HBase读写路径的工作机制
出处:http://wuyudong.com/1946.html
HBase 写路径工作机制
在HBase 中无论是增加新行还是修改已有的行,其内部流程都是相同的。HBase 接到命令后存下变化信息,或者写入失败抛出异常。默认情况下,执行写入时会写到两个地方:预写式日志(write-ahead log,也称HLog)和MemStore。HBase 的默认方式是把写入动作记录在这两个地方,以保证数据持久化。只有当这两个地方的变化信息都写入并确认后,才认为写动作完成。
MemStore 是内存里的写入缓冲区,HBase 中数据在永久写入硬盘之前在这里累积。当MemStore 填满后,其中的数据会刷写到硬盘,生成一个HFile。HFile 是HBase 使用的底层存储格式。HFile 对应于列族,一个列族可以有多个HFile,但一个HFile 不能存储多个列族的数据。在集群的每个节点上,每个列族有一个MemStore。
大型分布式系统中硬件故障很常见,HBase 也不例外。设想一下,如果MemStore还没有刷写,服务器就崩溃了,内存中没有写入硬盘的数据就会丢失。HBase 的应对办法是在写动作完成之前先写入WAL。HBase 集群中每台服务器维护一个WAL 来记录发生的变化。WAL 是底层文件系统上的一个文件。直到WAL 新记录成功写入后,写动作才被认为成功完成。这可以保证HBase 和支撑它的文件系统满足持久性。大多数情况下,HBase 使用Hadoop 分布式文件系统(HDFS)来作为底层文件系统。
如果HBase 服务器宕机,没有从MemStore 里刷写到HFile 的数据将可以通过回放WAL 来恢复。你不需要手工执行。Hbase 的内部机制中有恢复流程部分来处理。每台HBase 服务器有一个WAL,这台服务器上的所有表(和它们的列族)共享这个WAL。
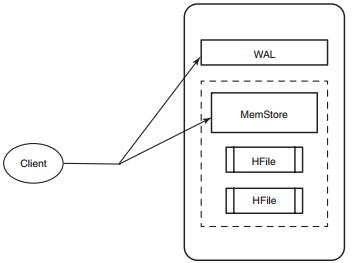
写操作会写入WAL和内存写缓冲区MemStore,客户端在写的过程中不与底层的HFile直接交互
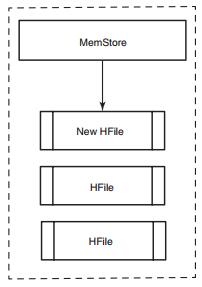
当MemStore写满时,会刷写到硬盘,生成一个新的HFile
你可能想到,写入时跳过WAL 应该会提升写性能。但我们不建议禁用WAL,除非你愿意在出问题时丢失数据。如果你想测试一下,如下代码可以禁用WAL:
Put p = new Put();
p.setWriteToWAL(false);
注意:不写入WAL 会在RegionServer 故障时增加丢失数据的风险。关闭WAL,出现故障时HBase 可能无法恢复数据,没有刷写到硬盘的所有写入数据都会丢失。
HBase 读路径工作机制
如果你想快速访问数据,通用的原则是数据保持有序并尽可能保存在内存里。HBase实现了这两个目标,大多情况下读操作可以做到毫秒级。HBase 读动作必须重新衔接持久化到硬盘上的HFile 和内存中MemStore 里的数据。HBase 在读操作上使用了LRU(最近最少使用算法)缓存技术。这种缓存也叫做BlockCache,和MemStore 在一个JVM 堆里。BlockCache 设计用来保存从HFile 里读入内存的频繁访问的数据,避免硬盘读。每个列族都有自己的BlockCache。
掌握BlockCache 是优化HBase 性能的一个重要部分。BlockCache 中的Block 是HBase从硬盘完成一次读取的数据单位。HFile 物理存放形式是一个Block 的序列外加这些Block的索引。这意味着,从HBase 里读取一个Block 需要先在索引上查找一次该Block 然后从硬盘读出。Block 是建立索引的最小数据单位,也是从硬盘读取的最小数据单位。Block大小按照列族设定,默认值是64 KB。根据使用场景你可能会调大或者调小该值。如果主要用于随机查询,你可能需要细粒度的Block 索引,小一点儿的Block 更好一些。Block变小会导致索引变大,进而消耗更多内存。如果你经常执行顺序扫描,一次读取多个Block,大一点儿的Block 更好一些。Block 变大意味着索引项变少,索引变小,因此节省内存。
从HBase 中读出一行,首先会检查MemStore 等待修改的队列,然后检查BlockCache看包含该行的Block 是否最近被访问过,最后访问硬盘上的对应HFile。HBase 内部做了很多事情,这里只是简单概括。读路径如图所示
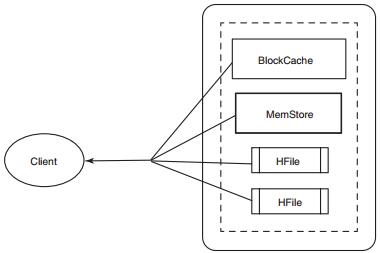
注意,HFile 存放某个时刻MemStore 刷写时的快照。一个完整行的数据可能存放在多个HFile 里。为了读出完整行,HBase 可能需要读取包含该行信息的所有HFile。
HBase读写路径的工作机制的更多相关文章
- Hbase读写流程和寻址机制
写操作流程 (1) Client通过Zookeeper的调度,向RegionServer发出写数据请求,在Region中写数据. (2) 数据被写入Region的MemStore,直到MemStore ...
- hadoop知识点总结(一)hadoop架构以及mapreduce工作机制
1,为什么需要hadoop 数据分析者面临的问题 数据日趋庞大,读写都出现性能瓶颈: 用户的应用和分析结果,对实时性和响应时间要求越来越高: 使用的模型越来越复杂,计算量指数级上升. 期待的解决方案 ...
- 深入分析 Java I/O 的工作机制--转载
Java 的 I/O 类库的基本架构 I/O 问题是任何编程语言都无法回避的问题,可以说 I/O 问题是整个人机交互的核心问题,因为 I/O 是机器获取和交换信息的主要渠道.在当今这个数据大爆炸时代, ...
- 深刻理解HDFS工作机制
深入理解一个技术的工作机制是灵活运用和快速解决问题的根本方法,也是唯一途径.对于HDFS来说除了要明白它的应用场景和用法以及通用分布式架构之外更重要的是理解关键步骤的原理和实现细节.在看这篇博文之前需 ...
- 深入分析 Java I/O 的工作机制
I/O 问题可以说是当今互联网 Web 应用中所面临的主要问题之一,因为当前在这个海量数据时代,数据在网络中随处流动.这个流动的过程中都涉及到 I/O 问题,可以说大部分 Web 应用系统的瓶颈都是 ...
- Hadoop的namenode的管理机制,工作机制和datanode的工作原理
HDFS前言: 1) 设计思想 分而治之:将大文件.大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析: 2)在大数据系统中作用: 为各类分布式运算框架(如:mapr ...
- [I/O]javaI/O工作机制
摘要:IO问题可以说是当今web应用中面临的主要问题之一.因为在这个数据爆发的时代,海量的数据在网络到处流动,而在这个过程中都会涉及IO问题,可以说IO问题已经成为web应用的瓶颈之一.如何优化?以此 ...
- Java I/O 工作机制(一) —— Java 的 I/O 类库的基本架构
Java 的 I/O 类库的基本架构 Java 的 I/O 操作类在包 java.io 下,有将近 80 个类. 按数据格式分类: 面向字节(Byte)操作的 I/O 接口:InputStream 和 ...
- Hadoop_09_HDFS 的 NameNode工作机制
理解NameNode的工作机制尤其是元数据管理机制,以增强对HDFS工作原理的理解,及培养hadoop集群运营中“性能调优” “NameNode”故障问题的分析解决能力 1.NameNode职责: H ...
随机推荐
- ES6转ES5:Gulp+Babel
目标: ES6代码转成ES5 对转换后的ES5进行压缩 以上步骤自动监控执行 步骤: 1.安装插件 在命令行中定位到项目根目录 安装全局 Gulp npm install -g gulp 安装项目中使 ...
- Reveal查看任意app的高级技巧(转)
原文:http://zhuanlan.zhihu.com/iOSRe/19646016 Reveal查看任意app的高级技巧 hangcom · 12 小时前 Reveal是一个很强大的UI分析工具, ...
- Android加载SO库UnsatisfiedLinkError错误的原因及解决方案
Android 应用开发者应该对 UnsatisfiedLinkError 这种类型的错误比较熟悉了,这个问题一直困扰着广大的开发者,那么有没有想过有可能你什么都没做错,也会出现这个问题呢? 我们在 ...
- Linux高级编程--07.进程间通信
每个进程各自有不同的用户地址空间,进程之间要交换数据必须通过在内核中开辟缓冲区,从而实现数据共享. 管道 管道是一种最基本的IPC机制,由pipe函数创建: int pipe(int filedes[ ...
- call方法和new对象的关系
call只能改变this的指向,而使用new对象不仅会自动调用call方法改变这个对象的this指向,而且还会继承构造函数的原型. var fn = function(a){ this.a = a; ...
- MongoDB 基础命令行
本文专门介绍MongoDB的命令行操作.其实,这些操作在MongoDB官网提供的Quick Reference上都有,但是英文的,为了方便,这里将其稍微整理下,方便查阅. 登录和退出 mongo命令直 ...
- 斜堆(一)之 C语言的实现
概要 本章介绍斜堆.和以往一样,本文会先对斜堆的理论知识进行简单介绍,然后给出C语言的实现.后续再分别给出C++和Java版本的实现:实现的语言虽不同,但是原理如出一辙,选择其中之一进行了解即可.若文 ...
- window xp Apache与Tomcat集群配置--转载
转载地址:http://www.cnblogs.com/obullxl/archive/2011/06/09/apache-tomcat-cluster-config.html 一. 环境说明 Win ...
- 远程方法调用(RMI)原理与示例
RMI介绍 远程方法调用(RMI)顾名思义是一台机器上的程序调用另一台机器上的方法.这样可以大致知道RMI是用来干什么的,但是这种理解还不太确切.RMI是Java支撑分布式系统的基石,例如著名的EJB ...
- IOS学习笔记之 Socket 编程
最近开始静心学习IOS编程,虽然起步有点晚,但有句话说的好:“如果想去做,任何时候都不晚”.所以在今天,开始好好学习IOS.(本人之前4年都是搞.Net的,java也培训过一年) 打算学IOS,从哪入 ...