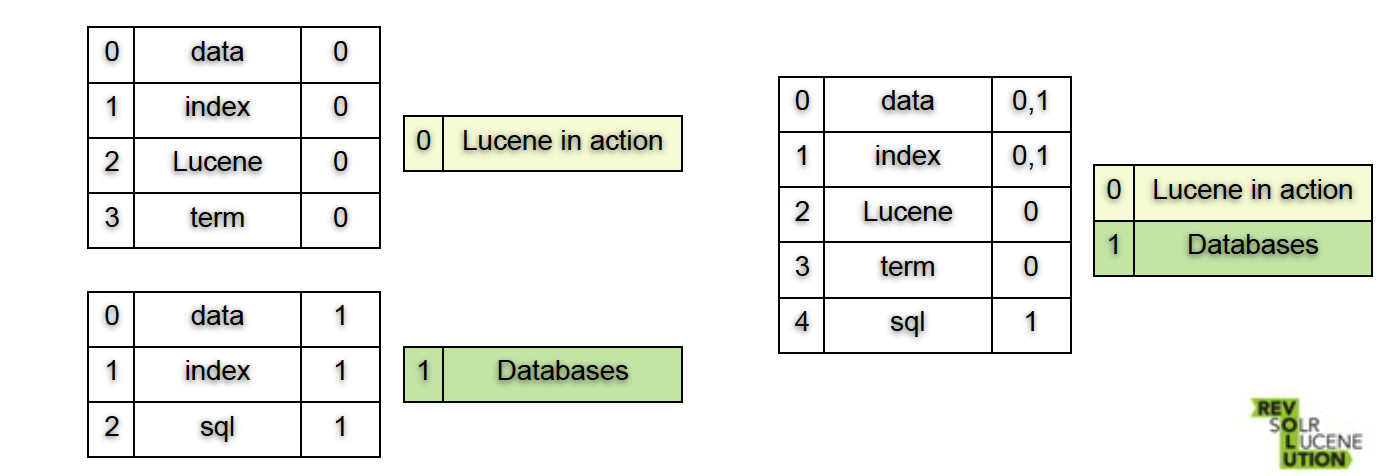
插入?
- 插入 即 创建一个新的segment
当有很多segment时,系统会合并segment
这个过程本质上是一个merge sort,做的事情就是- 连接文件
- 合并字典
- 合并postings lists
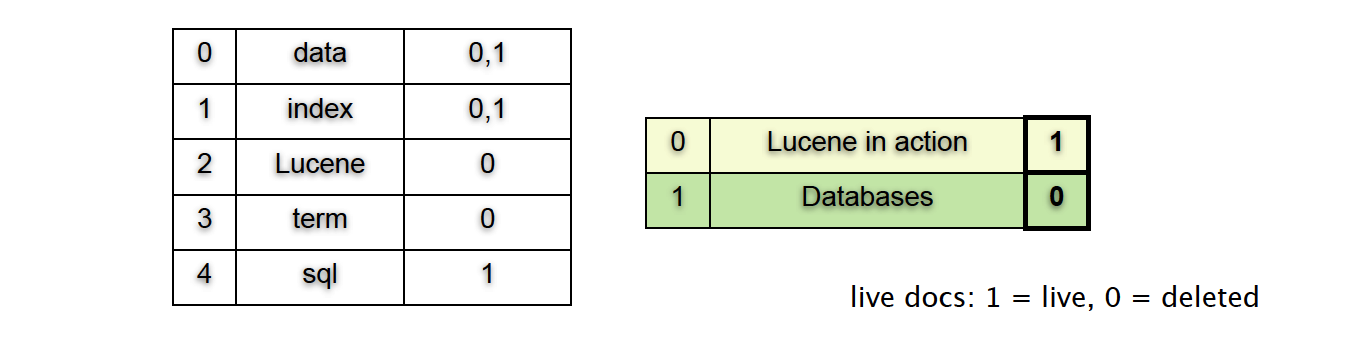
删除?
- 删除要做的只是置一个标志位
- 搜索及merge的时候系统会忽略被删除的文件
- 当有很多删除发生时,系统会自动运行merge
- 被标记为已删除的文件会在merge完成后回收其所占用的存储空间
孰优孰劣?
当更新一个文件的时候,我们实际上是创建了一个新的segment,因此
- 单个文件的更新代价高昂,我们需要使用bulk更新
- 所有的写操作都是顺序执行的
Segments永远不会被修改
- 文件系统缓存友好
- 不会出现锁的问题
Terms 高度去重
- 节省大量高频词所占用的空间
文件本身由唯一序号标识
- 跨API通信的时候非常方便
- Lucene可以在单个Query下使用多个索引index
Terms 由唯一序号标识
- 对于排序非常重要,只需要比较数字,而非字符串
- 对于faceting(分面搜索)非常重要
Lucene Index的强大之处(Index intersection)
很多数据库不支持同时使用多个索引,但是Lucene支持
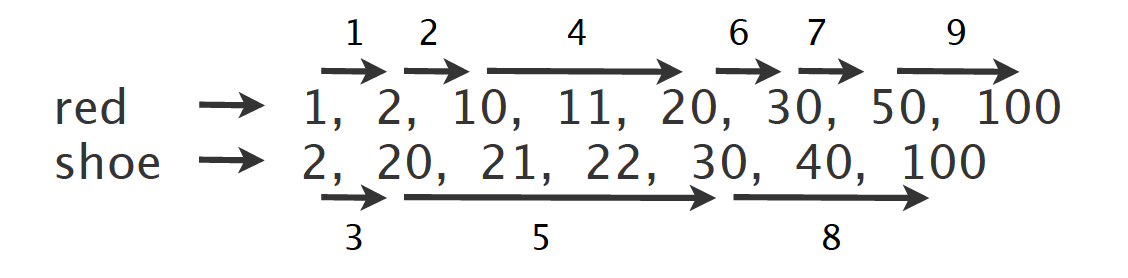
Lucene为postings lists 维护一个skip list(Wiki),如果要搜索如上例子中的“red shoe”,系统参考skip list里的信息可以跳跃检索(“leap-frog”)
对于很多数据库,它们会挑选最主要的索引(most selective),而忽略其他
关于详细的index intersection算法以及如何使用skip list的可以参照(nlp.standford.edu)
更多索引
术语向量(Term vectors)
- 为每个文件都会创建一个反向索引(Inverted Index)
- 适用场景:搜索更相似的内容
- 也可以用作高亮搜索结果
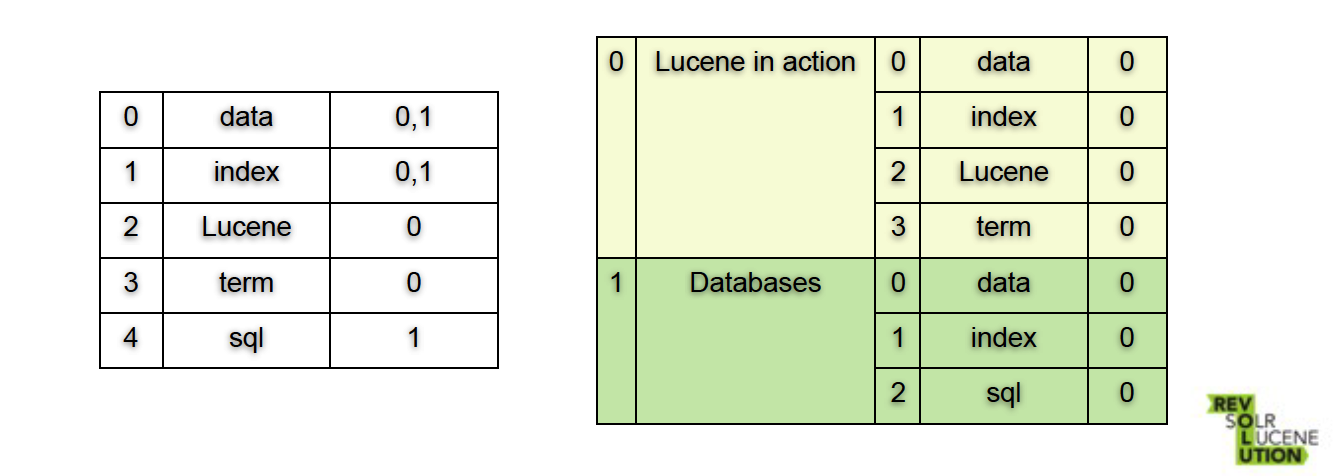
文件值(Document Values)
- 以文件字段为单位进行列式存储
- 适用场景:排序、权重记分

有序(集合)文件值
文件有序、字段有序
- 单字段:排序
- 多字段:分面搜索

分面搜索(Faceting)
分面是指事物的多维度属性。例如一本书包含主题、作者、年代等分面。而分面搜索是指通过事物的这些属性不断筛选、过滤搜索结果的方法。可以将分面搜索看成搜索和浏览的结合。分面搜索作为一种有效的搜索方式,已经被用在电子商务、音乐、旅游等多个方面。
例如,谷歌音乐的挑歌页面,将歌曲分为节奏、声调、音色、年代、流派等分面
根据文件与搜索匹配的情况计数
- 例如,电商网站根据衣服的款式、衣长、尺码、颜色等分面。
简单(naive)方案
- 利用哈希表计数(value to count)
- O(#docs) ordinal 查找
- O(#doc) value 查找
Lucene方案
- 哈希表(ord to count)
- 最后统计值
- O(#docs) ordinal 查找
- O(#values) value 查找
因为ordinal是密集的,所以可以简单用数组array来表示。
如何使用API?
ElasticSearch高级API 都是基于Lucene API构建的,这些基础的API包括:
-----------------------------------------------------------------------------------------------
API | 用途 | 方法
-----------------------------------------------------------------------------------------------
Inverted index | Term -> doc ids, positions, offsets | AtomicReader.fields
-----------------------------------------------------------------------------------------------
Stored fields | Summaries of search results | IndexReader.document
-----------------------------------------------------------------------------------------------
Live docs | Ignoring deleted docs | AtomicReader.liveDocs
-----------------------------------------------------------------------------------------------
Term vectors | More like this | IndexReader.termVectors
-----------------------------------------------------------------------------------------------
Doc values/Norms | Sorting/faceting/scoring | AtomicReader.get*Values
-----------------------------------------------------------------------------------------------小结
数据有四份重复,只是结构各不相同
- 绝不是浪费空间
- 感谢immutable使数据易于管理
Stored Fields和Document Values
两种结构为不同的使用场景优化
- 少量文件获取多个字段:Stored Fields
- 大量文件获取少量字段:Document Values
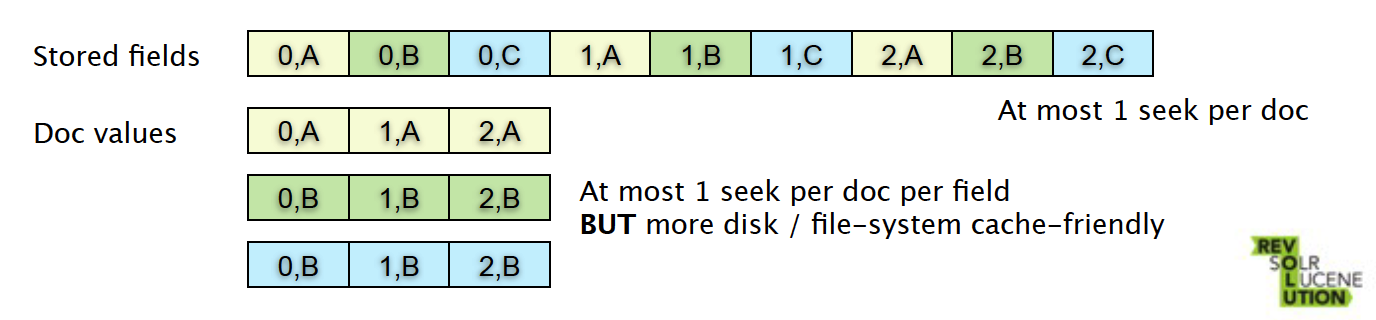
文件格式的秘密
不能忘的规则
保存文件的句柄
不要为每个字段每个文件使用文件
避免磁盘寻址
磁盘寻址的时间大概为~10ms
不要忽略文件系统的缓存
随机访问小文件还是可以的
使用轻压缩
- 更少I/O
- 更小索引
- 文件系统缓存友好
编码解码
- 文件格式依赖与编码解码
默认的编码格式已经优化内存与速度之间的关系
不要使用RAMDirectory、MemoryPostingsFormat、MemoryDocValuesFormat。
详细信息参照
http://lucene.apache.org/core/4_5_1/core/org/apache/lucene/codecs/packagesummary.
html
合适的压缩技术
Bit packing / vlnt encoding
- postings lists
- numeric doc values
LZ4
- code.google.com/p/lz4
- 轻量压缩算法
- Stored fields, term vectors
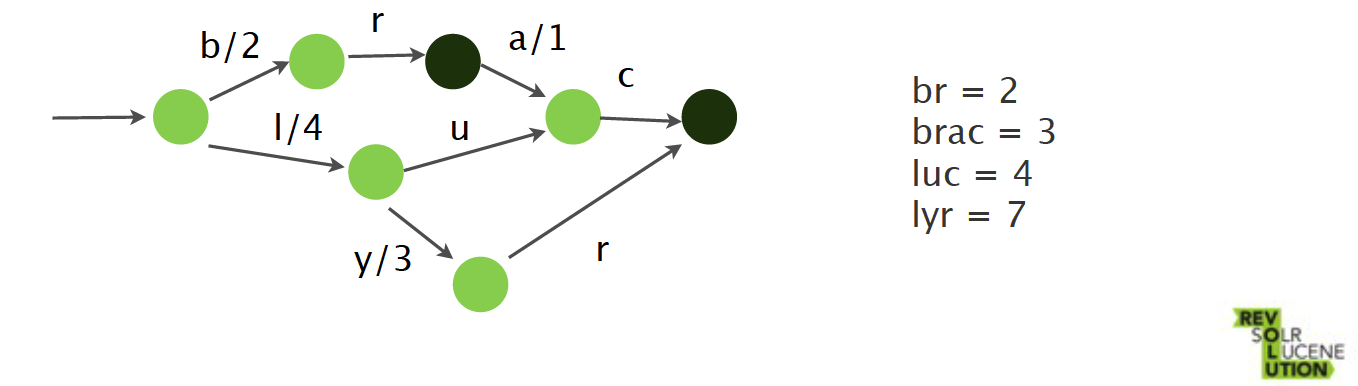
FSTs
- Map<string, ?="">
- 键共享前缀(prefix)和后缀(suffix)
- terms index
TermQuery的背后
Terms Index
在索引中查找相应的词
- 在内存中FST存储了词的前缀prefix
- 提供词在字典中的偏移量
- 在不存在时可以快速失败
Terms Dictionary
跳到字典偏移的位置
压缩是基于共享前缀的,与“BlockTree term dict”类似
顺序读取直到找到特定的Term

Postings List
- 跳到postings list偏移量对应位置
用改进的FOR(Frame of Reference)进行增量编码
- 增量编码
- 将块拆分为N=128个值的大小
- 每个块使用位压缩(bit packing)
- 如果有剩余文档,使用vlnt压缩

Stored Fields
对一个子集的doc id,索引存于内存中
高效内存(monotonic)压缩
二分查找
字段
顺序存储
使用16KB块存储压缩
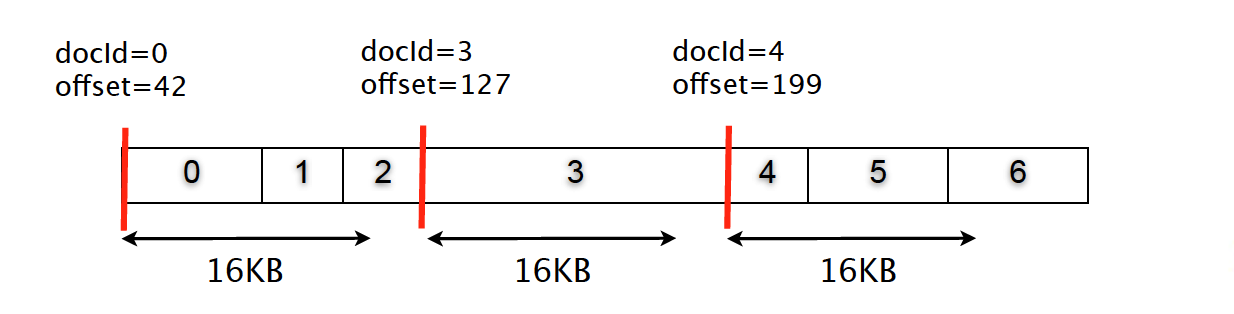
查询过程小结
- 每个字段2次磁盘寻址
每个文件1次磁盘寻址(Stored Fields)
terms dict/postings lists都在文件系统的缓存中
此时不会发生磁盘寻址
“脉冲”优化
- 对于唯一的term,postings list存储在Terms dict中
- 1次磁盘寻址
- 永远作为主键
性能

上图中系统性能出现两次下降,可能的情况是
索引增长超过文件系统缓存的大小
Stored Fields不再全部存储于缓存中
Terms dict/Postings lists不全在缓存中
参考
参考来源:
SlideShare: What is in a Lucene index?
Youtube: What is in a Lucene index? Adrien Grand, Software Engineer, Elasticsearch
SlideShare: Elasticsearch From the Bottom Up
Youtube: Elasticsearch from the bottom up
Standford Edu: Faster postings list intersection via skip pointers
StackOverflow: how an search index works when querying many words?
StackOverflow: how does lucene calculate intersection of documents so fast?
Lucene and its magical indexes
结束
ElasticSearch 2 (10) - 在ElasticSearch之下(深入理解Shard和Lucene Index)的更多相关文章
- ElasticSearch 2 (9) - 在ElasticSearch之下(图解搜索的故事)
ElasticSearch 2 (9) - 在ElasticSearch之下(图解搜索的故事) 摘要 先自上而下,后自底向上的介绍ElasticSearch的底层工作原理,试图回答以下问题: 为什么我 ...
- Windows 10 安装ElasticSearch(2)- MSI安装ElasticSearch和安装Kibana
翻阅上篇文章:Windows 10 安装 ElasticSearch 上次写的是下载Zip包安装的,在下载页面 发现有 MSI (BETA) 的下载可选项.了解之后发现MSI安装也值得尝试. MSI安 ...
- elasticsearch系列一:elasticsearch(ES简介、安装&配置、集成Ikanalyzer)
一.ES简介 1. ES是什么? Elasticsearch 是一个开源的搜索引擎,建立在全文搜索引擎库 Apache Lucene 基础之上 用 Java 编写的,它的内部使用 Lucene 做索引 ...
- ElasticSearch实战系列二: ElasticSearch的DSL语句使用教程---图文详解
前言 在上一篇中介绍了ElasticSearch集群和kinaba的安装教程,本篇文章就来讲解下 ElasticSearch的DSL语句使用. ElasticSearch DSL 介绍 Elastic ...
- ElasticSearch实战系列三: ElasticSearch的JAVA API使用教程
前言 在上一篇中介绍了ElasticSearch实战系列二: ElasticSearch的DSL语句使用教程---图文详解,本篇文章就来讲解下 ElasticSearch 6.x官方Java API的 ...
- ElasticSearch实战系列四: ElasticSearch理论知识介绍
前言 在前几篇关于ElasticSearch的文章中,简单的讲了下有关ElasticSearch的一些使用,这篇文章讲一下有关 ElasticSearch的一些理论知识以及自己的一些见解. 虽然本人是 ...
- ElasticSearch实战系列五: ElasticSearch的聚合查询基础使用教程之度量(Metric)聚合
Title:ElasticSearch实战系列四: ElasticSearch的聚合查询基础使用教程之度量(Metric)聚合 前言 在上上一篇中介绍了ElasticSearch实战系列三: Elas ...
- ElasticSearch实战系列十: ElasticSearch冷热分离架构
前言 本文主要介绍ElasticSearch冷热分离架构以及实现. 冷热分离架构介绍 冷热分离是目前ES非常火的一个架构,它充分的利用的集群机器的优劣来实现资源的调度分配.ES集群的索引写入及查询速度 ...
- ElasticSearch实战系列十一: ElasticSearch错误问题解决方案
前言 本文主要介绍ElasticSearch在使用过程中出现的各种问题解决思路和办法. ElasticSearch环境安装问题 1,max virtual memory areas vm.max_ma ...
随机推荐
- c++new/delete---9
原创博客:转载请标明出处:http://www.cnblogs.com/zxouxuewei/ C++new和delete实现原理 new 与delete是C++预定的操作符,它们一般需要配套使用 ...
- GDB中文手册
用GDB调试程序GDB概述 2使用GDB 5GDB中运行UNIX的shell程序 8在GDB中运行程序 8调试已运行的程序 两种方法: 9暂停 / 恢复程序运行 9一.设置断点(BreakPoint) ...
- 论文笔记之:Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks NIPS 2015 摘要:本文提出一种 ...
- vue.js使用详解
1.什么是vue.jsvue.js是一款数据驱动型的js框架.何为数据驱动型?html视图层定义模板,vue定义数据.html和vue数据,通过标签id关联. 2.vue.js引入<script ...
- Hadoop的I/O操作
HDFS的数据完整性 检验数据是否损坏最常见的措施是:在数据第一次引入系统时计算校验和并在数据通过一个不可靠通道进行传输时再次计算校验和,这样就能发现数据是否被损坏.HDFS会对写入的所有数据计算校验 ...
- 【java】 java 解压tar.gz读取内容
package com.xwolf.stat.util; import com.alibaba.druid.util.StringUtils; import com.alibaba.fastjson. ...
- view
把view添加到某个视图的虾面 [self.superview insertSubview:smallCircle belowSubview:self]; // 返回两个数的根 return sqrt ...
- C++模板元编程 - 挖新坑的时候探索到了模板元编程的新玩法
C++真是一门自由的语言,虽然糖没有C#那么多,但是你想要怎么写,想要实现什么,想要用某种编程范式或者语言特性,它都会提供. 开大数运算类的新坑的时候(又是坑),无意中需要解决一个需求:大数类需要分别 ...
- haproxy+keepalived实现高可用负载均衡
软件负载均衡一般通过两种方式来实现:基于操作系统的软负载实现和基于第三方应用的软负载实现.LVS就是基于Linux操作系统实现的一种软负载,HAProxy就是开源的并且基于第三应用实现的软负载. HA ...
- Flash插件地址
Flash插件地址: http://get.adobe.com/cn/flashplayer/存档版本地址: http://helpx.adobe.com/flash-player/kb/archiv ...