11 Clever Methods of Overfitting and how to avoid them
11 Clever Methods of Overfitting and how to avoid them
Overfitting is the bane of Data Science in the age of Big Data. John Langford reviews "clever" methods of overfitting, including traditional, parameter tweak, brittle measures, bad statistics, human-loop overfitting, and gives suggestions and directions for avoiding overfitting.

By John Langford (Microsoft, Hunch.net)
(Gregory Piatetsky: I recently came across this classic post from 2005 by John Langford Clever Methods of Overfitting, which addresses one of the most critical issues in Data Science. The problem of overfitting is a major bane of big data, and the issues described below are perhaps even more relevant than before. I have made several of these mistakes myself in the past. John agreed to repost it in KDnuggets, so enjoy and please comment if you find new methods)
“Overfitting” is traditionally defined as training some flexible representation so that it memorizes the data but fails to predict well in the future. For this post, I will define overfitting more generally as over-representing the performance of systems. There are two styles of general overfitting: over-representing performance on particular datasets and (implicitly) over-representing performance of a method on future datasets.
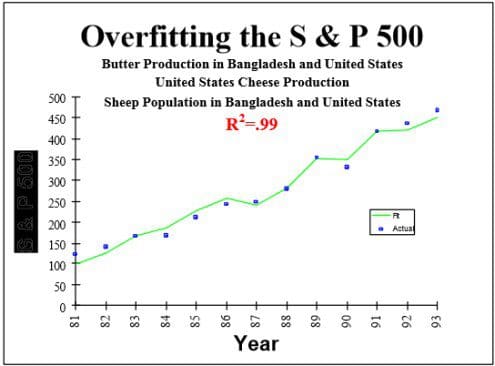
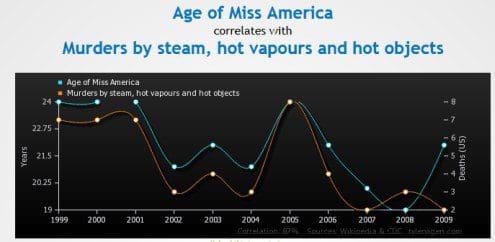
We should all be aware of these methods, avoid them where possible, and take them into account otherwise. I have used “reproblem” and “old datasets”, and may have participated in “overfitting by review”—some of these are very difficult to avoid.
1. Traditional overfitting: Train a complex predictor on too-few examples.
Remedy:
- Hold out pristine examples for testing.
- Use a simpler predictor.
- Get more training examples.
- Integrate over many predictors.
- Reject papers which do this.
2. Parameter tweak overfitting: Use a learning algorithm with many parameters. Choose the parameters based on the test set performance.
For example, choosing the features so as to optimize test set performance can achieve this.
Remedy: same as above
3. Brittle measure: Use a measure of performance which is especially brittle to overfitting.
Examples: “entropy”, “mutual information”, and leave-one-out cross-validation are all surprisingly brittle. This is particularly severe when used in conjunction with another approach.
Remedy: Prefer less brittle measures of performance.
4. Bad statistics: Misuse statistics to overstate confidences.
One common example is pretending that cross validation performance is drawn from an i.i.d. gaussian, then using standard confidence intervals. Cross validation errors are not independent. Another standard method is to make known-false assumptions about some system and then derive excessive confidence.
Remedy: Don’t do this. Reject papers which do this.
5. Choice of measure: Choose the best of Accuracy, error rate, (A)ROC, F1, percent improvement on the previous best, percent improvement of error rate, etc.. for your method. For bonus points, use ambiguous graphs.
This is fairly common and tempting.
Remedy: Use canonical performance measures. For example, the performance measure directly motivated by the problem.
6. Incomplete Prediction: Instead of (say) making a multiclass prediction, make a set of binary predictions, then compute the optimal multiclass prediction.
Sometimes it’s tempting to leave a gap filled in by a human when you don’t otherwise succeed.
Remedy: Reject papers which do this.
7. Human-loop overfitting: Use a human as part of a learning algorithm and don’t take into account overfitting by the entire human/computer interaction.
This is subtle and comes in many forms. One example is a human using a clustering algorithm (on training and test examples) to guide learning algorithm choice.
Remedy: Make sure test examples are not available to the human.
8. Data set selection: Chose to report results on some subset of datasets where your algorithm performs well.
The reason why we test on natural datasets is because we believe there is some structure captured by the past problems that helps on future problems. Data set selection subverts this and is very difficult to detect.
Remedy: Use comparisons on standard datasets. Select datasets without using the test set. Good Contest performance can’t be faked this way.
9. Reprobleming: Alter the problem so that your performance improves.
 Remedy: For example, take a time series dataset and use cross validation. Or, ignore asymmetric false positive/false negative costs. This can be completely unintentional, for example when someone uses an ill-specified UCI dataset.
Remedy: For example, take a time series dataset and use cross validation. Or, ignore asymmetric false positive/false negative costs. This can be completely unintentional, for example when someone uses an ill-specified UCI dataset.
Remedy: Discount papers which do this. Make sure problem specifications are clear.
10. Old datasets: Create an algorithm for the purpose of improving performance on old datasets.
After a dataset has been released, algorithms can be made to perform well on the dataset using a process of feedback design, indicating better performance than we might expect in the future. Some conferences have canonical datasets that have been used for a decade…
Remedy: Prefer simplicity in algorithm design. Weight newer datasets higher in consideration. Making test examples not publicly available for datasets slows the feedback design process but does not eliminate it.
11. Overfitting by review: 10 people submit a paper to a conference. The one with the best result is accepted.
This is a systemic problem which is very difficult to detect or eliminate. We want to prefer presentation of good results, but doing so can result in overfitting.
Remedy:
- Be more pessimistic of confidence statements by papers at high rejection rate conferences.
- Some people have advocated allowing the publishing of methods with poor performance. (I have doubts this would work.)
I have personally observed all of these methods in action, and there are doubtless others.
Selected comments on John's post:
Negative results:
- Aleks Jakulin: How about an index of negative results in machine learning? There’s a Journal of Negative Results in other domains:Ecology & Evolutionary Biology, Biomedicine, and there is Journal of Articles in Support of the Null Hypothesis. A section on negative results in machine learning conferences? This kind of information is very useful in preventing people from taking pathways that lead nowhere: if one wants to classify an algorithm into good/bad, one certainly benefits from unexpectedly bad examples too, not just unexpectedly good examples.
- John Langford I visited the workshop on negative results at NIPS 2002. My impression was that it did not work well. The difficulty with negative results in machine learning is that they are too easy. For example, there are a plethora of ways to say that “learning is impossible (in the worst case)”. On the applied side, it’s still common for learning algorithms to not work on simple-seeming problems. In this situation, positive results (this works) are generally more valuable than negative results (this doesn’t work).
Brittle measures
- What do you mean by “brittle”? Why is mutual information brittle?
- John Langford : What I mean by brittle: Suppose you have a box which takes some feature values as input and predicts some probability of label 1 as output. You are not allowed to open this box or determine how it works other than by this process of giving it inputs and observing outputs.
Let x be an input.
Let y be an output.
Assume (x,y) are drawn from a fixed but unknown distribution D.
Let p(x) be a prediction.For classification error I(|y – p(x)| < 0.5) you can prove a theorem of the rough form:
for all D, with high probability over the draw of m examples independently from D, expected classification error rate of the box with respect to D is bounded by a function of the observations.What I mean by “brittle” is that no statement of this sort can be made for any unbounded loss (including log-loss which is integral to mutual information and entropy). You can of course open up the box and analyze its structure or make extra assumptions about D to get a similar but inherently more limited analysis.
The situation with leave-one-out cross validation is not so bad, but it’s still pretty bad. In particular, there exists a very simple learning algorithm/problem pair with the property that the leave-one-out estimate has the variance and deviations of a single coin flip. Yoshua Bengio and Yves Grandvalet in fact proved that there is no unbiased estimator of variance. The paper that I pointed to above shows that for K-fold cross validation on m examples, all moments of the deviations might only be as good as on a test set of size $m/K$.
I’m not sure what a ‘valid summary’ is, but leave-one-out cross validation can not provide results I trust, because I know how to break it.
I have personally observed people using leave-one-out cross validation with feature selection to quickly achieve a severe overfit.
Related:
11 Clever Methods of Overfitting and how to avoid them的更多相关文章
- Using SetWindowRgn
Using SetWindowRgn Home Back To Tips Page Introduction There are lots of interesting reasons for cre ...
- Java Hashtable的实现
先附源码: package java.util; import java.io.*; /** * This class implements a hash table, which maps keys ...
- HashMap和HashTable到底哪不同?
HashMap和HashTable有什么不同?在面试和被面试的过程中,我问过也被问过这个问题,也见过了不少回答,今天决定写一写自己心目中的理想答案. 代码版本 JDK每一版本都在改进.本文讨论的Has ...
- Android Studio上面最好用的插件
转载:http://www.jianshu.com/p/d76b60a3883d 在开发过程中,本人用的最爽的就是代码生成的插件,帮助我们自动完成大量重复简单的工作.个人也觉得代码自动生成工具是最值得 ...
- 编写更好的C#代码
引言 开发人员总是喜欢就编码规范进行争论,但更重要的是如何能够在项目中自始至终地遵循编码规范,以保证项目代码的一致性.并且团队中的所有人都需要明确编码规范所起到的作用.在这篇文章中,我会介绍一些在我多 ...
- Java性能提示(全)
http://www.onjava.com/pub/a/onjava/2001/05/30/optimization.htmlComparing the performance of LinkedLi ...
- Gradle cookbook(转)
build.gradle apply plugin:"java" [compileJava,compileTestJava,javadoc]*.options*.encoding ...
- The Go Programming Language. Notes.
Contents Tutorial Hello, World Command-Line Arguments Finding Duplicate Lines A Web Server Loose End ...
- 00-Unit_Common综述-RecyclerView封装
自学安卓也有一年的时间了,与代码相伴的日子里,苦乐共存.能坚持到现在确实已见到了"往日所未曾见证的风采".今2018年4月2日,决定用一个案例:Unit_Common,把安卓基础的 ...
随机推荐
- 【BZOJ 2594】【WC 2006】水管局长数据加强版
离线后倒过来做,这样就跟魔法森林差不多了,缩边为点就可以统计边的权值了. 1A真是爽,可惜常数炸上了天,这是滥用stl容器和无脑link,cut的后果 #include<map> #inc ...
- JS搞基指南----延迟对象入门提高资料整理
JavaScript的Deferred是比较高大上的东西, 主要的应用还是主ajax的应用, 因为JS和nodeJS这几年的普及, 前端的代码越来越多, 各种回调套回调再套回调实在太让人崩溃, ...
- DIRECTORY_SEPARATOR:PHP 系统分隔符常量
今天在nginx部署项目,在浏览器输入http://127.0.0.2/index.php/system/category/?action=list 老是提示error nginx配置没有问题,下了其 ...
- apache ab压力测试
今天提到压力测试,想起以前看到的ab,于是又重新查找了下资料,并记录了下. ab命令会创建很多的并发访问线程,模拟多个访问者同时对某一URL地址进行访问. 它的测试目标是基于URL的,因此,既可以用来 ...
- Spark Shell & Spark submit
Spark 的 shell 是一个强大的交互式数据分析工具. 1. 搭建Spark 2. 两个目录下面有可执行文件: bin 包含spark-shell 和 spark-submit sbin 包含 ...
- 【BZOJ-2648&2716】SJY摆棋子&天使玩偶 KD Tree
2648: SJY摆棋子 Time Limit: 20 Sec Memory Limit: 128 MBSubmit: 2459 Solved: 834[Submit][Status][Discu ...
- struts2 CVE-2012-0838 S2-007 Remote Code Execution && Hotfix
catalog . Description . Effected Scope . Exploit Analysis . Principle Of Vulnerability . Patch Fix 1 ...
- Andirod——网络连接(HttpURLConnection)
Android中使用HTTP协议访问网络的方法主要分为两种: 使用HttpURLConnection 使用HttpClient 本文主要内容是HttpURLConnection的使用. HttpURL ...
- HDU 5920 Ugly Problem
说起这道题, 真是一把辛酸泪. 题意 将一个正整数 \(n(\le 10^{1000})\) 分解成不超过50个回文数的和. 做法 构造. 队友UHC提出的一种构造方法, 写起来比较方便一些, 而且比 ...
- POJ 2431 Expedition(优先队列、贪心)
题目链接: 传送门 Expedition Time Limit: 1000MS Memory Limit: 65536K 题目描述 驾驶一辆卡车行驶L单位距离.最开始有P单位的汽油.卡车每开1 ...