Hadoop系列之(一):Hadoop单机部署
1. Hadoop介绍
Hadoop是一个能够对海量数据进行分布式处理的系统架构。
Hadoop框架的核心是:HDFS和MapReduce。
HDFS分布式文件系统为海量的数据提供了存储,
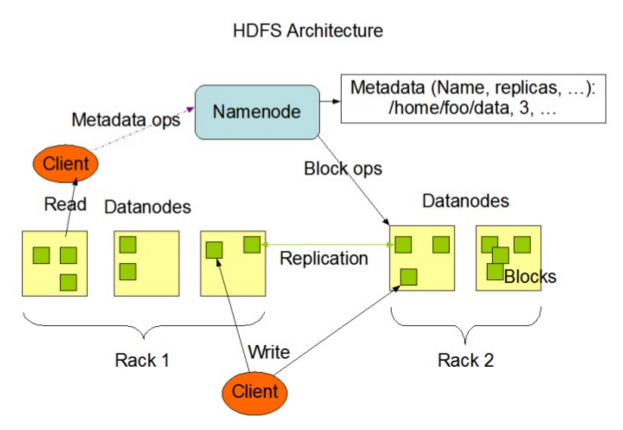
MapReduce分布式处理框架为海量的数据提供了计算。
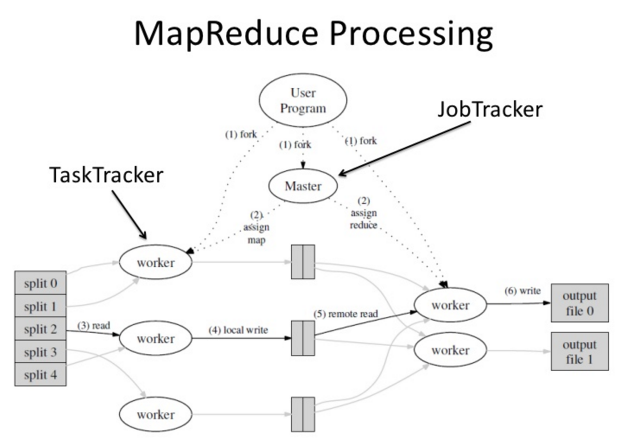
2. Hadoop安装
2.1 安装java
Hadoop是使用JAVA写的,所以需要先安装JAVA环境。
本次安装的是hadoop-2.7.0,需要JDK 7以上版本。
# yum install java-1.7.0-openjdk
# yum install java-1.7.0-openjdk-devel
安装后确认
# java –version

2.2 需要ssh和rsync
Linux系统一般都已经默认安装了,如果没有,yum安装。
2.3 下载Hadoop
从官网下载Hadoop最新版2.7.0
# wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz
将hadoop解压到/usr/local/下
# cd /usr/local/
# tar zxvf /root/hadoop-2.7.0.tar.gz
2.4 设置环境变量
设置JAVA的环境变量,JAVA_HOME是JDK的位置
# vi /etc/profile
export PATH=/usr/local/hadoop-2.7.0/bin:$PATH
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
让设置生效
# source /etc/profile
设置Hadoop的JAVA_HOME
# cd hadoop-2.7.0/
# vi etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
到此,Hadoop的安装就算完成了,接下来进行部署和使用。
3. 单机部署
Hadoop部署方式分三种,Standalone mode、Pseudo-Distributed mode、Cluster mode,其中前两种都是在单机部署。
3.1 standalone mode(本地单独模式)
这种模式,仅1个节点运行1个java进程,主要用于调试。
3.1.1 在Hadoop的安装目录下,创建input目录
# mkdir input
3.1.2 拷贝input文件到input目录下
# cp etc/hadoop/*.xml input
3.1.3 执行Hadoop job
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep input output 'dfs[a-z.]+'
上面的job是使用hadoop自带的样例,在input中统计含有dfs的字符串。
3.1.4 确认执行结果
# cat output/*

3.1.5 问题点
WARN io.ReadaheadPool: Failed readahead on ifile
EBADF: Bad file descriptor
如果出现上面的警告,是因为快速读取文件的时候,文件被关闭引起,也可能是其他bug导致,此处忽略。
3.2 pseudo-distributed mode(伪分布模式)
这种模式是,1个节点上运行,HDFS daemon的 NameNode 和 DataNode、YARN daemon的 ResourceManger 和 NodeManager,分别启动单独的java进程,主要用于调试。
3.2.1 修改设定文件
# vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
# vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3.2.2 设定本机的无密码ssh登陆
# ssh-keygen -t rsa
# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3.2.3 执行Hadoop job
MapReduce v2 叫做YARN,下面分别操作一下这两种job
3.2.4 执行MapReduce job
3.2.4.1 格式化文件系统
# hdfs namenode -format
3.2.4.2 启动名称节点和数据节点后台进程
# sbin/start-dfs.sh

在localhost启动一个1个NameNode和1个DataNode,在0.0.0.0启动第二个NameNode
3.2.4.3 确认
# jps

3.2.4.4 访问NameNode的web页面
http://localhost:50070/

3.2.4.5 创建HDFS
# hdfs dfs -mkdir /user
# hdfs dfs -mkdir /user/test
3.2.4.6 拷贝input文件到HDFS目录下
# hdfs dfs -put etc/hadoop /user/test/input
确认,查看
# hadoop fs -ls /user/test/input
3.2.4.7 执行Hadoop job
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep /user/test/input output 'dfs[a-z.]+'
3.2.4.8 确认执行结果
# hdfs dfs -cat output/*

或者从HDFS拷贝到本地查看
# bin/hdfs dfs -get output output
# cat output/*
3.2.4.9 停止daemon
# sbin/stop-dfs.sh
3.2.5 执行YARN job
MapReduce V2框架叫YARN
3.2.5.1 修改设定文件
# cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
# vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
# vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3.2.5.2 启动ResourceManger和NodeManager后台进程
# sbin/start-yarn.sh

3.2.5.3 确认
# jps

3.2.5.4 访问ResourceManger的web页面
http://localhost:8088/
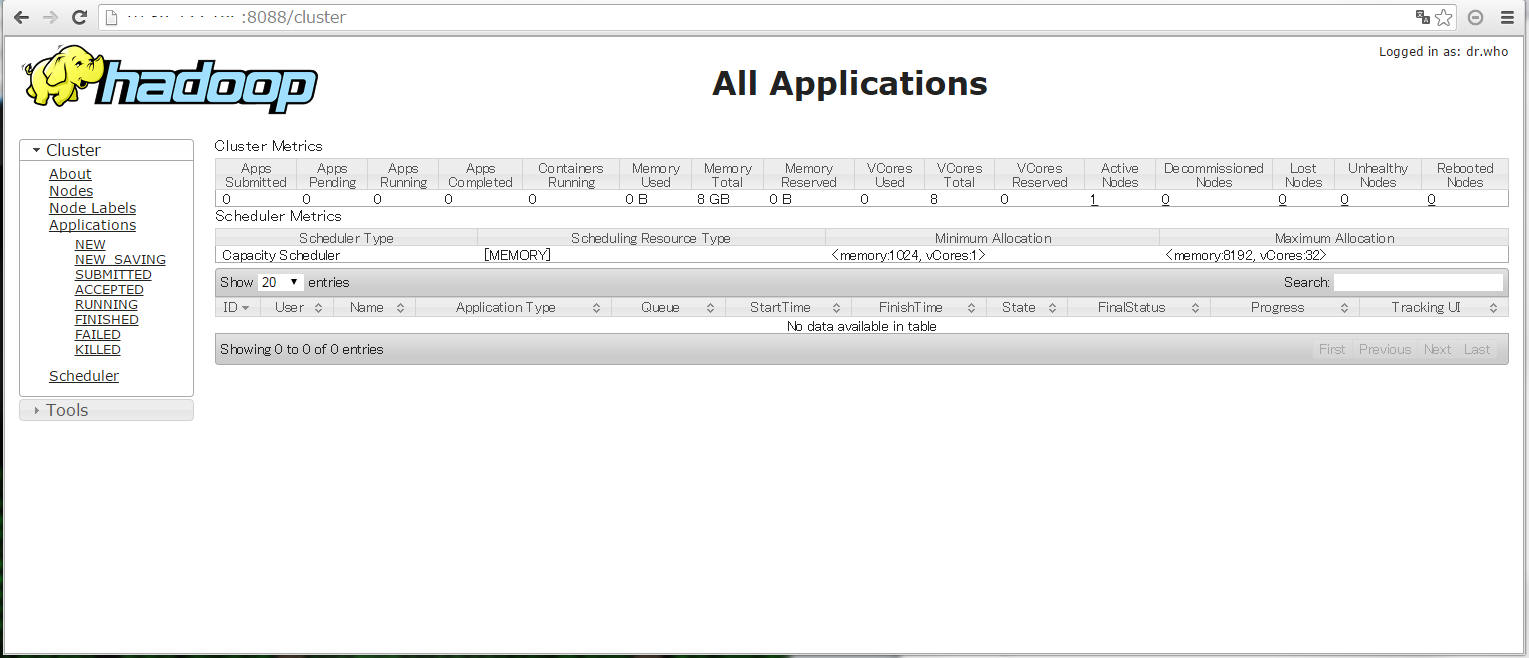
3.2.5.5 执行hadoop job
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep /user/test/input output 'dfs[a-z.]+'
3.2.5.6 确认执行结果
# hdfs dfs -cat output/*
执行结果和MapReduce job相同
3.2.5.7 停止daemon
# sbin/stop-yarn.sh
3.2.5.8 问题点
1. 单节点测试情况下,同样的input,时间上YARN比MapReduce好像慢很多,查看日志发现DataNode上GC发生频率较高,可能是测试用VM配置比较低有关。
2. 出现下面警告,是因为没有启动job history server
java.io.IOException: java.net.ConnectException: Call From test166/10.86.255.166 to 0.0.0.0:10020 failed on connection exception: java.net.ConnectException: Connection refused;
启动jobhistory daemon
# sbin/mr-jobhistory-daemon.sh start historyserver
确认
# jps

访问Job History Server的web页面
http://localhost:19888/

3. 出现下面警告,DataNode日志中有错误,重启服务后恢复
java.io.IOException: java.io.IOException: Unknown Job job_1451384977088_0005
3.3 启动/停止
也可以用下面的启动/停止命令,等同于start/stop-dfs.sh + start/stop-yarn.sh
# sbin/start-all.sh
# sbin/stop-all.sh
3.4 日志
日志在Hadoop安装路径下的logs目录下
4、后记
单机部署主要是为了调试用,生产环境上一般是集群部署,接下来会进行介绍。
Hadoop系列之(一):Hadoop单机部署的更多相关文章
- 啃掉Hadoop系列笔记(03)-Hadoop运行模式之本地模式
Hadoop的本地模式为Hadoop的默认模式,不需要启用单独进程,直接可以运行,测试和开发时使用. 在<啃掉Hadoop系列笔记(02)-Hadoop运行环境搭建>中若环境搭建成功,则直 ...
- Hadoop 系列文章(二) Hadoop配置部署启动HDFS及本地模式运行MapReduce
接着上一篇文章,继续我们 hadoop 的入门案例. 1. 修改 core-site.xml 文件 [bamboo@hadoop-senior hadoop-2.5.0]$ vim etc/hadoo ...
- hadoop系列一:hadoop集群安装
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6384393.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据 ...
- Hadoop 系列文章(一) Hadoop 的安装,以及 Standalone Operation 的启动模式测试
以前都是玩 java,没搞过 hadoop,所以以此系列文章来记录下学习过程 安装的文件版本.操作系统说明 centos-6.5-x86_64 [bamboo@hadoop-senior opt]$ ...
- 啃掉Hadoop系列笔记(01)-Hadoop框架的大数据生态
一.Hadoop是什么 1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构 2)主要解决,海量数据的存储和海量数据的分析计算问题. 3)广义上来说,HADOOP通常是指一个更广泛的概 ...
- Hadoop系列教程<一>---Hadoop是什么呢?
Hadoop适合应用于大数据存储和大数据分析的应用,适合于服务器几千台到几万台的集群运行,支持PB级的存储容量.Hadoop典型应用有:搜索.日志处理.推荐系统.数据分析.视频图像分析.数据保存等.但 ...
- 啃掉Hadoop系列笔记(04)-Hadoop运行模式之伪分布式模式
伪分布式模式等同于完全分布式,只是她只有一个节点. 一) HDFS上运行MapReduce 程序 (1)配置集群 (a)配置:hadoop-env.sh Linux系统中获取jdk的安装路径:
- 啃掉Hadoop系列笔记(02)-Hadoop运行环境搭建
一.新增一个普通用户bigdata
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
随机推荐
- Python入门版
一.前言 陆陆续续学习Python已经近半年时间了,感觉到Python的强大之外,也深刻体会到Python的艺术.哲学.曾经的约定,到现在才兑现,其中不乏有很多懈怠,狼狈. Python入门关于Pyt ...
- WPF后台设置xaml控件的样式System.Windows.Style
WPF后台设置xaml控件的样式System.Windows.Style 摘-自 :感谢 作者: IT小兵 http://3w.suchso.com/projecteac-tual/wpf-zhi ...
- 【Bootstrap基础学习】01 Bootstrap的CSS
Bootstrap 使用了一些 HTML5 元素和 CSS 属性,所以需要使用 HTML5 文档类型. <!DOCTYPE html> <html lang="zh-CN& ...
- 解决Cannot change version of project facet Dynamic Web M
dynamic web module 版本之间的区别: Servlet 3.0 December 2009 JavaEE 6, JavaSE 6 Pluggability, Ease of devel ...
- python,python3
当下主流的Linux发行版都集成了python2,直接在终端输入$python就可进入交互式解释器,或者输入$python3进入python3的解释器,当然,也可以使用这个解释器直接翻译一个pytho ...
- mysql内存消耗分析
最近有些生产服务器老是mysql内存不停得往上涨,开发人员和维护反馈,用了不少的临时表,问题时常线上发生,测试又一直比较难重现. 经观察mysql内存的os占用趋势,发现从8:40开始,mysql内存 ...
- Web.Config的配置
1.配置数据库连接 在<connectionStrings></connectionStrings>节中完成,配置过程需指定四个属性server(DataSource)服务器名 ...
- SAP debug的几种方式
1. 直接在程序中设断点 这种方式想必大家都知道了,在se38里面打上breakpoint,程序运行到该处即进入debug模式 2.background Job的debug 进入SM37 ...
- andriod 获取电池的信息
<?xml version="1.0"?> <LinearLayout android:orientation="vertical" andr ...
- JTS Geometry关系判断和分析
关系判断 Geometry之间的关系有如下几种: 相等(Equals): 几何形状拓扑上相等. 脱节(Disjoint): 几何形状没有共有的点. 相交(Intersects): 几何形状至少有一个共 ...