ELK——安装 logstash 2.2.0、elasticsearch 2.2.0 和 Kibana 3.0
本文内容
- Elasticsearch
- logstash
- Kibana
- 参考资料
迁移到:http://www.bdata-cap.com/newsinfo/1712695.html
本文介绍安装 logstash 2.2.0 和 elasticsearch 2.2.0,操作系统环境版本是 CentOS/Linux 2.6.32-504.23.4.el6.x86_64。
安装 JDK 是必须的,一般操作系统都会有,只是版本的问题,后面会提到。
而 Kibana 只是一个用纯 JavaScript 写的前端 UI。一定要注意 Kibana 的版本,它会要求 ES 的版本。比如 Kibana 3 要求 Elasticsearch 至少 0.9.9 或更高;Kibana 4.5 要求 ES 至少 2.3.0 或更高。
假设,ELK 都位于 10.1.8.166 机器上。
Elasticsearch
Elasticsearch(简称,ES)提供 ZIP、TAR、DEB 和 RPM 包。但 Github 上提供了一个针对中文环境的 Elasticsearch-RTF,RTF 即 Ready To Fly,它是一个继承了基本插件(如服务封装、中文分词、mapper-attachments、transport-thrift、tools.carrot2 等)的并带有示例程序的可直接上手的简易工程版本,换句话说,帮你入门的。本文针对 Elasticsearch-RTF 为例。基本上,elasticsearch 解压后就能使用。
假设你已经从 Github 上下载 elasticsearch-rtf,名为 elasticsearch-master.zip,并上传到你的 Linux 服务器 /usr/local/elasticsearch目录(如果没有,就用 mkdir 命令创建一个)。
- 现在,解压,并重新命名文件夹:
[root@vcyber local]# cd /usr/local/elasticsearch
[root@vcyber local]# unzip elasticsearch-master.zip
[root@vcyber elasticsearch]# ls
elasticsearch-master elasticsearch-master.zip
[root@vcyber local]# mv elasticsearch-master elasticsearch
[root@vcyber elasticsearch]# ls
elasticsearch elasticsearch-master.zip
- 尝试运行 elasticsearch:
Linux 环境:
[root@vcyber elasticsearch]# pwd
/usr/local/elasticsearch/elasticsearch
[root@vcyber elasticsearch]# bin/elasticsearch
Windows 环境,执行相应的 .bat 文件,即 elasticsearch.bat。
但报错了:
[root@vcyber elasticsearch]# bin/elasticsearch
Exception in thread "main" java.lang.RuntimeException: Java version: Oracle Cooration 1.7.0_51 [Java HotSpot(TM) 64-Bit Server VM 24.51-b03] suffers from crical bug https://bugs.openjdk.java.net/browse/JDK-8024830 which can cause dataorruption.
Please upgrade the JVM, see http://www.elastic.co/guide/en/elasticsearch/referce/current/_installation.html for current recommendations.
If you absolutely cannot upgrade, please add -XX:-UseSuperWord to the JAVA_OPT environment variable.
Upgrading is preferred, this workaround will result in degraded performance.
at org.elasticsearch.bootstrap.JVMCheck.check(JVMCheck.java:123)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:283)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:3
Refer to the log for complete error details.
大意是:Java 运行时异常,本机版本 JDK 有 bug……让升级 JVM。如果实在不能升级,就向 JAVA_OPT 环境变量添加 -XX:-UseSuperWord 选项。
于是,看一下本机的Java 版本:
[root@vcyber elasticsearch]# java -version
java version "1.7.0_51"
Java(TM) SE Runtime Environment (build 1.7.0_51-b13)
Java HotSpot(TM) 64-Bit Server VM (build 24.51-b03, mixed mode)
[root@vcyber elasticsearch]# echo $JAVA_HOME
/usr/java/jdk1.7.0_51
[root@vcyber elasticsearch]#
版本是 1.7.0_51。再在官网查了一下,说:“Elasticsearch requires at least Java 7. Specifically as of this writing, it is recommended that you use the Oracle JDK version 1.8.0_72. Java installation varies from platform to platform so we won’t go into those details here. Oracle’s recommended installation documentation can be found on Oracle’s website. Suffice to say, before you install Elasticsearch, please check your Java version first by running (and then install/upgrade accordingly if needed):”,大意是,ES 至少要求 7,推荐使用 1.8.0_72。
- 那就删除之前的版本,按个新的吧。先删掉之前的 JDK,然后再用 yum 按个新的:
[root@vcyber elasticsearch]# yum list installed | grep java
[root@vcyber elasticsearch]# yum list installed | grep jdk
jdk.x86_64 2000:1.7.0_51-fcs installed
[root@vcyber elasticsearch]# yum -y remove jdk.x86_64
……
[root@vcyber elasticsearch]#yum -y install java-1.8.0-openjdk*
……
注意:java-1.8.0-openjdk*”,后面有个星号,即安装 java 全部相关的东西~
- 安装完成后,设置 JDK 的环境变量:
[root@vcyber elasticsearch]# export JAVA_HOME=/usr/lib/jvm/java-1.8.0
[root@vcyber elasticsearch]# export PATH=$JAVA_HOME/bin:$PATH
[root@vcyber elasticsearch]# export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
[root@vcyber elasticsearch]# java -version
openjdk version "1.8.0_71"
OpenJDK Runtime Environment (build 1.8.0_71-b15)
OpenJDK 64-Bit Server VM (build 25.71-b15, mixed mode)
[root@vcyber elasticsearch]# echo $JAVA_HOME
/usr/lib/jvm/java-1.8.0
[root@vcyber elasticsearch]#
另外,JDK 安装在了我机器的 /usr/lib/jvm 目录下,自己确认一下你的路径。你可以把环境变量的设置放到 profile 里,一劳永逸。
- 再次运行:
[root@vcyber elasticsearch]# bin/elasticsearch
Exception in thread "main" java.lang.RuntimeException: don't run elasticsearch as root.
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:93)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:144)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:285)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:35)
Refer to the log for complete error details.
[root@vcyber elasticsearch]#
- 又报错,elasticsearch 不能用 root 用户运行,那就建立一个:
[root@vcyber elasticsearch]# groupadd es
[root@vcyber elasticsearch]# useradd -g es es
[root@vcyber elasticsearch]# passwd es
Changing password for user es.
New password:
BAD PASSWORD: it is WAY too short
BAD PASSWORD: is too simple
Retype new password:
passwd: all authentication tokens updated successfully.
[root@vcyber elasticsearch]#
[root@vcyber elasticsearch]# chown -R root .
[root@vcyber elasticsearch]# chown -R es .
[root@vcyber elasticsearch]# chgrp -R es .
[root@vcyber elasticsearch]# ls -l
total 4
drwxr-xr-x 7 es es 4096 Mar 1 03:07 elasticsearch
[root@vcyber elasticsearch]#
ES 2.* 版本已经不允许用 root 用户运行了,但是 1.* 版本无所谓。
- 重新打开一个终端,用 es 用户登录,并运行 elasticsearch:
[root@vcyber ~]$ cd /usr/local/elasticsearch/elasticsearch
[root@vcyber elasticsearch]$ bin/elasticsearch
[2016-03-01 05:11:48,413][WARN ][bootstrap ] unable to install syscall filter: seccomp unavailable: CONFIG_SECCOMP not compiled into kernel, CONFIG_SECCOMP and CONFIG_SECCOMP_FILTER are needed
[2016-03-01 05:11:48,750][INFO ][node ] [Googam] version[2.1.1], pid[15042], build[40e2c53/2015-12-15T13:05:55Z]
[2016-03-01 05:11:48,750][INFO ][node ] [Googam] initializing ...
[2016-03-01 05:11:49,088][INFO ][plugins ] [Googam] loaded [elasticsearch-analysis-ik, elasticsearch-analysis-mmseg, elasticsearch-analysis-stconvert, elasticsearch-analysis-pinyin], sites []
[2016-03-01 05:11:49,121][INFO ][env ] [Googam] using [1] data paths, mounts [[/ (/dev/mapper/vg_vcyber-lv_root)]], net usable_space [26.1gb], net total_space [34.8gb], spins? [possibly], types [ext4]
[2016-03-01 05:11:51,119][INFO ][mmseg-analyzer ] [Dict Loading] chars loaded time=42ms, line=12638, on file=chars.dic
……
- 此时,在另一个终端,访问 elasticsearch:
[root@vcyber elasticsearch]# curl -X GET http://localhost:9200
{
"name" : "Captain Savage",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.1.1",
"build_hash" : "40e2c53a6b6c2972b3d13846e450e66f4375bd71",
"build_timestamp" : "2015-12-15T13:05:55Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}
[root@vcyber elasticsearch]#
ES 已经安装成功。
- 配置 ES
但此时,ES 不能通过IP访问,最好修改 config/elasticsearch.yml,配置一下 ES。
首先,找到“network.host”行,添加一行:
network.host: your id address
就能通过IP,或浏览器访问。
再找到“http.port”行,添加一行:
http.port: 9200
否则,ES 每次启动时,端口可能会变(端口被占用,ES 自己会改端口)~
如果还不能正常启动 ES,并提示端口被占用,就查看一下什么程序占用 9200 端口,kill 掉,重启 ES 就行。
我遇到的,Java 把 9200 端口占用了。
- 安装 Head 插件
Head 是一个用来监控 ES 状态的客户端插件,可以为初学用户提供很多便利,例如,使用 Head 提供的 HTTP 客户端,通过 HTTP 方式来操作 ES。
先查看你的 ES 都有哪些插件:
[root@vcyber ~]# cd /usr/local/elasticsearch/elasticsearch
[root@cyber elasticsearch]# bin/plugin list
Installed plugins in /usr/local/elasticsearch/elasticsearch/plugins:
- elasticsearch-analysis-mmseg-1.7.0
- elasticsearch-analysis-stconvert-1.6.1
- elasticsearch-analysis-pinyin-1.5.2
- elasticsearch-analysis-ik-1.7.0
[root@vcyber elasticsearch]#
大部分是关于中文分词的,没有 Head 插件。
ES 支持在线和本地安装 Head。本地安装时,从 Github 上下载 Head 插件,然后上传到你的 ES 服务器,比如,Elasticsearch/plugins 目录。
下面是在线安装:
[root@vcyber ~]# cd /usr/local/elasticsearch/elasticsearch/
[root@vcyber elasticsearch]# bin/plugin install mobz/elasticsearch-head
-> Installing mobz/elasticsearch-head...
Trying https://github.com/mobz/elasticsearch-head/archive/master.zip ...
Downloading ...................................................................................................................................................................................................................................................................................................................................................................................................................................DONE
Verifying https://github.com/mobz/elasticsearch-head/archive/master.zip checksums if available ...
NOTE: Unable to verify checksum for downloaded plugin (unable to find .sha1 or .md5 file to verify)
Installed head into /usr/local/elasticsearch/elasticsearch/plugins/head
如果命令使用的是“mobz/elasticsearch-head”,那么 ES 将自己联网从 Github 下载再安装。
但是报错了,说校验和有问题。加上“-v”选项,这次换本地安装,而且是 zip 压缩包(从 Github 上下载的),即“file:plugins/elasticsearch-head-master.zip”,再执行一下:
[root@vcyber elasticsearch]# bin/plugin install -v file:plugins/elasticsearch-head-master.zip
-> Installing from file:plugins/elasticsearch-head-master.zip...
Trying file:plugins/elasticsearch-head-master.zip ...
Downloading .........DONE
Verifying file:plugins/elasticsearch-head-master.zip checksums if available ...
NOTE: Unable to verify checksum for downloaded plugin (unable to find .sha1 or .md5 file to verify)
- Plugin information:
Name: head
Description: head - A web front end for an elastic search cluster
Site: true
Version: master
JVM: false
Installed head into /usr/local/elasticsearch/elasticsearch/plugins/head
注意:install 选项,ES 的 2.* 版本,都不带“-”横线选项,即“-install”。
注意:若是本地安装,而且,你把 Head 压缩包放到了 Elasticsearch/plugins 目录下,安装后,一定要将 Elasticsearch-head zip 压缩包删掉,否则启动 ES 时会报“不能初始化插件”错误。
[2016-03-02 07:06:16,547][WARN ][bootstrap ] unable to install syscall filter: seccomp unavailable: CONFIG_SECCOMP not compiled into kernel, CONFIG_SECCOMP and CONFIG_SECCOMP_FILTER are needed[2016-03-02 07:06:16,866][INFO ][node ] [MODAM] version[2.1.1], pid[19446], build[40e2c53/2015-12-15T13:05:55Z][2016-03-02 07:06:16,866][INFO ][node ] [MODAM] initializing...Exception in thread "main" java.lang.IllegalStateException: Unable to initialize pluginsLikely root cause: java.nio.file.FileSystemException: /usr/local/elasticsearch/elasticsearch/plugins/elasticsearch-head-master.zip/plugin-descriptor.properties: Not a directory
之后用浏览器访问 http://your ip adress:9200/_plugin/head,你就会看到如下界面:
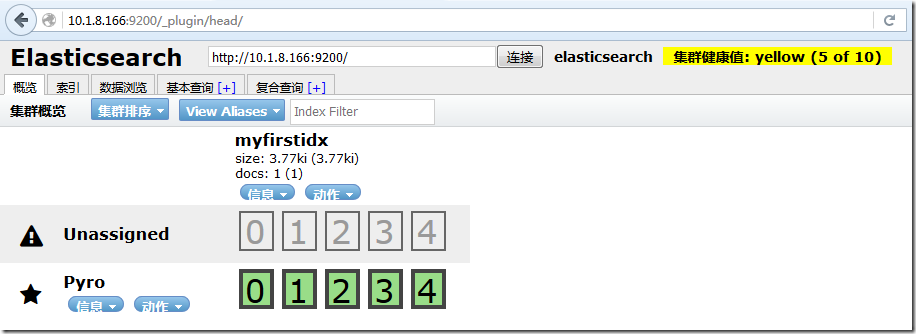
myfirestidx 是我之前通过命令行自己建的。
Elasticsearch Head 就成功安装了。
- 安装 Marvel 图形化监控插件
[root@vcyber elasticsearch]# bin/plugin install -v elasticsearch/marvel/latest
-> Installing elasticsearch/marvel/latest...
Trying http://download.elasticsearch.org/elasticsearch/marvel/marvel-latest.zip...
Downloading ................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................DONE
Installed elasticsearch/marvel/latest into /usr/local/elasticsearch/elasticsearch-1.7.1/plugins/marvel
[root@vcyber elasticsearch-1.7.1]#
我去啊~此插件收费~
- 安装 kopf 网络插件
[root@vcyber elasticsearch]# bin/plugin install -v lmenezes/elasticsearch-kopf
-> Installing lmenezes/elasticsearch-kopf...
Trying https://github.com/lmenezes/elasticsearch-kopf/archive/master.zip...
Downloading ..................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................DONE
Installed lmenezes/elasticsearch-kopf into /usr/local/elasticsearch/elasticsearch-1.7.1/plugins/kopf
[root@vcyber elasticsearch]#
虽然安装成功了,但此版本 kopf 不支持我的 ES 版本。
ES 插件地址。
logstash
logstash 提供各种安装包,包括 tar.gz,ZIP,DEB 和 RPM。另外,又提供了一个包含所有插件的压缩包——logstash-all-plugins-2.2.0.tar.gz 。本文以它为例。解压后,配置 logstash,运行即可。

- 在 /usr/local 下创建目录 logstash:
[root@vcyber local]# cd /usr/local
[root@vcyber local]# pwd
/usr/local
[root@vcyber local]# mkdir logstash
[root@vcyber local]#
- 上传 logstash 到该目录。然后,解压并配置 logstash 配置文件:
[root@vcyber local]# cd logstash
[root@vcyber logstash]# ls
logstash-all-plugins-2.2.0.tar.gz
[root@vcyber logstash]# tar zxf logstash-all-plugins-2.2.0.tar.gz
logstash-2.2.0 logstash-all-plugins-2.2.0.tar.gz
[root@vcyber logstash]# cd logstash-2.2.0
[root@vcyber logstash-2.2.0]# vi logstash.conf
[root@vcyber logstash-2.2.0]#
文件内容如下:
input{
stdin{}
}
output{
stdout{}
}
这个配置是最简单,输入是终端命令行,输出也是终端命令行。
- 运行 logstash:
[root@vcyber logstash-2.2.0]# bin/logstash agent -f logstash.conf
hello world
hello world 2
Settings: Default pipeline workers: 2
Logstash startup completed
2016-02-28T22:37:06.130Z vcyber hello world
2016-02-28T22:37:06.132Z vcyber hello world 2
logst 已经成功安装。其中,agent 表示运行Agent模式,-f 表示指定配置文件,-p 表示端口,命令行参数可以参考logstash command-lines flags。
- 另外,你可以查看 logstash 都安装了哪些插件。
[root@vcyber logstash-2.2.0]# bin/plugin list
logstash-codec-avro
logstash-codec-cef
logstash-codec-cloudfront
logstash-codec-cloudtrail
logstash-codec-collectd
logstash-codec-compress_spooler
logstash-codec-dots
logstash-codec-edn
logstash-codec-edn_lines
logstash-codec-es_bulk
logstash-codec-fluent
logstash-codec-graphite
logstash-codec-gzip_lines
logstash-codec-json
logstash-codec-json_lines
logstash-codec-line
logstash-codec-msgpack
logstash-codec-multiline
logstash-codec-netflow
logstash-codec-nmap
logstash-codec-oldlogstashjson
logstash-codec-plain
logstash-codec-rubydebug
logstash-codec-s3plain
logstash-codec-spool
logstash-filter-aggregate
logstash-filter-alter
logstash-filter-anonymize
logstash-filter-checksum
logstash-filter-cidr
logstash-filter-cipher
logstash-filter-clone
logstash-filter-collate
logstash-filter-csv
logstash-filter-date
logstash-filter-de_dot
logstash-filter-dns
logstash-filter-drop
logstash-filter-elapsed
logstash-filter-elasticsearch
logstash-filter-environment
logstash-filter-extractnumbers
logstash-filter-fingerprint
logstash-filter-geoip
logstash-filter-grok
logstash-filter-i18n
logstash-filter-json
logstash-filter-json_encode
logstash-filter-kv
logstash-filter-metaevent
logstash-filter-metricize
logstash-filter-metrics
logstash-filter-multiline
logstash-filter-mutate
logstash-filter-oui
logstash-filter-prune
logstash-filter-punct
logstash-filter-range
logstash-filter-ruby
logstash-filter-sleep
logstash-filter-split
logstash-filter-syslog_pri
logstash-filter-throttle
logstash-filter-tld
logstash-filter-translate
logstash-filter-unique
logstash-filter-urldecode
logstash-filter-useragent
logstash-filter-uuid
logstash-filter-xml
logstash-filter-zeromq
logstash-input-beats
logstash-input-cloudwatch
logstash-input-couchdb_changes
logstash-input-elasticsearch
logstash-input-eventlog
logstash-input-exec
logstash-input-file
logstash-input-fluentd
logstash-input-ganglia
logstash-input-gelf
logstash-input-gemfire
logstash-input-generator
logstash-input-github
logstash-input-graphite
logstash-input-heartbeat
logstash-input-http
logstash-input-http_poller
logstash-input-imap
logstash-input-irc
logstash-input-jdbc
logstash-input-jmx
logstash-input-kafka
logstash-input-log4j
logstash-input-lumberjack
logstash-input-meetup
logstash-input-pipe
logstash-input-puppet_facter
logstash-input-rabbitmq
logstash-input-redis
logstash-input-relp
logstash-input-rss
logstash-input-s3
logstash-input-salesforce
logstash-input-snmptrap
logstash-input-sqlite
logstash-input-sqs
logstash-input-stdin
logstash-input-stomp
logstash-input-syslog
logstash-input-tcp
logstash-input-twitter
logstash-input-udp
logstash-input-unix
logstash-input-varnishlog
logstash-input-websocket
logstash-input-wmi
logstash-input-xmpp
logstash-input-zenoss
logstash-input-zeromq
logstash-output-boundary
logstash-output-circonus
logstash-output-cloudwatch
logstash-output-csv
logstash-output-datadog
logstash-output-datadog_metrics
logstash-output-elasticsearch
logstash-output-elasticsearch-ec2
logstash-output-elasticsearch_http
logstash-output-elasticsearch_java
logstash-output-email
logstash-output-exec
logstash-output-file
logstash-output-ganglia
logstash-output-gelf
logstash-output-google_bigquery
logstash-output-google_cloud_storage
logstash-output-graphite
logstash-output-graphtastic
logstash-output-hipchat
logstash-output-http
logstash-output-influxdb
logstash-output-irc
logstash-output-juggernaut
logstash-output-kafka
logstash-output-librato
logstash-output-loggly
logstash-output-lumberjack
logstash-output-metriccatcher
logstash-output-mongodb
logstash-output-nagios
logstash-output-nagios_nsca
logstash-output-null
logstash-output-opentsdb
logstash-output-pagerduty
logstash-output-pipe
logstash-output-rabbitmq
logstash-output-redis
logstash-output-redmine
logstash-output-riemann
logstash-output-s3
logstash-output-sns
logstash-output-solr_http
logstash-output-sqs
logstash-output-statsd
logstash-output-stdout
logstash-output-stomp
logstash-output-syslog
logstash-output-tcp
logstash-output-udp
logstash-output-websocket
logstash-output-xmpp
logstash-output-zabbix
logstash-output-zeromq
logstash-patterns-core
[root@vcyber logstash-2.2.0]#
Kibana
你得搞一个 Kibana 3.0 并上传你服务器的 /usr/local/Kibana 目录下,没有建立一个,然后用 unzip 解压(github 下载的是 zip 文件)。
[root@vcyber /]# cd /usr/local/kibana/
[root@vcyber kibana]# ls
exampledata kibana-3.0 kibana-4.0 kibana-5.0
[root@vcyber kibana]#
你可以看到,我有三个版本,4.0 和 5.0 没有安装成功(总提示 node.js 报错)~Kibana 这三个主要版本差距很大~
简单介绍一下,你就知道,Kibana 的每个版本差距有多大。Logstash 早期曾经自带了一个特别简单的 Logstash-Web,用来查看 ES 数据。后来, Rashid Khan 用 PHP 写了一个更好的 Web,取名 Kibana,发布于 2011年12月11日。2012年8月19日,Rashid Khan 用 Ruby 重写了一遍,叫 Kibana 2,。因为,Logstash 也是用 Ruby 写的,所以就代替了 Logstash-Web。2014年2月,此人,用 AngularJS 又重写了一遍,(我靠,真是服了他了~),叫 Kibana 3。2014年4月,Kibana 3 停止开发,全面致力于 Kibana 4。到 2015年初,发布了用 JRuby 做后端的 beta 版,但3月正式推出时却使用 node.js 做后端。(我靠靠,服了~都被他用遍了~)
- 到其 src 目录下:
[root@vcyber kibana]# cd kibana-3.0/src
[root@vcyber src]# ls
app config.js css favicon.ico font img index.html vendor
[root@vcyber src]#
- 修改其 config.js 文件,添加对 ES 的访问。无论是看文件内容,还是看后缀名,你能猜到,就是手动去改 JavaScript 文件而已:
elasticsearch: http://10.1.8.166:9200,
我 ES 服务器地址是 10.1.8.166,注意,屁股后面的逗号,绝对是有的。如果该文件配置错了,当你访问 Kibana 时,界面什么都看不到~
接下来,把 Kibana 搞成一个 Web 站点。tomcat、Python、Nginx 都行,我暂时用 Python。只要把 Kibana 的 src 目录发布出去就行。
- 注意你当前的位置,执行如下命令,就能把 Kibana 做成一个 Web 站点:
[root@vcyber src]# pwd
/usr/local/kibana/kibana-3.0/src
[root@vcyber src]# python –m SimpleHTTPServer 8000
其中,SimpleHTTPServer 是 Python 模块名,区分大小写的;8000 是 Web 站点的端口。
这样,你就能通过 http://10.1.8.166:8000 访问 Kibana。
- 但是,页面报错了:“Connection Failed”:
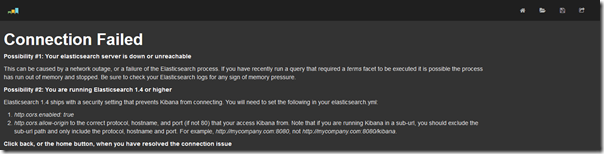
提示,Kibana 不能连接 ES。至于原因,从 ES 1.4 版本开始,它增强了安全性。写得很清楚,照着做就行(事后才知道)。~但问题是,这些具体东西,在官网没找到(我是没找到),而且连 Kibana 3.0 的文档,都已经没有了~错误信息所说的:“http.cors” 相关配置,在 Elasticsearch.yml 中,也没给出~事实上,还真是写这两个配置。
- 进入到 ES 的 config 目录:
[root@vcyber src]# cd /usr/local/elasticsearch/
[root@vcyber elasticsearch]# ls
elasticsearch-1.7.1 elasticsearch-2.2.0
[root@vcyber elasticsearch]# cd elasticsearch-1.7.1/config/
[root@vcyber config]#
我有两个 ES 版本,Kibana 访问的是 1.7 那个版本。
- 修改 Elasticsearch.yml 文件,添加如下内容:
http.cors.allow-origin: http://10.1.8.166:8000
http.cors.enabled: true
其中,http.cors.allow-origin 一行表明,谁可以访问 ES。若让所有域名都可以访问,写成 “*”~
本例写具体的 IP 地址和端口。
这样,Kibana 就可以访问 ES 了。如下图所示:
参考资料
在 CentOS/Linux 把 Kibana 3.0 部署在 Nginx 1.9.12
为调试 Logstash Grok 表达式,安装 GrokDebuger 环境
ELK——安装 logstash 2.2.0、elasticsearch 2.2.0 和 Kibana 3.0的更多相关文章
- ELK 安装Elasticsearch
章节 ELK 介绍 ELK 安装Elasticsearch ELK 安装Kibana ELK 安装Beat ELK 安装Logstash ELK栈要安装以下开源组件: Elasticsearch Ki ...
- ELK 安装与配置
ELK日志分析之安装 1.介绍: NRT elasticsearch是一个近似实时的搜索平台,从索引文档到可搜索有些延迟,通常为1秒. 集群 集群就是一个或多个节点存储数据,其中一个节点为主节点,这个 ...
- ELK 安装Beat
章节 ELK 介绍 ELK 安装Elasticsearch ELK 安装Kibana ELK 安装Beat ELK 安装Logstash Beat是数据采集工具,安装在服务器上,将采集到的数据发送给E ...
- 【Docker】:docker安装ELK(logstash,elasticsearch,kibana)
一:安装logstash 1.拉取镜像 docker pull logstash:5.6.11 2.创建目录 mkdir /docker/logstash cd /docker/logstash 3. ...
- 安装logstash,elasticsearch,kibana三件套
logstash,elasticsearch,kibana三件套 elk是指logstash,elasticsearch,kibana三件套,这三件套可以组成日志分析和监控工具 注意: 关于安装文档, ...
- 安装logstash,elasticsearch,kibana三件套(转)
logstash,elasticsearch,kibana三件套 elk是指logstash,elasticsearch,kibana三件套,这三件套可以组成日志分析和监控工具 注意: 关于安装文档, ...
- 【ELK】【docker】【elasticsearch】1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安装ik分词器
系列文章:[建议从第二章开始] [ELK][docker][elasticsearch]1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安 ...
- Centos7 之安装Logstash ELK stack 日志管理系统
一.介绍 The Elastic Stack - 它不是一个软件,而是Elasticsearch,Logstash,Kibana 开源软件的集合,对外是作为一个日志管理系统的开源方案.它可以从任何来源 ...
- ELK 安装部署实战 (最新6.4.0版本)
一.实战背景 根据公司平台的发展速度,对于ELK日志分析日益迫切.主要的需求有: 1.用户行为分析 2.运营活动点击率分析 作为上述2点需求,安装最新版本6.4.0是非常有必要的,大家可根据本人之前博 ...
随机推荐
- vim基础使用
vim的常用模式有分为命令模式,插入模式,可视模式,正常模式.本教程中,只需要用到正常模式和插入模式.二者间的切换即可以帮助你完成本指南的学习. 进入方法: vim xxx.xml 正常模式 正常模式 ...
- select 练习4
21.查询score中选学多门课程的同学中分数不是所有成绩中最高分成绩的记录. select * from score where cno in(select cno from score grou ...
- BestCoder Round #87 1001
GCD is Funny Accepts: 524 Submissions: 1147 Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 655 ...
- 2006Jam的计数法
题目描述 Description Jam是个喜欢标新立异的科学怪人.他不使用阿拉伯数字计数,而是使用小写英文字母计数,他觉得这样做,会使世界更加丰富多彩.在他的计数法中,每个数字的位数都是相同的(使用 ...
- Map:containsKey、containsValue 获取Map集合的键值的 值
get(Object key) 返回与指定键关联的值: containsKey(Object key) 如果Map包含指定键的隐射,则返回true: containsValue(Object valu ...
- 【半平面交】bzoj1038 [ZJOI2008]瞭望塔
http://m.blog.csdn.net/blog/qpswwww/44105605 #include<cstdio> #include<cmath> #include&l ...
- java 图示
java类继承关系 java流类图结构
- Valid Sudoku leetcode
Determine if a Sudoku is valid, according to: Sudoku Puzzles - The Rules. The Sudoku board could be ...
- C++网络编程 Java网络编程
C++ MFC C++ STL C++ 模板 C++ DLL C++ OpenGL C++ OSG C++ GIS (GRASS QGIS POSTGRE GDAL/OGR) ____________ ...
- android tcp协议主要函数
1 tcp_timers: 处理各种timer超时信息,关键函数tcp_xmit_timer 2 tcp_iutput: 3 tcp_output:接收方的接收窗口struct tcpcb.snd_w ...