python生成汉字图片字库
最近做文档识别方面的项目,做汉字识别需要建立字库,在网上找了各种OCR,感觉都不好,这方面的技术应该比较成熟了,OCR的软件很多,但没有找到几篇有含金量量的论文,也没有看到哪位大牛公开字库,我用pygame渲染字体来生成字库,也用PIL对整齐的图片进行切割得到字库。
pygame渲染字体来生成字库
用pygame渲染字体我参考的这篇文章,根据GB2323-8标准,汉语中常用字3500个,覆盖了99.7%的使用率,加上次常用共6763个,覆盖99.99%的使用率。先生成一个字体图片,从网上找来3500个常用汉字,对每一个子按字体进行渲染:
def pasteWord(word):
'''输入一个文字,输出一张包含该文字的图片'''
pygame.init()
font = pygame.font.Font(os.path.join("./fonts", "a.ttf"), 22)
text = word.decode('utf-8')
imgName = "E:/dataset/chinesedb/chinese/"+text+".png"
paste(text,font,imgName) def paste(text,font,imgName,area = (0, -9)):
'''根据字体,将一个文字黏贴到图片上,并保存'''
im = Image.new("RGB", (32, 32), (255, 255, 255))
rtext = font.render(text, True, (0, 0, 0), (255, 255, 255))
sio = StringIO.StringIO()
pygame.image.save(rtext, sio)
sio.seek(0)
line = Image.open(sio)
im.paste(line, area)
#im.show()
im.save(imgName)
渲染图片次数多总是报错,对于渲染失败的文字我又重试,最终得到了一个包含3510字(加上10个数字)的字库:
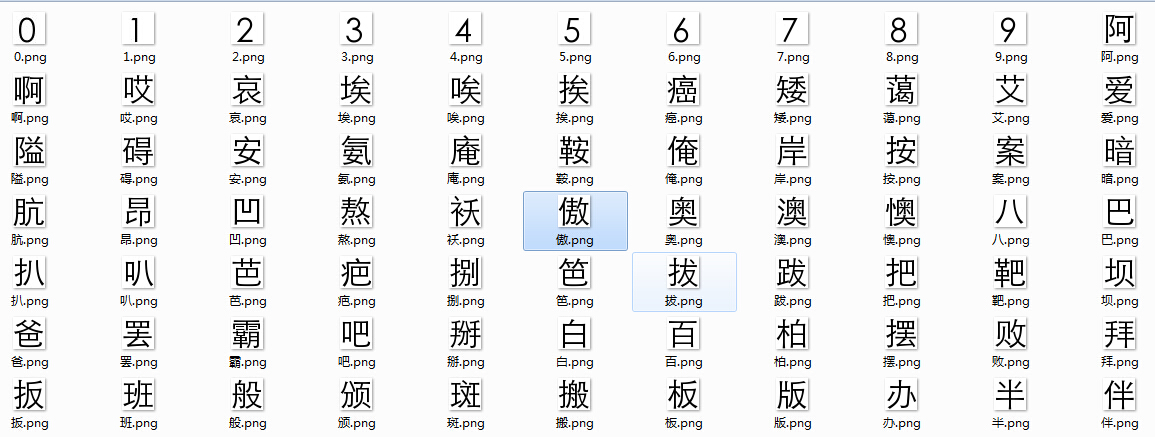
字符分割生成字库
另外一种办法就是把3500个字放在word排好,然后转PDF保存成图片,像下面这样:

密密麻麻的字,但非常整齐,不需要什么图片处理算法,只要找到空白的行和列,按行和列就可以进行切割,切割出来也好,只要保存有序切割,切出来的图片依然可以与字对应,下面是切割的代码:
#!encoding=utf-8
import Image
import os def yStart(grey):
m,n = grey.size
for j in xrange(n):
for i in xrange(m):
if grey.getpixel((i,j)) == 0:
return j
def yEnd(grey):
m,n = grey.size
for j in xrange(n-1,-1,-1):
for i in xrange(m):
if grey.getpixel((i,j)) == 0:
return j def xStart(grey):
m,n = grey.size
for i in xrange(m):
for j in xrange(n):
if grey.getpixel((i,j)) == 0:
return i
def xEnd(grey):
m,n = grey.size
for i in xrange(m-1,-1,-1):
for j in xrange(n):
if grey.getpixel((i,j)) == 0:
return i
def xBlank(grey):
m,n = grey.size
blanks = []
for i in xrange(m):
for j in xrange(n):
if grey.getpixel((i,j)) == 0:
break
if j == n-1:
blanks.append(i)
return blanks def yBlank(grey):
m,n = grey.size
blanks = []
for j in xrange(n):
for i in xrange(m):
if grey.getpixel((i,j)) == 0:
break
if i == m-1:
blanks.append(j)
return blanks def getWordsList():
f = open('3500.txt')
line = f.read().strip()
wordslist = line.split(' ')
f.close()
return wordslist count = 0
wordslist = []
def getWordsByBlank(img,path):
'''根据行列的空白取图片,效果不错'''
global count
global wordslist
grey = img.split()[0]
xblank = xBlank(grey)
yblank = yBlank(grey)
#连续的空白像素可能不止一个,但我们只保留连续区域的第一个空白像素和最后一个空白像素,作为文字的起点和终点
xblank = [xblank[i] for i in xrange(len(xblank)) if i == 0 or i == len(xblank)-1 or not (xblank[i]==xblank[i-1]+1 and xblank[i]==xblank[i+1]-1)]
yblank = [yblank[i] for i in xrange(len(yblank)) if i == 0 or i == len(yblank)-1 or not (yblank[i]==yblank[i-1]+1 and yblank[i]==yblank[i+1]-1)]
for j in xrange(len(yblank)/2):
for i in xrange(len(xblank)/2):
area = (xblank[i*2],yblank[j*2],xblank[i*2+1]+32,yblank[j*2]+32)#这里固定字的大小是32个像素
#area = (xblank[i*2],yblank[j*2],xblank[i*2+1],yblank[j*2+1])
word = img.crop(area)
word.save(path+wordslist[count]+'.png')
count += 1
if count >= len(wordslist):
return def getWordsFormImg(imgName,path):
png = Image.open(imgName,'r')
img = png.convert('')
grey = img.split()[0]
#先剪出文字区域
area = (xStart(grey)-1,yStart(grey)-1,xEnd(grey)+2,yEnd(grey)+2)
img = img.crop(area)
getWordsByBlank(img,path) def getWrods():
global wordslist
wordslist = getWordsList()
imgs = ["l1.png","l2.png","l3.png"]
for img in imgs:
getWordsFormImg(img,'words/') if __name__ == "__main__":
getWrods()
切出来的字的效果也很好的:
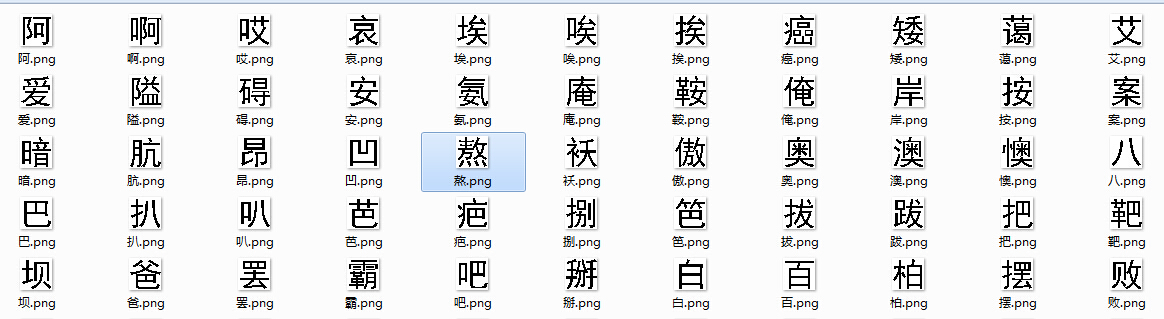
自己对这图像处理本来就不熟悉,用的都是土包子的方法。汉字的识别难度是比较大的,对应整齐的图片,采样DTW对字库求相似项,效果还不错,但用扫描仪、相机拍下来的文章切割处理后,效果很差。我用了BP神经网络,但3500个汉字相当于3500个类,这个超多类别的分类问题,BP也很难应付,主要是训练数据太少,手里只有一份字库。
如果您有什么好的方法识别图片汉字的方法,希望给与我分享,谢谢!
python生成汉字图片字库的更多相关文章
- python 生成随机图片验证码
1.安装pillow模块 pip install pillow (1)创建图片 from PIL import Image #定义使用Image类实例化一个长为400px,宽为400px,基于RGB的 ...
- python生成测试图片
直接代码 import cv2.cv as cv saveImagePath = 'E:/ScreenTestImages/' colorRed = [0,0,255] colorGreen = [0 ...
- Python数据展示 - 生成表格图片
前言 前一篇文章介绍了推送信息到企业微信群里,其中一个项目推送的信息是使用Python自动生成的表格,本文来讲讲如何用Python生成表格图片. 选一个合适库 Python最大的优点就是第三方库丰富, ...
- python生成随机图形验证码
使用python生成随机图片验证码,需要使用pillow模块 1.安装pillow模块 pip install pillow 2.pillow模块的基本使用 1.创建图片 from PIL impor ...
- python 将png图片格式转换生成gif动画
先看知乎上面的一个连接 用Python写过哪些[脑洞大开]的小工具? https://www.zhihu.com/question/33646570/answer/157806339 这个哥们通过爬气 ...
- [Python] 将视频转成ASCII符号形式、生成GIF图片
一.简要说明 简述:本文主要展示将视频转成ASCII符号形式展示出来,带音频. 运行环境:Win10/Python3.5. 主要模块: PIL.numpy.shutil. [PIL]: 图像处理 [n ...
- Python(三) PIL, Image生成验证图片
Python(三) PIL, Image生成验证图片 安装好PIL,开始使用. 在PyCharm中新建一个文件:PIL_Test1.py 1 # PIL 应用练习 2 # 3 # import PIL ...
- 012. asp.net生成验证码图片(汉字示例/字母+数字)
protected void Page_Load(object sender, EventArgs e) { //生成验证码图片的基本步骤 string checkCode = "新年快乐& ...
- Python | 一键生成九宫格图片
一键生成九宫格图片 首先我们准备几张图片: 将代码文件放在放置图片的地方,用软件打开: 点击运行,在当前目录下会生成一个文件夹: 打开新生成的文件夹: 打开对应图片的名称文件夹: 如果不想图片被分成9 ...
随机推荐
- 初识Go
意外关注到一位牛人的微信,提到了2014年他推荐的编程语言是Go.于是乎饶有兴趣的淘了一本书<Go语言程序设计>,学习起来. 第一章的练习题我的答案如下: // Copyright © 2 ...
- CMPP错误码说明
与中国移动代码的对应关系. MI::zzzzSMSC返回状态报告的状态值为EXPIREDMJ:zzzzSMSC返回状态报告的状态值为DELETEDMK:zzzzSMSC返回状态报告的状态值为UNDEL ...
- Linux umount设备时出现device is busy解决方法
在Linux中,有时使用umount命令去卸载LV或文件时,可能出现umount: xxx: device is busy的情况,如下案例所示 [root@DB-Server u06]# vgdisp ...
- 如何阻止h5body的滑动
// 禁止 document.body.style.overflow = 'hidden'; function _preventDefault(e) { e.preventDefault(); } w ...
- Java设计模式 - 代理模式
1.什么是代理模式: 为另一个对象提供一个替身或占位符以访问这个对象. 2.代理模式有什么好处: (1)延迟加载 当你需要从网络上面查看一张很大的图片时,你可以使用代理模式先查看它的缩略图看是否是自己 ...
- Java api 入门教程 之 JAVA的文件操作
I/O类使用 由于在IO操作中,需要使用的数据源有很多,作为一个IO技术的初学者,从读写文件开始学习IO技术是一个比较好的选择.因为文件是一种常见的数据源,而且读写文件也是程序员进行IO编程的一个基本 ...
- linux 查看静态库,动态库是32位还是64位
动态库: file xxx.so 静态库 objdump -a xxx.a
- c++11 新特性之lambda表达式
写过c#之后,觉得c#里的lambda表达式和delegate配合使用,这样的机制用起来非常爽.c++11也有了lambda表达式,形式上有细小的差异.形式如下: c#:(input paramete ...
- [转]backbone.js 示例 todos
本文转自:http://www.css88.com/doc/backbone/examples/todos/index.html <!DOCTYPE html> <html lang ...
- C#基础---扩展方法的应用
最近对扩展方法比较感兴趣,就看了看资料,记录一下扩展方法的几种方法. 一. 扩展方法的基本使用: Note: 1. 扩展方法必须在静态类中, 2 扩展方法必须声明静态方法,3 扩展方法里面不能调用其 ...