Selenium2+python自动化31-生成测试报告
前言
最近小伙伴们总有一些测试报告的问题,网上的一些资料生成报告的方法,我试了都不行,完全生成不了,不知道他们是怎么生成的,同样的代码,有待研究。
今天小编写一下可以生成测试报告的方法。个人觉得也是最方便,最省事的,可批量执行测试用例,也比较容易理解的方法。另外一种用遍历的方法,小编在这边就不介绍了,有点麻烦,而且不可批量执行测试用例。
一、下载HTMLTestRunner.py
HTMLTestRunner 是 Python 标准库的 unittest 模块的一个扩展。它生成易于使用的 HTML 测试报告。HTMLTestRunner 是在 BSD 许可证下发布。
下载 地址:http://tungwaiyip.info/software/HTMLTestRunner.html(或者在我们群里下载)
Windows :将下载的文件放入...\Python27\Lib 目录下
二、生成报告
下面还是以百度为例,baidu.py代码如下:
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchAttributeException
import unittest,time,re
import HTMLTestRunner
class Baidu(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = "http://www.baidu.com/"
self.verificationErrors = []
self.accept_next_alert = True
def test_baidu_search(self):
u"""百度搜索"""
driver = self.driver
driver.get(self.base_url + '/')
driver.find_element_by_id("kw").send_keys("selenium webdriver")
driver.find_element_by_id("su").click()
time.sleep(2)
driver.close()
def test_baidu_set(self):
u"""百度设置"""
driver = self.driver
#进入搜索设置页
driver.get(self.base_url + '/gaoji/preferences.html')
#设置每页搜索结果为 20 条
m=driver.find_element_by_name("NR")
m.find_element_by_xpath("//option[@value='20']").click()
time.sleep(2)
#保存设置的信息
driver.find_element_by_xpath("/html/body/form/div/input").click()
time.sleep(2)
driver.switch_to_alert().accept()
def tearDown(self):
self.driver.quit()
self.assertEqual([],self.verificationErrors)
if __name__ == "__main__":
unittest.main()
下面我们在上面baidu.py的目录下新建一个.py,用来执行测试用例集和生成测试报告。
代码如下:
#coding=utf-8
import unittest
#这里需要导入测试文件
import baidu
import HTMLTestRunner
testunit=unittest.TestSuite()
#将测试用例加入到测试容器(套件)中
testunit.addTest(unittest.makeSuite(baidu.Baidu)) #baidu.Baidu中的baidu为用例所在的.py文件的名称,Baidu为测试用例集的名称
#定义个报告存放路径,支持相对路径。
filename= "D:\\python\\report\\"+ u"测试报告正常" +"result.html"
fp = open(filename,"wb")
runner =HTMLTestRunner.HTMLTestRunner(stream=fp,title=u'测试报告',description=u'用例执行情况:')
#执行测试用例
runner.run(testunit)
执行完毕后,进入报告存放的路径,打开后如图:
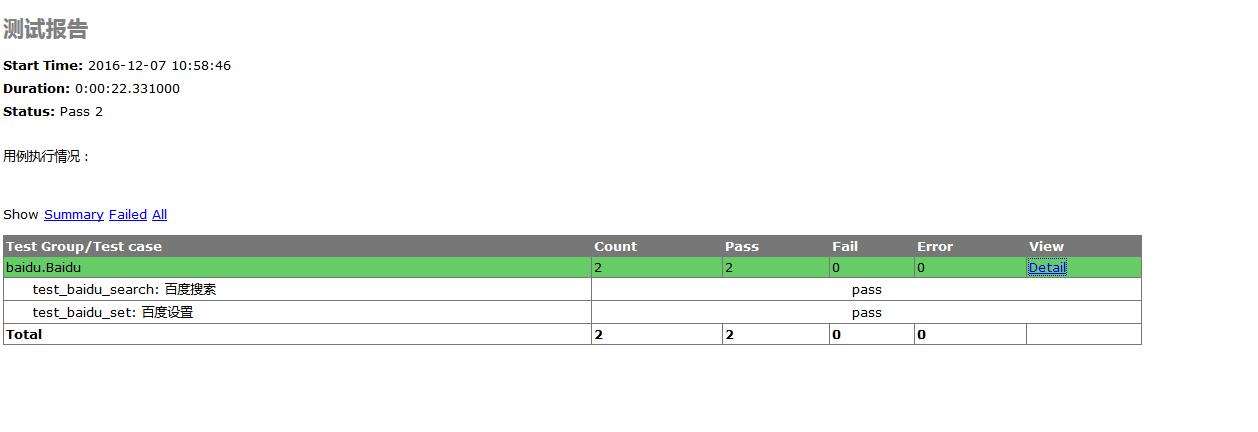
定义报告的路径还有一种方法也可以的,生成的html文件直接在该.py文件目录下,fp = file("my_report.html", "wb"),小伙伴们可以尝试下。
好了,今天就介绍到这边了,如果小伙伴们有什么建议或者想法的,欢迎给小编反馈。
后面会写一些优化测试报告的,希望小伙伴们关注,点赞!
在学习过程中有遇到疑问的,可以加selenium(python+java) QQ群交流:232607095
Selenium2+python自动化31-生成测试报告的更多相关文章
- Selenium2+python自动化54-unittest生成测试报告(HTMLTestRunner)
前言 批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLT ...
- Selenium2+python自动化54-unittest生成测试报告(HTMLTestRunner)【转载】
前言 批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLT ...
- Selenium2+python自动化31-生成测试报告【转载】
前言 最近小伙伴们总有一些测试报告的问题,网上的一些资料生成报告的方法,我试了都不行,完全生成不了,不知道他们是怎么生成的,同样的代码,有待研究. 今天小编写一下可以生成测试报告的方法.个人觉得也是最 ...
- Python自动化 unittest生成测试报告(HTMLTestRunner)03
批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTest ...
- Selenium3+python自动化011-unittest生成测试报告(HTMLTestRunner)
批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTest ...
- Selenium2+python自动化59-数据驱动(ddt)
前言 在设计用例的时候,有些用例只是参数数据的输入不一样,比如登录这个功能,操作过程但是一样的.如果用例重复去写操作过程会增加代码量,对应这种多组数据的测试用例,可以用数据驱动设计模式,一组数据对应一 ...
- Selenium2+python自动化41-绕过验证码(add_cookie)
前言 验证码这种问题是比较头疼的,对于验证码的处理,不要去想破解方法,这个验证码本来就是为了防止别人自动化登录的.如果你能破解,说明你们公司的验证码吗安全级别不高,那就需要提高级别了. 对于验证码,要 ...
- Selenium2+python自动化59-数据驱动(ddt)【转载】
前言 在设计用例的时候,有些用例只是参数数据的输入不一样,比如登录这个功能,操作过程但是一样的.如果用例重复去写操作过程会增加代码量,对应这种多组数据的测试用例,可以用数据驱动设计模式,一组数据对应一 ...
- Selenium2+python自动化41-绕过验证码(add_cookie)【转载】
前言 验证码这种问题是比较头疼的,对于验证码的处理,不要去想破解方法,这个验证码本来就是为了防止别人自动化登录的.如果你能破解,说明你们公司的验证码吗安全级别不高,那就需要提高级别了. 对于验证码,要 ...
随机推荐
- tomcat内存溢出 PermGen space
1. java.lang.OutOfMemoryError: PermGen space ---- PermGen space溢出. PermGen space的全称是Permanent Gene ...
- 【转】关于Block Formatting Context--BFC和IE的hasLayout
转自穆乙 http://www.cnblogs.com/pigtail/ 一.BFC是什么? BFC(Block Formatting Context)直译为“块级格式化范围”. 是 W3C CSS ...
- 54. Search a 2D Matrix && Climbing Stairs (Easy)
Search a 2D Matrix Write an efficient algorithm that searches for a value in an m x n matrix. This m ...
- Mono addin 学习笔记 4 再论数据扩展点(Data only extension point)
1. Attribute声明方式 定义扩展属性 [AttributeUsage(AttributeTargets.Assembly, AllowMultiple= true)] public clas ...
- 同一台服务器启动多个driver负载机实例
COSBench添加driver负载机 说明:Driver是COSBench测试工具中对负载机的一种标记,相当于loadrunner中的负载发生器. 在进行测试时,不管出于什么原因,我有时候就想单台服 ...
- python __init__.py用途
转自http://www.cnpythoner.com/post/2.html Python中的Module是比较重要的概念.常见的情况是,事先写好一个.py文 件,在另一个文件中需要import时, ...
- ThinkPHP 学习记录
index.php //入口文件 define('APP_DEBUG',True); //开启调试模式 define('APP_PATH','./Application/'); //定义应用目录 re ...
- Eclipse/MyEclipse怎么设置个性化代码注释模板
1.打开Eclipse/MyEclipse工具,打开或创建一个Java工程,点击菜单Window->Preferences弹出首选项设置窗口 2.展开左侧Java->Code Style- ...
- 29、shiro框架入门
1.建立测试shiro框架的项目,首先建立的项目结构如下图所示 ini文件 中的内容如下图所示 pom.xml文件中的内容如下所示 <project xmlns="http://mav ...
- C#占位符和格式化字符串
static void Main() { string c=Console.ReadLine(); string d=Console.ReadLine(); Console.WriteLine(c+& ...