python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息
PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器。
用pyspider的demo页面创建了一个爬虫,写一个正则表达式抓取多牛网站上特定的URL,很容易就得到想要的结果了,可以非常方便分析抓取页面里面的内容
binux/pyspider · GitHub
https://github.com/binux/pyspider
http://docs.pyspider.org/en/latest/
Dashboard - pyspider
http://demo.pyspider.org/
ztest - Debugger - pyspider
http://demo.pyspider.org/debug/ztest
那个demo网站还可以直接在线保存自己创建编辑过的代码的
看了pyspider的源码web端是用tornado框架做的,使用 PhantomJS 渲染带 JS 的页面
首页 - Binuxの杂货铺
http://blog.binux.me/
这个是作者的中文博客,有中文的教程文章
=================================
先上直观的效果图:
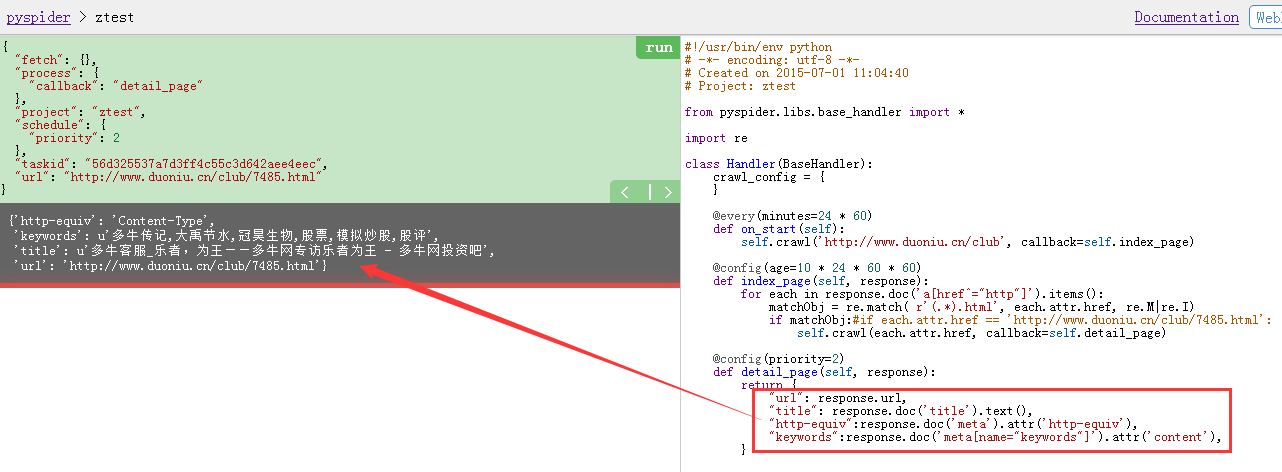

下面是相关代码:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2015-07-01 11:04:40
# Project: ztest from pyspider.libs.base_handler import * import re class Handler(BaseHandler):
crawl_config = {
} @every(minutes=24 * 60)
def on_start(self):
self.crawl('http://www.duoniu.cn/club', callback=self.index_page) @config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
matchObj = re.match( r'(.*).html', each.attr.href, re.M|re.I)
if matchObj:
self.crawl(each.attr.href, callback=self.detail_page) @config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
"http-equiv":response.doc('meta').attr('http-equiv'),
"keywords":response.doc('meta[name="keywords"]').attr('content'),
} ===========================================
{
"fetch": {},
"process": {
"callback": "index_page"
},
"project": "ztest",
"schedule": {
"age": 864000
},
"taskid": "0a7f73fcbef54f29761aeeff6cc2ab68",
"url": "http://www.duoniu.cn/club/"
}
=============================================
{
"fetch": {},
"process": {
"callback": "detail_page"
},
"project": "ztest",
"schedule": {
"priority": 2
},
"taskid": "56d325537a7d3ff4c55c3d642aee4eec",
"url": "http://www.duoniu.cn/club/7485.html"
}
================================================
{'http-equiv': 'Content-Type',
'keywords': u'多牛传记,大禹节水,冠昊生物,股票,模拟炒股,股评',
'title': u'多牛客服_乐者,为王——多牛网专访乐者为王 - 多牛网投资吧',
'url': 'http://www.duoniu.cn/club/7485.html'}
新增一个抓取政府新闻的代码:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2015-10-09 13:51:35
# Project: xinwen
#http://demo.pyspider.org/debug/xinwen from pyspider.libs.base_handler import * import re class Handler(BaseHandler):
crawl_config = {
} @every(minutes=24 * 60)
def on_start(self):
self.crawl('http://www.gov.cn/xinwen/', callback=self.index_page) @config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
matchObj = re.match( r'(.*).htm', each.attr.href, re.M|re.I)
if matchObj:
self.crawl(each.attr.href, callback=self.detail_page) @config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
"http-equiv":response.doc('meta').attr('http-equiv'),
"keywords":response.doc('meta[name="keywords"]').attr('content'),
}
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容的更多相关文章
- python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容
python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容 Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖 ...
- python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例
python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例 新浪爱彩双色球开奖数据URL:http://zst.aicai.com/ssq/openInfo/ 最终输出结果格 ...
- python3.4学习笔记(二十三) Python调用淘宝IP库获取IP归属地返回省市运营商实例代码
python3.4学习笔记(二十三) Python调用淘宝IP库获取IP归属地返回省市运营商实例代码 淘宝IP地址库 http://ip.taobao.com/目前提供的服务包括:1. 根据用户提供的 ...
- python3.4学习笔记(二十六) Python 输出json到文件,让json.dumps输出中文 实例代码
python3.4学习笔记(二十六) Python 输出json到文件,让json.dumps输出中文 实例代码 python的json.dumps方法默认会输出成这种格式"\u535a\u ...
- python3.4学习笔记(二十五) Python 调用mysql redis实例代码
python3.4学习笔记(二十五) Python 调用mysql redis实例代码 #coding: utf-8 __author__ = 'zdz8207' #python2.7 import ...
- python3.4学习笔记(十一) 列表、数组实例
python3.4学习笔记(十一) 列表.数组实例 #python列表,数组类型要相同,python不需要指定数据类型,可以把各种类型打包进去#python列表可以包含整数,浮点数,字符串,对象#创建 ...
- python3.4学习笔记(十) 常用操作符,条件分支和循环实例
python3.4学习笔记(十) 常用操作符,条件分支和循环实例 #Pyhon常用操作符 c = d = 10 d /= 8 #3.x真正的除法 print(d) #1.25 c //= 8 #用两个 ...
- java之jvm学习笔记十三(jvm基本结构)
java之jvm学习笔记十三(jvm基本结构) 这一节,主要来学习jvm的基本结构,也就是概述.说是概述,内容很多,而且概念量也很大,不过关于概念方面,你不用担心,我完全有信心,让概念在你的脑子里变成 ...
- python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法
python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法window安装redis,下载Redis的压缩包https://git ...
随机推荐
- JAVA创建并写入内容到xlsx文件
首先需要在web项目中导入jxl.jar 包 //action中代码 public String downloadReport(){ String path = System.getPr ...
- 使用powershell提权的一些技巧
原文:http://fuzzysecurity.com/tutorials/16.html 翻译:http://www.myexception.cn/windows/1752546.html http ...
- Java面试题大全(一)
JAVA相关基础知识 1.面向对象的特征有哪些方面 1.抽象: 抽象就是忽略一个主题中与当前目标无关的那些方面,以便更充分地注意与当前目标有关的方面.抽象并不打算了解全部问题,而只是选择其中的一部分, ...
- Asp.net点击按钮弹出文件夹选择框的实现(网页)
本文地址:http://www.cnblogs.com/PiaoMiaoGongZi/p/4092112.html 在Asp.net网站实际的开发中,比如:需要实现点击一个类似于FileUpload的 ...
- 使用MyBatis Generator生成DAO
虽然MyBatis很方便,但是想要手写全部的mapper还是很累人的,好在MyBatis官方推出了自动化工具,可以根据数据库和定义好的配置直接生成DAO层及以下的全部代码,非常方便. 需要注意的是,虽 ...
- 实现memcpy
memcpy的原型: SYNOPSIS #include <string.h> void *memcpy(void *dest, const void *src, size_t n); D ...
- MBR(Master Boot Record)主引导记录分析
root@ubuntu1404:/home/chen# fdisk -l /dev/sda1 Disk /dev/sda1: MB, bytes heads, sectors/track, cylin ...
- Run P4 without P4factory - A Simple Example In Tutorials. -2 附 simple_router源码
/* Copyright 2013-present Barefoot Networks, Inc. Licensed under the Apache License, Version 2.0 (th ...
- python - ConfigParser
ConfigParse 作用是解析配置文件. 配置文件格式如下 [test1]num1: 10[test2]num1: 35 配置文件两个概念section和option, 在这个例子中第一个sect ...
- 杂-lowbit
int lowbit(int x){ )); } int lowbit(int x){ return x&-x; }